DataStorage的实现原理
前言
Datanode 最重要的功能就是管理磁盘上存储的 HDFS 数据块。Datanode 将这个管理功能切分为两个部分:①管理与组织磁盘存储目录(由 dfs.data.dir 指定),如 current、 previous、 detach、 tmp 等,这个功能由 DataStorage 类实现;② 管理与组织数据块及其元数据文件,这个功能主要由 FsDatasetlmpl 相关类实现。本节介绍 DataStorage 类的实现。
Storage类继承关系
Data Storage 的父类为 Storage,如下图 给出了 Storage 类的继承关系。Storagelnfo 为根接口,描述存储的基本信息。子类 Storage 是抽象类,它为 Datanode、 Namenode 提供抽象的存储服务。
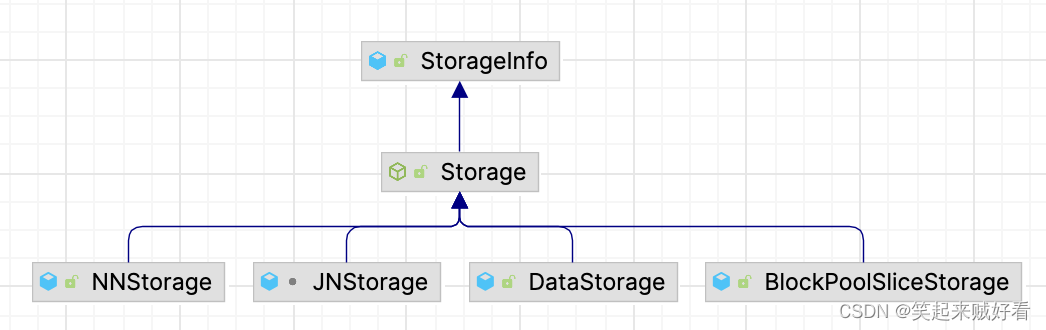
一个 Storage 可以定义多个存储目录,存储目录由 Storage 的内部类 StorageDirectory 描述, StorageDirectory 类定义了存储目录上的通用操作。这里我们以 Datanode 的配置为例,Datanode 可以定义多个存储目录保存数据块,如下配置所示,Datanode 定义了两个数据存储目录,即 /data/hdfs/dfs/data ” 和 “ /data/hdfs/afs/data2”。HDFS 会使用一个 Data Storage 对象管理整个 Datanode 的存储,而这两个存储目录则由两个 StorageDirectory 对象管理。
<property>
<name>dfs.data.dir</name>
<value>[DISK]/data/hdfs/data_1,[SSD]/data/hdfs/data_2</value>
</property>
由于Federation联邦机制,Datanode会管理多个块池。HDFS 定义了 BlockPoolSliceStorage 类来管理 Datanode 上的一个块池,这个块池分布在 Datanode 配置的所有存储目录中。DataStorage 类会持有所有 BlockPoolSliceStorage 对象的引用,并通过这些引用管理 Datanode 上的所有块池。
StorageInfo
Storagelnfo 用于描述存储的基本信息,这个类有以下5个字段。
- layout Version:存储系统布局版本号,当节点存储的目录结构发生改变或者 fsimage 和 editlog 的格式发生改变时,存储系统布局版本号会更新。这个版本号一般是负数。
- namespacelD:存储系统命名空间标识。
- cTime:存储系统创建时间。
- clusterID:存储系统的集群 ID。
- storageType:节点类型,有 DATA NODE、 NAME NODE、 JOURNAL NODE 等类型。
这里要注意,Storagelnfo中定义的信息都存储在存储目录的 VERSION 文件中,一个 VERSION 文件就是一个典型的 Java Properties(属性)文件,除了上述5个属性外,不同类型节点的 VERSION 文件还存储了其他特有的属性。
Storagelnfo 的方法大多是 get/set 方法,以及从 Properties 文件中读取属性然后赋值字段的方泆,比较简单,这里就不再赘述了
Storage.StorageState
Storage 类定义了一个非常重要的内部枚举类—StorageState,这个枚举类完整地定义了存储空间可能出现的所有状态。在升级、回滚、升级提交、检查点等操作中,节点 (Datanode 或者 Namenode)的存储空间可能出现各种异常,例如误操作、断电、宕机等情况,这个时候存储空间就可能处于某种中间状态,引入中间状态,有利于 HDFS 从错误中恢复过来。对于存储状态的确定,是在 StorageDireetory.analyseStorage0) 方法中进行的,我们在下一节 StorageDirectory 中介绍这个方法。

public enum StorageState {
NON_EXISTENT, // 存储不存在
NOT_FORMATTED, // 存储未格式化
COMPLETE_UPGRADE, // 完成升级
RECOVER_UPGRADE, // 恢复升级
COMPLETE_FINALIZE, // 完成升级提交
COMPLETE_ROLLBACK, // 完成回滚操作
RECOVER_ROLLBACK, // 恢复回滚
COMPLETE_CHECKPOINT, // 完成检查点操作
RECOVER_CHECKPOINT, // 恢复检查点操作
NORMAL; // 正常状态
}
这里要特别注意,Storage 状态还与启动选项有关,这些选项的存储在 HdfsServerConstants 类中,代码如下:
enum StartupOption{
FORMAT ("-format"), // 格式化操作
CLUSTERID ("-clusterid"), // 获取集群ID
GENCLUSTERID ("-genclusterid"), // 生成集群ID
REGULAR ("-regular"), // 正常启动
BACKUP ("-backup"), // 备份
CHECKPOINT("-checkpoint"), //
UPGRADE ("-upgrade"), // 升级
ROLLBACK("-rollback"), // 回滚
ROLLINGUPGRADE("-rollingUpgrade"), // 滚动升级
IMPORT ("-importCheckpoint"), //
BOOTSTRAPSTANDBY("-bootstrapStandby"),
INITIALIZESHAREDEDITS("-initializeSharedEdits"),
RECOVER ("-recover"),
FORCE("-force"),
NONINTERACTIVE("-nonInteractive"),
SKIPSHAREDEDITSCHECK("-skipSharedEditsCheck"),
RENAMERESERVED("-renameReserved"),
METADATAVERSION("-metadataVersion"),
UPGRADEONLY("-upgradeOnly"),
// The -hotswap constant should not be used as a startup option, it is
// only used for StorageDirectory.analyzeStorage() in hot swap drive scenario.
// TODO refactor StorageDirectory.analyzeStorage() so that we can do away with
// this in StartupOption.
HOTSWAP("-hotswap"),
// Startup the namenode in observer mode.
OBSERVER("-observer");
// ...
}
Storage.StorageDirectory
我们知道 Datanode 和 Namenode 都可以定义多个存储目录来存储数据,StorageDirectory 是 Storage 的内部类,定义了管理存储目录的通用方法。
- root:存储目录的根,就是 java.io.File 文件。
- dirType:当前存储目录的类型。
- isShared:指示当前目录是否是共享的。例如在 HA 部署中,不同的 Namenode 之间共享存储目录,或者在 Federation 部署中不同的块池之间共享存储目录。
- lock:独占锁,java.nio.FileLock 类型,用来支持 Datanode 或者 Namenode 线程独占存储目录的锁操作。
- storageUuid:存储目录的标识符。
StorageDirectory 的方法主要分为三类:获取文件夹相关操作、加锁/解锁操作、存储状态恢复操作。下面我们依次看一下这三种类型方法的实现。
文件夹操作
获取当前存储目录结构中的各个文件/文件夹的方法,在 HDFS 升级过程中涉及的所有目录都可以通过 StorageDirectory 提供的方法获得:

- getCurrentDir() —— 获取 current目录。
- getVersionFile() —— 获取 current 目录下的 VERSION 文件。
- getPreviousDir() —— 获取 previous 目录。
- getPrevious VersionFile() —— 获取 previous 目录下的 VERSION 文件。
- getPreviousTmp() —— 获取 previous.tmp 目录。
- getRemovedTmp() —— 获取 removed.tmp 目录。
- getFinalizedTmp() —— 获取 finalized.tmp 文件。
- getLastCheckpointTmp() —— 获取 lastcheckpoint.tmp 文件。
- getPreviousCheckpoint() —— 获取 previous.checkpoint 文件。
加锁/解锁操作
在 Datanode 磁盘存储结构小节中,我们介绍了存储目录下会有一个 in_use.lock 文件,j 个文件用于对当前存储目录加锁,以保证 Datanode 进程对存储目录的独占使用。当 Datanode进程退出执行时,in_use.lock 文件会被删除。StorageDirectory 提供了 tryLock0与 unlock0两个锁方法,分别实现了对存储目录加锁以及解锁的功能。
StorageDirectory 中真正进行加锁操作的是 tryLockO方法。tryLockO方法会首先构造锁文件,然后调用 file.getChannel.lockO方法尝试获得存储目录的独占锁,如果已经有进程占有锁文件,那么 file.getChannel.lock(就会返回一个 null 的引用,表明有另一个节点运行在当前的存储目录上,tryLockO方法会抛出异常并退出执行。如果加锁成功,tryLockO方法会在锁文件中写入虚拟机信息。
存储状态恢复操作
Datanode 在执行升级、回滚、提交操作的过程中会出现各种异常,例如误操作、断电、 宕机等情况。那么 Datanode 在重启时该如何恢复上一次中断的操作呢?StorageDirectory 提供了 doRecover()和 analyzeStorage(两个方法,Datanode 会首先调用 analyzeStorage(方法分析当前节点的存储状态,然后根据分析所得的存储状态调用 doRecover(方法执行恢复操作。
Storage
Storage 是一个抽象类,为 Datanode、 Namenode 提供抽象的存储服务。Storage 类管理着当前节点上(可以是 Datanode 或者 Namenode)所有的存储目录,每个存储目录都由一个 StorageDirectory 对象管理,Storage 用一个线性表字段 storageDirs 存储它管理的所有 StorageDirectorv,并通过 Dirlterator 迭代器进行遍历。
DataStorage
DataStorage 继承自 Storage 抽象类,提供了管理 Datanode 存储空间的功能。本节介绍 DataStorage 类的实现。
在 HDFSFederation 架构中,一个 Datanode 可以保存多个命名空间的数据块,每个命名空间在 Datanode 磁盘上都拥有一个独立的块池(BlockPool),这个块池会分布在 Datanode 的所有存储目录下,它们共同保存了这个块池在当前 Datanode 上的所有数据块。HDFS 定义了 BlockPoolSliceStorage 类管理 Datanode 上单个块池的存储空间 (BlockPoolSliceStorage 的实现我们在下一节中介绍),DataStorage 类则定义了 bpStorageMap 字段保存 Datanode 上所有块池 BlockPoolSliceStorage 对象的引用。如下代码所示,bpStorageMap 字段是 Map 类型的,维护了 bpld->BlockPoolSliceStorage 的映射关系。
private final Map<String, BlockPoolSlicestorage> bpstorageMap = Collections.synchronizedMap (new HashMap<String, BlockPoolSlicestorage>());
Datanode 在启动时会调用 DataStorage 提供的方法初始化 Datanode 的存储空间,在 HDFS Federation 架构中,Datanode 会保存多个命名空间的数据块。对于每一个命名空间,Datanode 都会构造一个 BPOfferService 类维护与这个命名空间 Namenode 的通信(请参考文件系统数据集的 BlockManager 节的 BPOfferService 小节)。如图 4-15 所示,当 BPOfferService 中的 BPServiceActor 类与该命名空间的 Namenode 握手成功后,就会调用 DataNode.initBlockPool( 初始化该命名空间的块池。DataNode.initBlockPool0 方法最终会调用 DataStorage.recoverTransitionRead() 来执行块池存储的初始化操作。
希望对正在查看文章的您有所帮助,记得关注、评论、收藏,谢谢您