收藏关注不迷路
文章目录
前言
经过多年的发展,网络视频已经成为互联网上的主要应用之一。目前,网络视频具有数量大、发布快、影响多、影响力大的特点。Bilili Barrage Video Network(简称B站)作为当下国内首屈一指的弹幕视频网站。对全平台的视频调查可知,B站用户创作的视频数量所占比例高达85%。而对于其中的视频创作者而言,如何在互联网繁杂的数据海洋中,进一步分析和研究热点视频则成为了研究的难题所在。本文的数据取自2020年8月的B站,其主要涉及有关生活版块的热点视频数据,并选取了大量热点词、评论等数据进行分析和研究,并最终实现了数据的可视化研究,不仅可以了解这段时间网络舆情的总体趋势,掌握用户的心理态度,加强受众的互动反馈,还可以激发用户对于B站文化探索的兴趣。
关键词 哔哩哔哩;用户行为分析;热点视频;
一、模块设计
本平台的结构如图 2 所示:

图2 平台结构图
3.1数据爬取模块
用python进行数据挖掘的过程中,主要是通过爬虫程序和数据的预处理来收集相应的用户数据信息。网络爬虫的实现往往是利用用户在视频上传过程中使用到的aid码进行,并通过request来选择B站的网址,从而最终收集到相关的数据。数据预处理很大程度上市用来爬取视频收集过程中的基本数据信息,并进行相关的操作。(1)数据清洗技术主要是通过使用python语言中的正则表达式技术,通过其大量收集目标数据,并进一步进行提取。(2)数据转换技术主要是通过加载法,将源数据中收集到的字符串按照相应的规则和序列转换成字典。
(3)数据去重即用unique方法,返回没有重复元素的数组或列表。 预处理后保存到CSV文件中。
3.2数据的挖掘与分析模块
数据挖掘主要是通过运用设计好的算法对已有的数据进行分析和汇总,并按照数据的特征进行情感分析。统计数据过程中多使用snownlp类库来实现这一基本的情感分析的操作,通过计算弹幕的数据值,来分析其中的倾向性。情感分析中长用sentiment来指明实际的情感值。其中,数据一旦越靠近1则越表明其正面属性,越接近0越负面,相关的结果数据可以作为情感分析的基础数据而得到。
3.3数据可视化模块
数据可视化模块主要采用饼图、词云和折线图等手段来实现最终的数据可视化。并通过matplotlib库等技术来进一步地研究和分析数据的特点,最终通过图表的模式来展示数据的深层含义。可视化模块包括各时段视频播放量比例图、热词统计图、每周不同时间视频播放量线图、情绪比例图等可视化图形。
二、开发环境
基本上所有Python爬虫初学者都会接触到两个工具库,requests和BeautifulSoup,这二者作为最为常见的基础库,其使用方式也截然不同,其中request工具库主要是用来获取网页的源代码,其需要向服务器发送url请求指令;而beautifulsoup则主要用来对网页的源语言,包括且不限于HTML\xml进行读取和解析,提取重要信息。这两个库模拟了人们访问网页、阅读网页以及复制粘贴相应信息的过程,可以批量快速抓取数据。流程如图1所示。
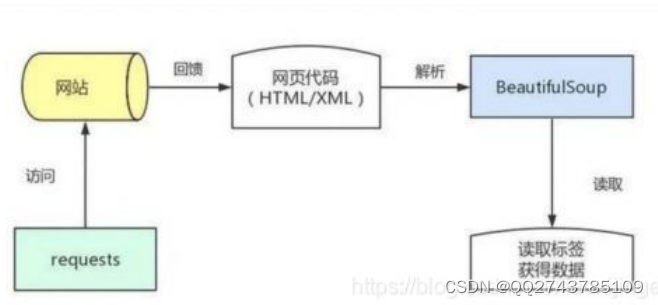
图1 数据获取及解析流程图
三、数据预处理
删除空值,重复值,对数据进行预处理,将None值换成0,只保留中文字符,将标题分割成一个个短词,同理处理标签,设置一个四舍五入代码,计算三连等比率:点赞率=点赞/播放量100%;硬币率=硬币/播放量100%;收藏率=收藏/播放量100%;转发率=转发/播放量100%;弹幕率=弹幕/播放量100%;评论率=评论/播放量100%
4.2各功能模块的实现
4.2.1热点视频的数据分析及可视化
首先查看处理后的视频数据信息,如图3所示:

图3 视频数据信息
共有88350位UP主,统计每个播放量区间的视频数量,[0,9999]区间的共213115个,占样本比例93.86%,[10000,99999]区间的共有10731个,占样本比例4.73%,[100000,499999]区间的共有2436个,占样本比例1.07%,[500000,999999]区间共有464个,占样本比例0.14%,[1000000,∞]区间共有320个,占样本区间0.02%,画出饼图,如图4所示:
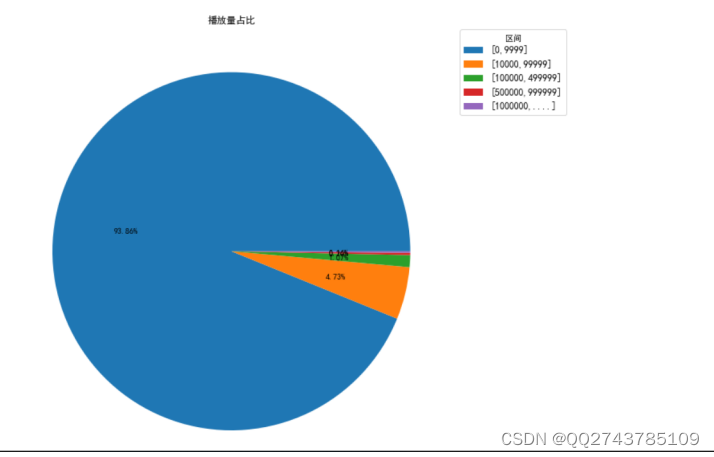
图4 播放量占比图
如果只展示一万播放量以上的内容,统计每个播放量区间的视频数量, [10000,99999]区间的共有10731个,占样本比例76.92%,[100000,499999]区间的共有2436个,占样本比例17.46%,[500000,999999]区间共有464个,占样本比例3.33%,[1000000,∞]区间共有320个,占样本区间2.29%,画出饼图,如图5所示:
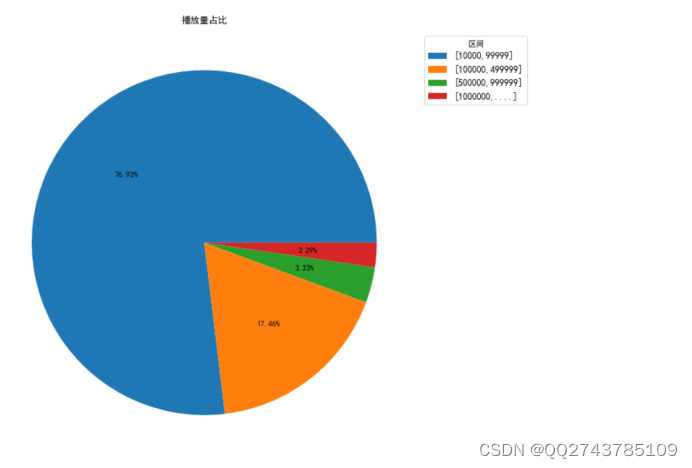
图5 播放量占比图(播放量1万以上)
统计展示播放量排名前二十的UP主,统计结果如图6所示::

图6 播放量排名
按播放量排名前20的具体数据展示,结果如图7所示:
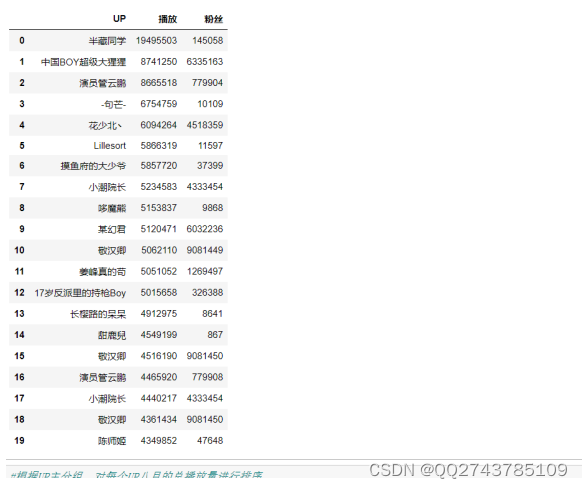
图7 具体数据展示
根据UP主分组对每个UP八月的总播放量进行排序,排序结果如图8所示:

图8 每个UP八月的总播放量展示图
对每周不同时间段发布的视频播放量大于10000的视频数量进行汇总,结果如图13所示:
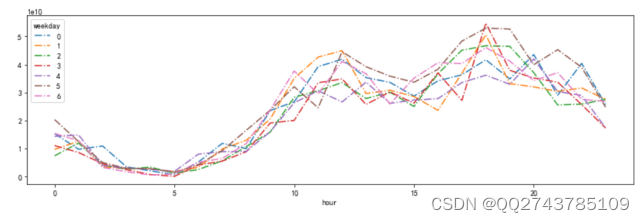
图13 播放量统计(视频播放量大于10000)
绘制词云,用词云显示出来“题目”热词,如图14所示:

图14 题目热词
用词云显示出来大于1万播放视频“题目”的热词,如图15所示:

图15 题目热词(播放量大于10000)
用词云显示出来大于10万播放视频“题目”的热词,结果如图16所示:

图16 题目热词(播放量大于100 000)
用词云显示出来大于100万播放视频“题目”的热词,结果如图17所示:

图17 题目热词(播放量大于1 000 000)
四、结论
本文按照预设模块逐项进行分析,基本模块均已实现。对热度视频的热词,点赞,投币,收藏,评论,弹幕等数据对视频播放量的影响进行可视化分析。
本文仅选取Bilibili搞笑版块的相关视频作为研究对象,数据样本的选取范围也主要是单一类型的视频,其单一性决定视频不会受到其余主题视频的影响。而B站的实际用户群体多是90后,特定的用户年龄段使得用户属性也相对独特,这有别于企业的视频平台。在未来的深入研究中,一来可以收集多个主题的数据信息,二来可以进行多平台的调查研究,通过提升样本多样性来增加结论的真实性。
目录
目录
第1章 绪论 1
1.1选题背景与意义 1
1.2研究目的及意义 2
1.3国内外研究现状 2
第2章 关键技术 2
1.1爬虫技术 4
2.2Python 4
第3章 模块设计 4
3.1数据爬取模块 5
3.2数据的挖掘与分析模块 5
3.3数据可视化模块 5
第4章 数据挖掘和分析 6
4.1 样本选取与数据来源 7
4.1.1数据爬取 7
4.1.2数据预处理 11
4.2各功能模块的实现 12
4.2.1热点视频的数据分析及可视化 12
4.2.2视频弹幕数据 27
第5章 总结 32
参考文献 33
致谢 35