在NameNode中的Namespace管理层是负责管理整个HDFS集群文件系统的目录树以及文件与数据块的映射关系。以下就是Namespace的内存结构:
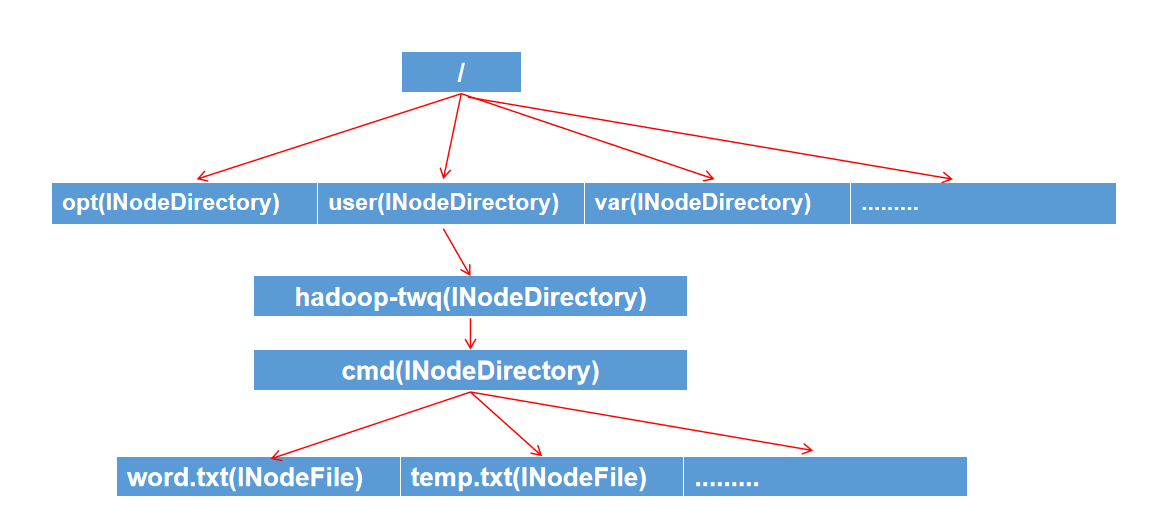
以上是一棵文件目录树,可见Namespace本身其实是一棵巨大的树。在这棵树中INodeFile表示文件,INodeDirectory表示文件目录。在HDFS中的实现中,INodeFile和INodeDirectory都是继承INode的,以下是INode的继承关系:
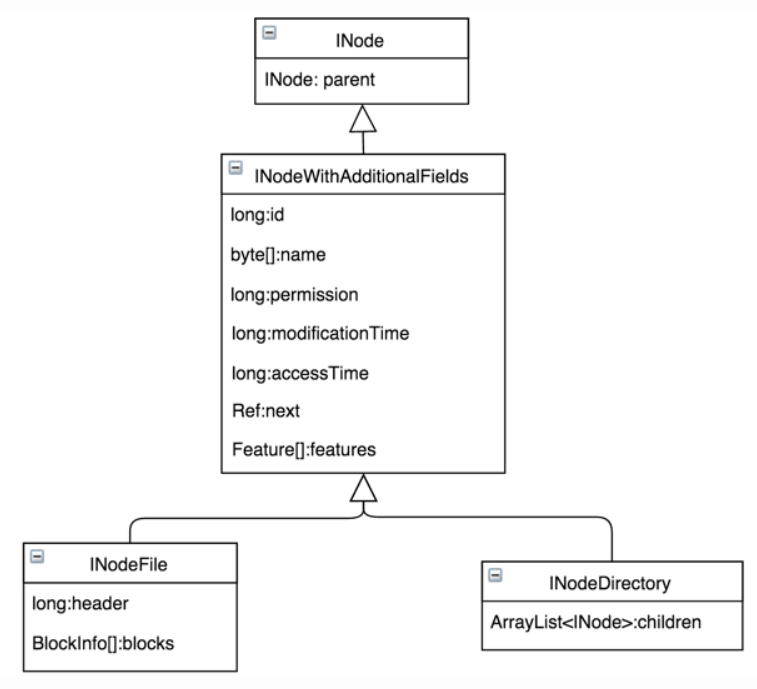
目录树数据结构详细解释
- INode
INode是INodeFile和INodeDirectory父类,有一个关键的属性,就是parent,这个表示当前的INode的父亲INode,每一个文件或者文件目录都会记录它的父亲节点,这样根据这个父子关系就可以构建出一个文件目录树。这个目录树的根节点是/
- INodeWithAdditionalFields
这个类中包含了文件和目录的共同的属性,比如:唯一标识id、INode名称、权限、修改时间、访问时间等基础信息。除常用基础属性外,其中还提供了扩展属性features,如Quota、Snapshot等均通过Feature增加,如果以后出现新属性也可通过Feature方便扩展
- INodeFile
INodeFile表示一个文件,除了继承INode和INodeWithAdditionalFields中的属性外,还有两个文件特殊的属性:
- header:标识存储策略ID、副本数和数据块大小的信息
- blocks:该文件包含的数据块数组
- INodeDirectory
INodeDirectory则持有子节点的列表children。这里需要特别说明children是默认大小为5的ArrayList,按照子节点name有序存储,虽然在插入时会损失一部分写性能,但是可以方便后续快速二分查找提高读性能,对一般存储系统,读操作比写操作占比要高
Namespace内存估算
Namespace管理的文件目录树是存储在NameNode的内存中的,这样是为了提高访问速度。那么我们怎么样来估算Namespace管理的文件目录树占多大内存呢?我们下面从几个关键数据结构所占的内存来估算。
目录和文件结构在继承关系中各属性的内存占用情况如下表所示:

除图中提到的属性信息外,一些附加如ACL等非通用属性,没有在统计范围内
如果你对Java对象所占内存大小不甚了解的话,请参考:Java对象所占内存的大小
以上每个对象所占内存的大小的估算是在64位操作系统上且没有开启指针压缩功能场景下
根据前面的分析,假设HDFS目录和文件数分别为1亿,Block总量在1亿情况下,整个Namespace在JVM中内存使用情况:
- Total(Directory) = (8 + 72 + 80) ∗ 100M + 8 ∗ num(total children)
- Total(Files) = (8 + 72 + 56) ∗ 100M + 8 ∗ num(total blocks)
- 内存总大小是:Total(Directory) + Total(Files)
上面为什么是乘以100M呢? 因为100M = 100 * 1024 * 1024 bytes = 104857600 bytes,约等于1亿字节,而上面的内存的单位都是字节的,我们乘以100M,就相当于1亿个目录或者1亿个文件了
从整个目录树的父子关系上看,num(total children)就是目录节点数和文件节点数之和。num(total blocks)是1亿。所以上面的场景的Namespace占用的总内存是: Total(Directory) + Total(Files) = (8 + 72 + 80) ∗ 100M + 8 * 200M + (8 + 72 + 56) ∗ 100M + 8 * 100M = 31.25G
Namespace在JVM堆内存空间中常驻,在NameNode的整个生命周期一直在内存存在,同时为保证数据的可靠性,NameNode会定期对其进行Checkpoint,将Namespace物化到外部存储设备(也就是FSImage和EditsLog机制了)。随着数据规模的增加,文件数/目录树也会随之增加,整个Namespace所占用的JVM内存空间也会基本保持线性同步增加。