前言
Hadoop 2.3.0 版本新增了集中式缓存管理(Centralized Cache Management)功能,允许用户将一些文件和目录保存到HDFS缓存中。HDFS集中式缓存是由分布在 Datanode 上的堆外内存组成的,并且由Namenode 统一管理
添加集中式缓存功能的 HDFS 集群具有以下显著的优势。
- 阻止了频繁使用的数据从内存中清除。
- 因为集中式缓存是由 Namenode 统一管理的,所以 HDFS 客户端可以根据数据块的缓存情况调度任务,从而提高了数据块的读性能。
- 数据块被 Datanode 缓存后,客户端就可以使用一个新的更高效的零拷贝机制读取数据块。因为数据块被缓存时已经执行了校验操作,所以使用零拷贝读取数据块的客户端不会有读取开销。
- 可以提高集群的内存利用率。当 Datanode 使用操作系统的 buffer 缓存数据块时,对一个块的重复读会导致该块的 N个副本全部被送入操作系统的 buffer 中。而使用集中式缓存时,用户可以锁定这N个副本中的M个,从而节约了 N-M的内存。
本节首先介绍 HDFS 集中式缓存的概念、架构,然后介绍 Namenode 中负责管理缓存的组件 CacheManager 以及 CacheReplicationMonitor的实现.
缓存概念
HDFS 集中式缓存有两个主要概念。
-
缓存指令Cache Directive):一条缓存指令定义了一个要被缓存的路径(path)。这些路径可以是文件夹或文件。需要注意的是,文件夹的缓存是非递归的,只有在文件夹第一层列出的文件才会被缓存。文件夹也可以指定额外的参数,比如缓存副本因子(replication)、有效期等。缓存副本因子设置了路径的缓存副本数,如果多个缓存指令指向同一个文件,那么就用最大缓存副本因子。
-
缓存池(Cahce Pool:缓存池是一个管理单元,是管理缓存指令的组。缀存池拥有类似 UNIX 的权限,可以限制哪个用户和组可以访问该缓存池。缓存池也可以用于资源管理。它可以设置一个最大限制值,限制写入缓存池中指令的字节数。
缓存管理命令
HDFS 为管理员和用户提供了 “hdfs cacheadmin” 命令管理集中式缓存,包括缓存指令控制和缓存池控制两个部分。
-
缓存指令控制:管理员可以调用
hafs cacheadmin -addDirective命令缓存指定路径:调用hdfs cacheadmin -removeDirective命令删除指定 id 对应的缓存;调用hdfs cacheadmin -removeDirectives命令删除指定路径的缓存:调用hdfs cacheadmin -listDirectives命令显示当前所有的缓存。由于篇幅原因,这里就不列出所有命令的参数了。 -
缓存池控制:管理员可以调用
hdfs cacheadmin -addPool命令创建一个缓存池;调用hdfs cacheadmin -modifyPool命令修改一个缓存池的配置:调用hdfs cacheadmin -removePool命令删除一个缓存池。
HDFS 集中式缓存架构
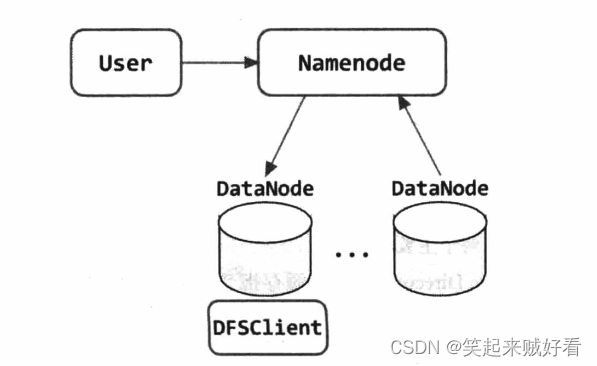
如图所示,用户可以通过 hdfs cacheadmin 命令或者 HDFS API 向 Namenode 发送缓存指令(Cache Directive), Namenode 的 CacheManager 类会将缓存指令保存到内存的指定数据结构(CacheManager 的 directivesByld、 directivesByPath 字段)中,同时在 fsimage 和 editlog 文件中记录该绶存指令。之后 Namenode 的 CacheReplicationMonitor 类会周期性扫描命名空间和活跃的缓存指令,以确定需要缓存或删除缓存的数据块,并向 Datanode 分配缓存任务。
Namenode 还负贵管理集群中所有 Datanode 的堆外缓存,Datanode 会周期性向 Namenode 发送缓存报告,而 Namenode 会通过心跳响应向 Datanode 下发缓存指令(添加缓存或者删除缓存)。
DFSClient 读取数据块时会向 Namenode 发送 ClientProtocol.getBlockLocations 请求获取数据块的位置信息,Namenode 除了返回数据块的位置信息外,还会返回该数据块的缓存信息, 这样 DFSClient 就可以执行本地零拷贝读取缓存数据块了,从而提高了读取效率。
CacheManager 类实现
CacheManager 类是 Namenode 管理集中式缓存的核心组件,它管理着分布在 HDFS 集群中 Datanode 上的所有缓存数据块,同时负责响应 hdfs cacheadmin 命令或者 HDFS API发送的缓存管理命令(请参考缓存管理命令小节)。
CacheManager 定义了以下字段。
directivesByld: 以缓存指令id为 key,保存所有的缓存指令。direetivesByPath:以路径为 key,保存所有的缓存指令。cachePools:以缓存池名称为 key,保存所有的缓存池。monitor:CacheReplicationMonitor对象,负责扫描命名空间和活跃的缓存指令,以确定需要缓存或删除缓存的数据块,并向 Datanode 分配缓存任务。
客户端会调用 ClientProtocol.addCachePool() 方法创建一个缓存池,NameNodeRpcServer 接收了这个请求后,会将创建缓存池请求的参数封装到一个 CachePoollnfo 对象中(包括 owner、 group、 mode、 limit、 max Ttl 等参数),然后调用 CacheManager.addCachePool() 方法响应这个请求。CacheManager.addCachePool() 方法首先会验证请求参数(info 变量保存)是否合法,然后检查 CacheManager.cachePools 集合中是否已己经保存了这个缓存池。如果 CacheManager 中没有这个缓存池的信息,则调用 CachePool.ereate FromlnfoAndDefaults() 方法根据请求参数创建一个新的 CachePool 对象。createFromlnfoAndDefaults() 方法会将请求中没有设置的参数用默认值补齐,然后构造 CachePool 对象。成功创建 CachePool 对象后,addCachePool() 方法会将 CachePool 对象放入 cachePools 字段中保存。至此,添加缓存池的操作完成。
CacheManager.addCachePool() 方法的代码如下:
成功地创建了缓存池之后,客户端就会调用 ClientProtocol.adaCacheDirective() 方法将一个路径添加到缓存中。NameNodeRpeServer 接收了这个请求后,会将创建缓存请求的参数封装到一个 CacheDirectivelnfo 对象中,然后调用 CacheManager.addlnternal() 方法响应这个请求。
如下代码所示,CacheManager.addinternal() 会将缓存指令对象加入 directivesByld 以及 directivesByPath 集合中保存,然后更新缓存池的统计信息。之后 addinternal() 方法会调用 setNeedsRescan() 方法触发 CacheReplicationMonitor 执行 rescan() 操作。
可以看到,addInternal() 方法只是更新了 Cache Manager 的 directivesByld、 directivesByPath 以及 cachePools 等字段维护的缓存信息,之后并没有对 Datanode 下发任何缓存指令(添加、 删除缓存),而是调用 setNeedsRescan 方法触发 CacheReplicationMonitor 执行绶存操作。我们在下一节介绍 CacheReplicationMonitor 的实现。
CacheReplicationMonitor
CacheReplicationMonitor 是一个线程类,它会在 Namenode 启动时以及以固定的间隔扫描命名空间和活跃的缓存指令,以确定需要缓存或删除缓存的数据块,之后向 Datanode 下发缓存指令(这里的间隔是由 dfs.namenode.path.based.cache.refresh.interval.ms 配置项配置的,默认为30秒)。
CacheReplicationMonitor 会循环调用 rescan() 方法执行扫描逻辑,rescan() 方法的代码如下所示,它会调用 rescanCacheDirectives() 方法遍历所有的缓存指令(存储在 CacheManager.
directivesByPath 字段中),并将绶存指令路径中包含的数据块加入到 CacheReplicationMonitor.
cachedBlocks 集合中等待进一步操作。之后 rescan() 方法会调用 rescanCachedBlockMap() 遍历 CacheReplicationMonitor.cachedBlocks 集合,判断这些数据块是执行 cache 操作还是 uncache 操作。对于需要执行 cache 操作的数据块,rescanCachedBlockMap() 会调用CacheReplicationMonitor.addNewPendingCached() 方法为每个等待 cache 的数据块选择一个合适的 Datanode(从保存了该数据块副本的所有 Datanode 中挑选一个可用内存最多的),之后将该数据块加入该 Datanode 对应的 DatanodeDescriptor 对象的 pendingCached 列表中。而对于需要执行 uncache 操作的数据块,rescanCachedBlockMap() 会调用 CacheReplicationMonitor.
addNewPendingUncached() 方法从缓存了该数据块的 Datanode 中随机选出一个节点执行 uncache 操作,也就是将数据块加入该 Datanode 对应的 DatanodeDescriptor 对象的 pendingUncached 列表中。
将数据块加入 DatanodeDescriptor 的 pendingCached 和 pendingUncached 列表中后, Namenode 就会在心跳处理流程中生成名字节点指令(请参考数据节点管理的名字节点指令生成小节),并通过心跳响应发送给 Datanode。Datanode 接受指令之后,会执行缓存以及删除缓存操作(请参考第4 章的 FSDatasetlmpl 小节)。至此,Namenode 端处理缓存数据块的逻辑就结束了。DFSClient 通过零拷贝模式读取缓存数据块的实现,请读者参考第5章的零拷贝读取相关小节。
本文内容结合自 《Hadoop 2.X HDFS 源码剖析》以及自己的理解
希望对正在查看文章的您有所帮助,记得关注、评论、收藏,谢谢您