GPT-3概述
关于GPT-3的主要事实:
-
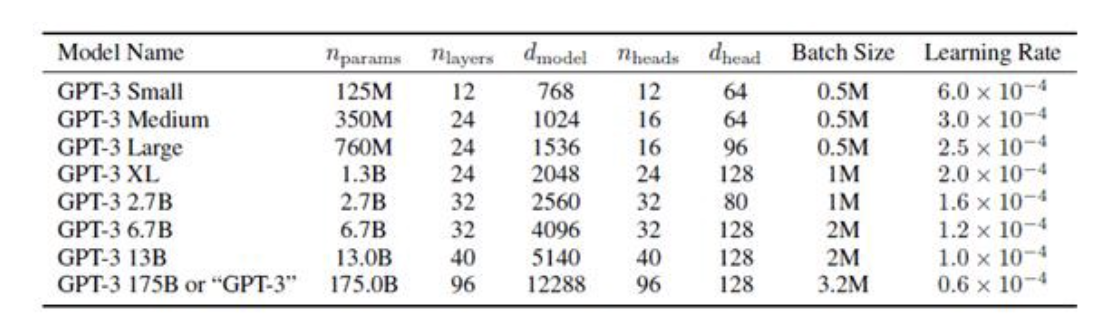
模型分类:GPT-3有8个不同的模型,参数从1.25亿到1750亿不等。
-
模型大小:最大的GPT-3模型有1750亿参数。这比最大的BERT模型大470倍(3.75亿个参数)
-
体系结构:GPT-3是一种自回归模型,使用仅有解码器的体系结构。使用下一个单词预测目标进行训练
-
学习方式:GPT-3通过很少的学习,学习时没有梯度更新
需要训练数据:GPT-3需要较少的训练数据。它可以从非常少的数据中学习,这使得它的应用程序可以用于数据较少的领域
关键假设:
- 模型规模的增加和对更大数据的训练可以导致性能的提高
- 单一模型可以在许多NLP任务上提供良好的性能。
- 模型可以从新数据中推断,不需要进行微调
- 该模型可以解决从未训练过的数据集上的问题。
早期的预训练模型-微调:
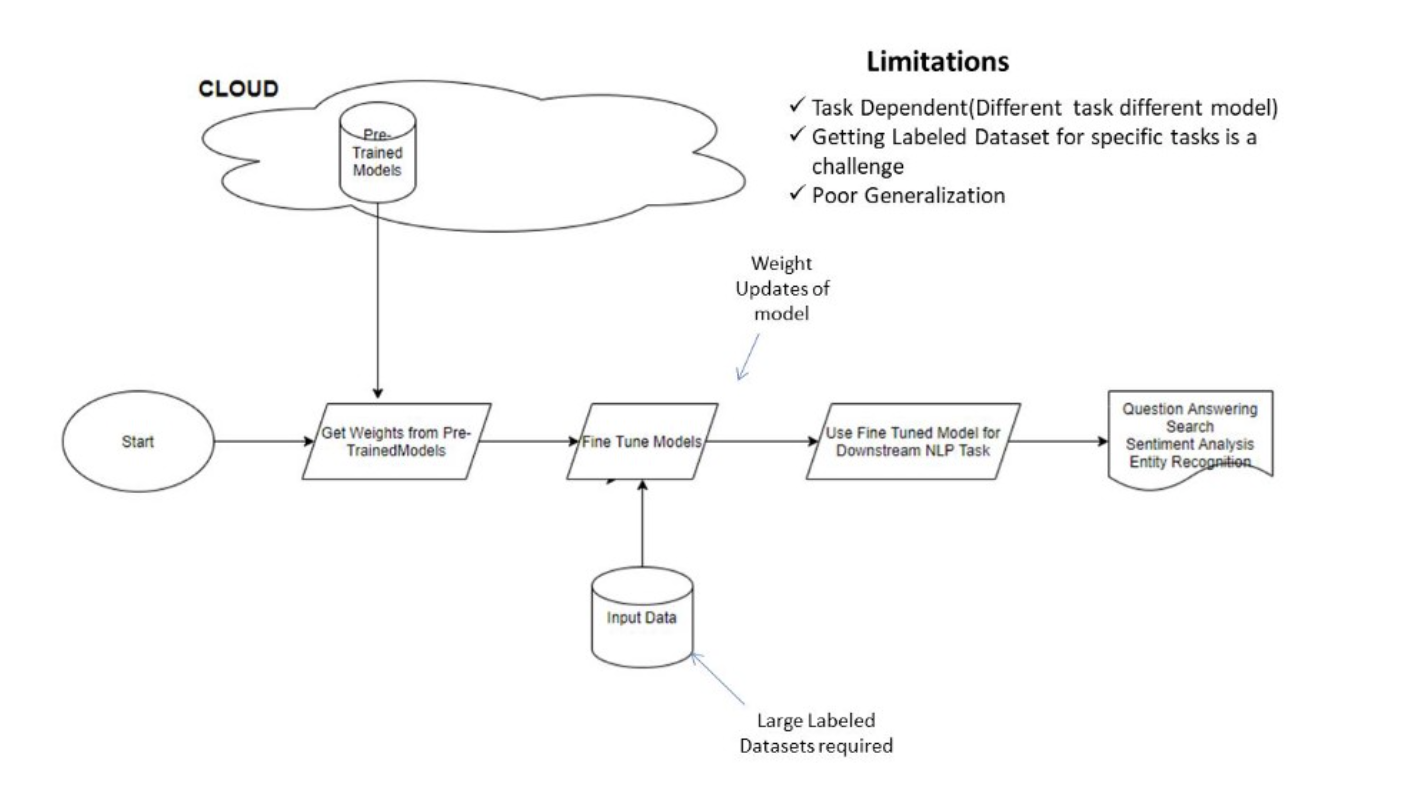
- GPT-3采用了不同的学习方法。不需要大量标记数据来推断新问题。
- 相反,它可以
不从数据(零次学习 Zero-Shot Learning )中学习,只从一个例子(一次学习 one-Shot Learning)或几个例子(few-Shot Learning)中学习。
与Bert进行对比:
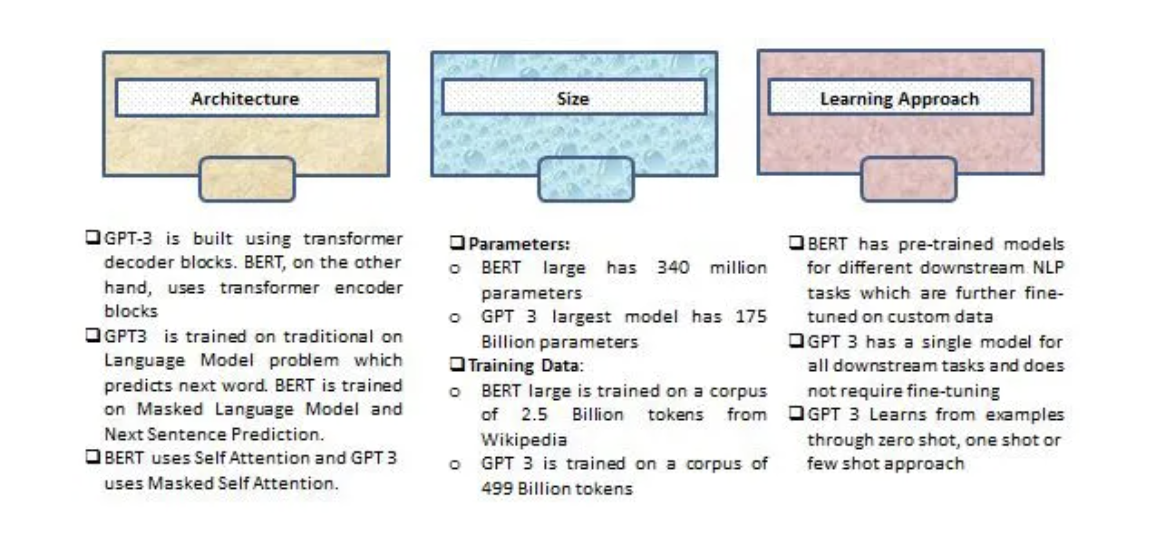
最显著的3个特征:
- Size:GPT-3的大小是其突出的特点。它几乎是最大的BERT模型的470倍
- Structure:在架构方面,BERT仍然处于领先地位。它是一种经过训练能够更好地捕捉不同问题语境下文本之间的潜在关系。,它是基于概率的,一个一个的输出
- Method:GPT-3学习方法相对简单,可以应用于很多没有足够数据的问题。因此,与BERT相比,GPT-3应该有更广泛的应用。
突破的两大功能:
- 文本生成
- 使用有限的数据构建NLP解决方案
各个任务的表现:
-
语言建模:GPT-3在纯语言建模任务上击败了所有的基准。
-
机器翻译:对于需要将文档转换成英语的翻译任务,该模型的性能优于基准测试。但是如果需要将语言从英语翻译为非英语,那么情况就不一样了,GPT-3的性能也会出现问题。
-
阅读理解:GPT 3模型的性能远远低于这里的技术水平。 -
自然语言推理:自然语言推理(NLI)关注理解两个句子之间的关系的能力。GPT 3模型在NLI任务中的表现很差 -
常识推理:常识推理数据集测试物理或科学推理技能的表现。GPT 3模型在这些任务上的表现很差
GPT3的问题
- GPT3是一个混合模型,可能在预训练的定制模型上性能会输掉
- 对模型偏差和可解释性的担忧:考虑到GPT-3的庞大规模,公司将很难解释该算法做出的决策
- 需要制定规章以防止滥用:如果没有得到适当的管制
图解详细理解
- 直接预测下一个单词,而不是根据上下文和掩码来预测
- 一次生成一个token,迭代生成
- 175亿参数
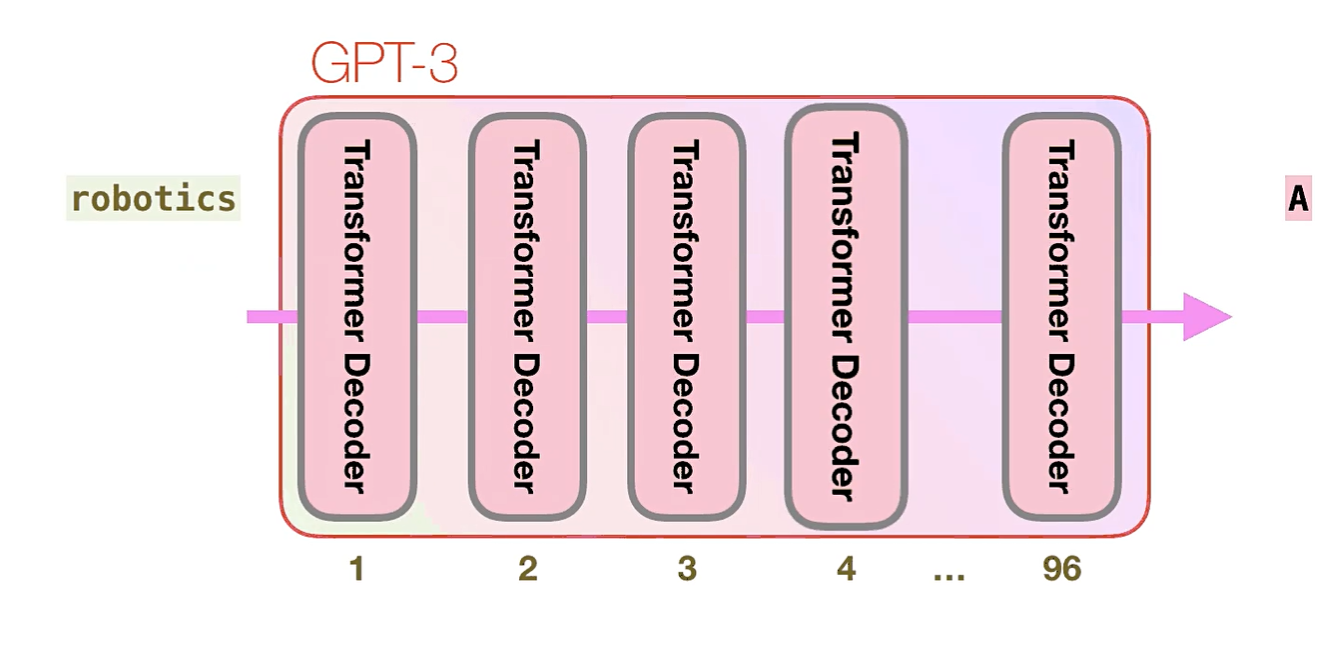
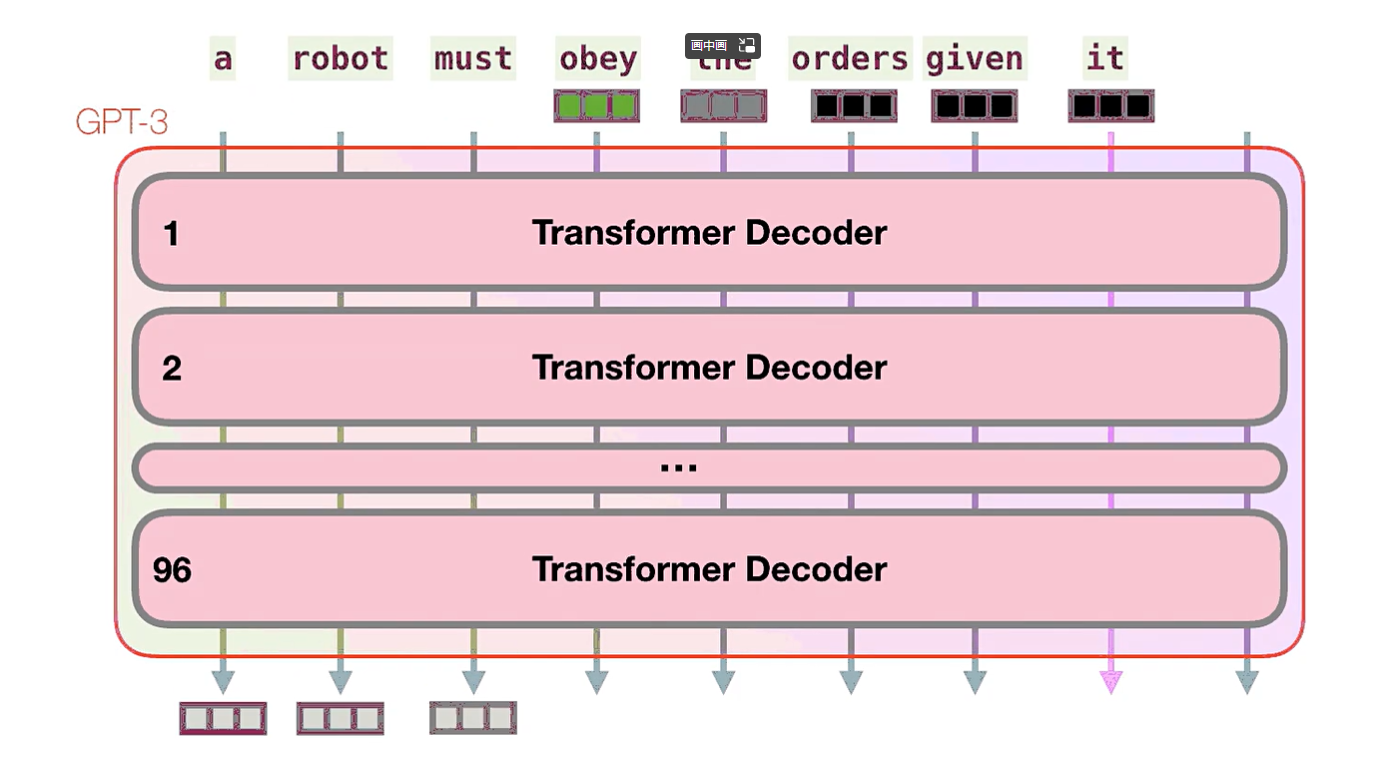
GPT3为2048个token。这就是它的“上下文窗口”。这意味着它有2048条轨道,沿着这些轨道处理token。

具体如何处理:
- 让我们跟随紫色的轨道。系统如何处理“robotics”一词并产生“ A”?
步骤:
- 将单词转换为代表单词的向量(数字列表)
- 计算预测
- 将结果向量转换为单词
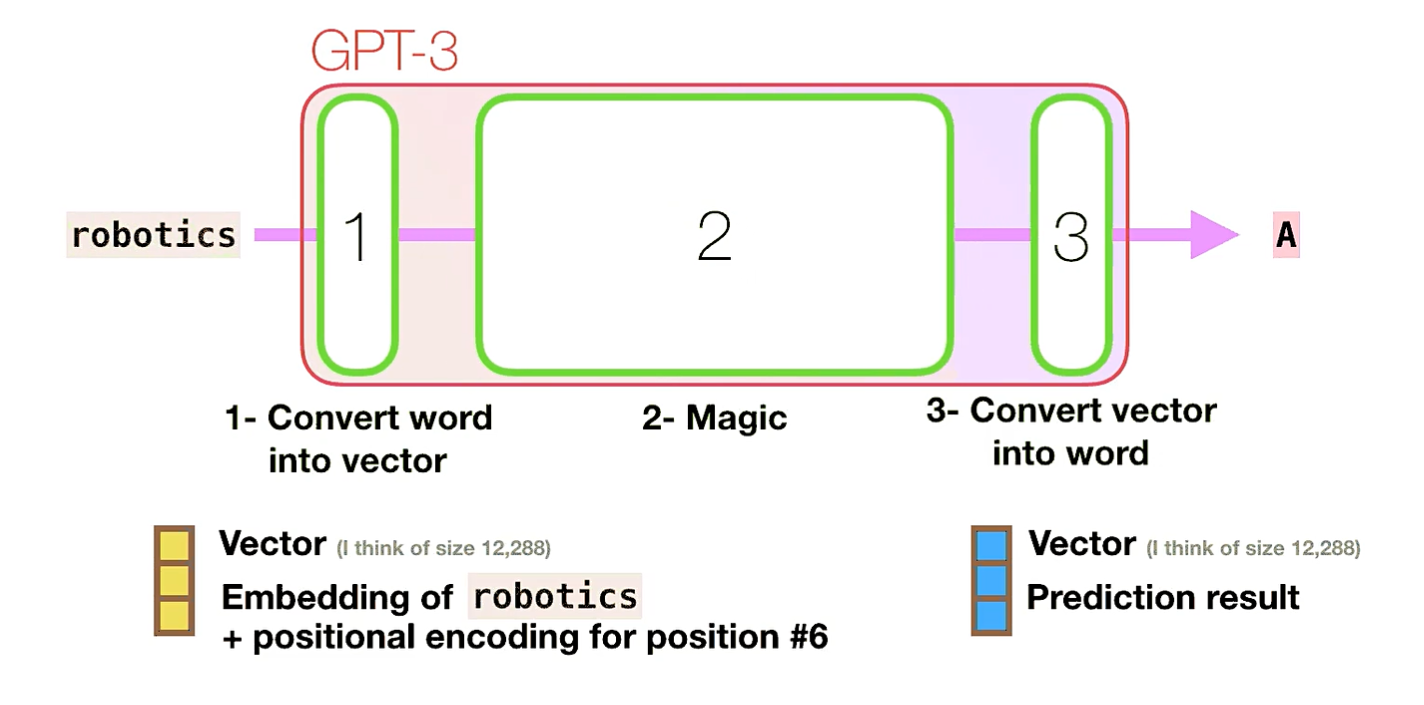
- GPT3的重要计算发生在其96个Transformer解码器层的堆栈内部。这些层中的每一层都有其自己的1.8B参数进行计算。那就是“魔术”发生的地方。这是该过程的高级视图:
论文精读
三大核心:Fine-Tuning、Few-Shot、One-Shot