简介
题目:Improving Language Understanding by Generative Pre-Training
翻译:改善语言理解通过生成式预训练
点击下载pdf
概要:
自然语言理解包含很多问题:文本蕴含、问答、语义相似度评估、文献分类。大量的无标签文本语料库是丰富的,打标签语料库是匮乏的,分别去训练模型很难有良好效果。该论文证明了:先使用无标签语料库进行生成式预训练,再针对不同任务做微调,这样效果很好。
介绍
从无标记文本中学习文本表征是有意义的,就像之前的词嵌入预训练一样。现有的预训练方法存在的问题是:模型需要根据任务调整、复杂的学习方法、需辅助目标函数。总结:麻烦。
本文探索一种半监督方法用于语言理解任务:无监督预训练+有监督微调。
目标是学习一种普遍的表征,只需要很少的改变就可用于宽泛范围的任务。
模型是Transformer,对比RNN,Transformer优点是可建立文本的长依赖关系,对不同任务更加鲁棒。
验证实验使用四种任务:自然语言推断、问答、语义相似、文本分类
无监督预训练
训练数据是无标签的语料token:
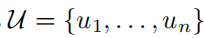
训练目标函数是最大化下面的式子

这里的目标可以理解为:根据前k个语料token,预测下一个token。
例如,给定U=“今天天气真好”,模型需要有如下预测能力:
给定句子“今”,下一个预测“天”
给定句子“今天”,下一个预测“天”
给定句子“今天天”,下一个预测“气”
给定句子“今天天气”,下一个预测“真“
给定句子“今天天气真”,下一个预测“好”
目标函数中的 θ \theta θ是模型的参数,所以这个式子就是找到最合适的 θ \theta θ,让 L 1 ( U ) L_{1}(U) L1(U)最大。训练方法是随机梯度下降。
模型选择的是多层Transformer解码器,
模型整体计算流程如下:
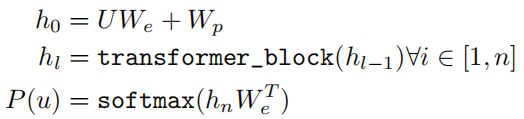
W e W_{e} We是token embedding,把词映射为向量的矩阵。
W p W_{p} Wp是position embedding,把位置映射为向量的矩阵。
有监督微调
使用有标签的数据集C,其中每个实例有序列输入tokens: x 1 , . . . , x m x^{1},...,x^{m} x1,...,xm,对应的标签y。 h l m h_{l}^{m} hlm是transformer_block最后一层的输出,额外增加一个新的线性层 W y W_{y} Wy,然后使用softmax分类得到最终结果。
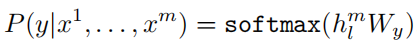
微调阶段的目标是最大化:
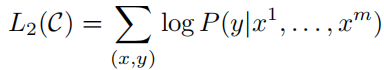
实际中发现使用混合类型的目标函数效果更好:(1)让模型进一步学习无监督预测的能力(2)帮助收敛
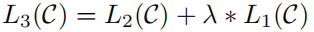
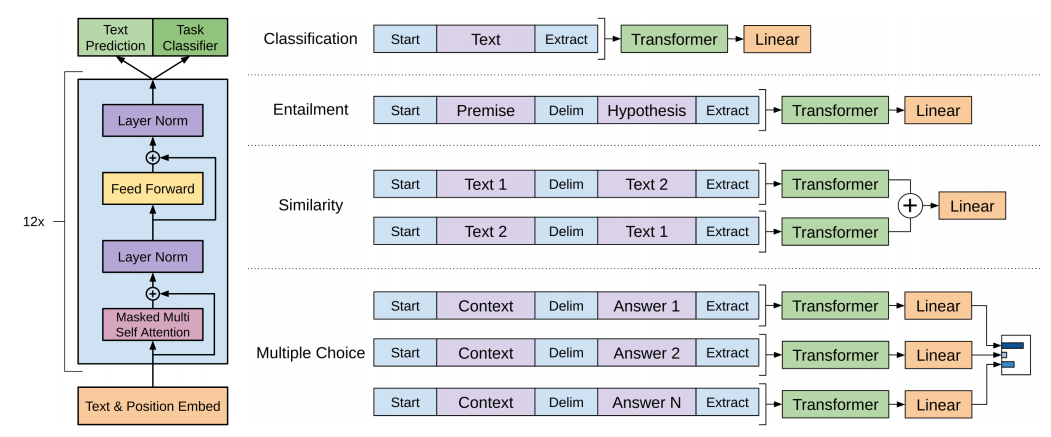
token设计如下图所示: