文章目录
动机:之前的实体和关系提取工作专注于研究如何从预训练的编码器中获得更好的span表示。但却忽略了span(pairs)之间的相互关系。
贡献:提出了一种名为Packed Levitated Markers (PL-Marker)新的span表示方法 。
- 通过战略性地在编码器中 packing the markers 来考虑span(对)之间的相互关系。
- 提出了一种 neighborhood-oriented packing strategy ,该策略综合考虑了邻域span,以更好地建模实体边界信息。
- 对于那些更复杂的span对分类任务,作者设计了一种subject-oriented packing strategy,将每个主题及其所有对象 packs ,以模拟同一主题span对之间的相互关系。
《Packed Levitated Marker for Entity and Relation Extraction 》——ACL 2022(code)
前言:相关工作介绍
- 目前关系抽取算法 按处理方式 分类:
- pipeline approach:先抽实体,再判关系
- eg: 陈丹琦的《A Frustratingly Easy Approach for Joint Entity and Relation Extraction》(后面称为PURE)
- Joint Entity and Realtion Extraction:联合模型,通过将 将联合任务转化为以下问题:
- 填表问题,比如:table sequence,TPlinker
- 序列标注问题,比如:ETL Span,PRGC
- seq2seq问题,比如:SPN4RE
- pipeline approach:先抽实体,再判关系
目前, span representation提取的方法主要分为三种:T-Concat、Solid Marker、Levitated Marker。
-
T-Concat
T-Concat 就是将span的边界 token(开始和结束)的嵌入拼接起来用以表示span的嵌入,这种方式停留在token level获取有关信息,也忽略了边界 token之间的关系。这是陈丹琦大佬的《A Frustratingly Easy Approach for Joint Entity and Relation Extraction》(下称PURE)中NER模型就是用的这个方法。 -
Solid Marker(固定标记)
这种方法则显式地在span首尾各插入固定标记solid marker,以突出显示输入文本中的 span ,而对于object-subject的span对,则会在 subject span 和 object span 前后插入分别一对 solid marker。这种方法难以处理多对 object-subject 的情况,因为它无法在同一句子中区分不同的object和subject,也不能处理 overlapping spans 的情况。PURE-Full就用的这种方式。 -
Levitated Marker(悬浮标记)
首先设置一对悬浮标记Levitated Marker,使其与 span 的边界 token共享相同的位置信息,之后通过定向注意机制(directed attention)将一对 Levitated Marker 绑定在一起。具体地说,Levitated Marker中的两个marker会在注意掩码矩阵(attention mask matrix)中被设置为彼此可见,而对于text token 和 其他Levitated Marker的marker来说却是不可见的。
PURE 中RE模型用的就是这种方法,她仅仅是简单地将 solid marker 替换成了带实体类型信息的levitated markers。目前仅有PURE-Approx中用了这种方式,效果相较于PURE-Full是有折扣的,论文中认为简单将悬浮标记放到句子后面的方式没有考虑多个span之间的关联;
这里重点讲一下PURE,PL-Marker 作为 pipeline 方法的一种,也是在其基础上再有创新的,这里可以参考论文相关解析可以查看这篇博客,讲解比较清晰。
PURE
- 思路:
- 先抽实体: 将文本送入PLM中获取每个token的上下文表征,然后将每个span的start token、end token的上下文表征以及span长度的embedding拼接在一起得到span的表征,然后送进两层前馈神经网络,最后预测entity type;
- 再判关系: 采用了往句子中的subject span和object span的前后插入“typed marker”的方式,这个typed marker就是一对标记,object span的 typed marker 为 start marker [O: entity_type]和end marker [/O: entity_type],Subject span的[S: entity_type]和[/S: entity_type]。通过这种方式对句子改造以后,将改造后的句子送入PLM,然后将 Subject span 和 Object 的start marker 的上下文表征拼接在一起作为span的表征,然后过线性变换和softmax预测这个span的relation type。(后面称为PURE-Full)
- 存在问题:对于 每一个训练和预测样本,由于只能插入一对subject span和object span,所以计算量很大
- PURE具体解析可以看https://github.com/km1994/nlp_paper_study_information_extraction/tree/main/information_extraction/ERE_study/PURE
论文思路
- PL-Marker 提出了一些优化方法
- 优化方法一:
- 动机:PURE 所存在 的 计算量问题
- 思路:
- 首先,将typed marker全部放在句子末尾;
- 然后,通过让typed marker与相应的subject span或object span中的start token和end token共享位置embedding,并且利用attention mask矩阵来完成一些限定;
- typed marker仅仅可以与文本以及当前span pair内的typed marker进行attention, text仅可以与text进行attention
- 优点:可以在一个句子中并行处理多对span pairs了,他们提出的这种加速方法提升了关系抽取的速度;
- 缺点:效果略有下降
- 优化方法二:
- 动机:优化方法一所带来的性能下降问题
- 在之前的工作中,有三种span表征方式(
详见前言): - 论文 span表征方式:
-
对 Solid Marker(固定标记) 和 Levitated Marker(悬浮标记) 进行结合
-

-
提出两种 packing the markers 方式:
- 在做NER的时候提出了:Neighborhood-oriented Packing for span,就是将相邻的span的悬浮标记拼接在同一个样本里面;
- 在做RE的时候提出了:Subject-oriented Packing for span pair,就是将subject span用固定标记插入句子中,其对应的Object span们,用悬浮标记拼接在句子后面,放在一个样本里面;
-
- 优化方法一:
整体框架
PL-Marker的两种标签打包策略
PL-Marker使用的模型就是PLM,与PURE-Approx类似:
- 拼接在句子后面的悬浮标记对中的start marker与其在句子中对应的span的start token共享position embedding,end marker与对应span的end token共享 position embedding;
- 使用directional attention来绑定levitated markers标记,使得悬浮标记可以看到它的搭档标记和前面的文本,看不到其他悬浮标记对,文本仅可以看到文本

1. NER阶段
这部分采用的悬浮标记levitated markers,将所有的可能的实体span的悬浮标记对都放在句子最后面。但是这样就出现了一个问题,因为要遍历句子中所有可能的span,而PLM能处理的句子长度有限。
因此作者提出了Packing的策略,在Packing的时候,考虑到为了更好的分清楚span的边界(更重要的是区分同一个词为开头的span的差别),会将span相近的放在一起,就是将以开头相同的或者相近的放在一个样本中。
对于一个token数量为 N 的句子X={ x1,x2,⋯,xN*} ,规定最大的span长度为 L ,具体步骤如下:
- 首先,对所有的悬浮标记对(一个开始标记,一个结束标记)进行排序。首先按照每一对悬浮标记所代表的span的start token的位置升序排序,接着再按end token的位置升序排序,得到排序后的候选span列表。
- 然后,将所有的悬浮标记拆分成 K 个组并进行拼接,使得相邻的span的悬浮标记被分在同一个组中(即拼接在一起),拼接之后的 K 个悬浮标记序列再分别拼接到句子tokens序列之后,生成K 个训练实例(如上图所示, [ O ] , [ / O ] 表示
levitated markers)。这就是面向邻居的打包策略(neighborhood-oriented packing strategy)。其实就是穷举遍历所有span - 最后,将训练实例送进PLM(如Bert),对于每一对悬浮标记对 s_i=(a,b),分别将他们的开始标记(
start token marker)的表征h_a^{(s)} 和结束标记(end token marker)的表征 h_b^{(e)} 拼接在一起,作为其对应span的表征: ϕ ( s i ) = [ h a ( s ) ; h b ( e ) ] \phi (s_{i})=[h_a^{(s)} ;h_b^{(e)}] ϕ(si)=[ha(s);hb(e)]。 - 而在进行NER的时候,将上述步骤获取到span表征(也就是PL-Marker抽取到的span特征)与T-Concat方法抽取的span表征合并起来起来去预测entity type。怎么个合并法?看代码!
2. RE阶段
正如上文所说,本文在RE阶段采用solid markers与levitated markers混合使用的方式,用solid markers标记subject span,用levitated markers标记候选object。
假设输入序列为X ,subject span为 s_i=(a,b) ,以及它的候选object spans: (c1,d1),(c2,d2),⋯,(cm,dm)。具体做法如下:
-
对于句子
subject span首尾分别插入solid marker([ S ] 和[/S]),再将它对应的候选object span用悬浮标记的方式([ O ]和 [ / O ])拼接在文本后面(如上图所示)。句子X = { x 1 , ⋯ , x n } 就被改造成(符号 ∪表示共享position embedding):
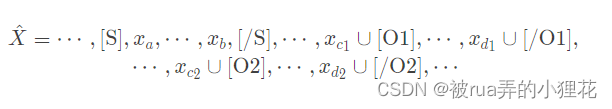
-
把训练实例送入PLM,对于样本中的每一个span对span pair ={s_{subject}, s_{object}}={(a,b),(c,d)},将subject span前后的
solid marker的表征 h_{ a-1}和h_{ b+1}以及一对object span的悬浮标记levitated markers的表征h_c^{(s)} 和 h_d^{(e)}拼接在一起,作为这一对span pair的表征: ϕ ( s i , s j ) = [ h a − 1 ; h b + 1 ; h c ( s ) ; h d ( e ) ] \phi (s_{i},s_{j})=[h_{a-1};h_{b+1};h_c^{(s)} ;h_d^{(e)}] ϕ(si,sj)=[ha−1;hb+1;hc(s);hd(e)] -
为了建模实体类型与关系类型之间的关系,他们还增加了预测object 类型的辅助loss函数。
-
为了增加一些补充信息,他们新增了从object到subject的反向关系的预测,从而实现了双向关系的预测,其实就是实现了一个Object-oriented packing strategy(为每个非对称关系建立了一个双向预测的Inverse Relation)。没有的 Inverse Relation 模型反而造成了 0.9%-1.1%的性能下降。这表明在非对称框架下,建模
object和subject之间信息的重要性。
Train
1.1 ACEDatasetNER
根据不同数据集切换不同的labellist,且self.max_entity_length = args.max_pair_length * 2.
def is_punctuation: 是否是标点符号
def get_original_token: 将特殊符号转为括号
def tokenize_word: 分成RobertaTokenizer(头为’,长度>1,不是标点符号)与其他Tokenizer
def initialize: ner_label_map->for: data = json.loads(line),subword2token(index*len[li]),token2subword(len[li]++)就是为了看之前分词是否彻底。后面略
1.2 for _ in train_iterator:
t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.num_train_epochs
num_warmup_steps=int(0.1*t_total)
for _ in train_iterator: for step, batch in enumerate(epoch_iterator):
note:if ‘span’ in agrgs.model_type: different dataset preprocess and inputs['mention_pos'] = batch[4]
After outputs = model(**inputs)
loss = outputs[0] # model outputs are always tuple in pytorch-transformers (see doc)
2 BertForSpanMarkerNER(代码默认调用)
self.ner_classifier = nn.Linear(config.hidden_size*4, self.num_labels)
self.alpha = torch.tensor([config.alpha] + [1.0] * (self.num_labels-1), dtype=torch.float32)
BertModel:outputs=# sequence_output, pooled_output, (hidden_states), (attentions)#后两者,有则加之;此处无
def forward(
self,
input_ids=None,
attention_mask=None,
mentions=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
labels=None,
mention_pos=None,
full_attention_mask=None,
):
outputs = self.bert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
full_attention_mask=full_attention_mask,
)
hidden_states = outputs[0] #=sequence_output
if self.onedropout:
hidden_states = self.dropout(hidden_states)
seq_len = self.max_seq_length
bsz, tot_seq_len = input_ids.shape
ent_len = (tot_seq_len-seq_len) // 2 #(1024-512)//2
e1_hidden_states = hidden_states[:, seq_len:seq_len+ent_len]#+m1=PL-Marker抽取到的span特征h_a^(s)
e2_hidden_states = hidden_states[:, seq_len+ent_len: ] #h_b^(e)
m1_start_states = hidden_states[torch.arange(bsz).unsqueeze(-1), mention_pos[:, :, 0]] #span的start token的上下文表征
m1_end_states = hidden_states[torch.arange(bsz).unsqueeze(-1), mention_pos[:, :, 1]] #end token,len=ent_len,z这两者是T-concat方法抽取的span表征
feature_vector = torch.cat([e1_hidden_states, e2_hidden_states, m1_start_states, m1_end_states], dim=2) #拼接方式与BiNER不同
if not self.onedropout:
feature_vector = self.dropout(feature_vector)
ner_prediction_scores = self.ner_classifier(feature_vector)
outputs = (ner_prediction_scores, ) + outputs[2:] # Add hidden states and attention if they are here
if labels is not None:
loss_fct_ner = CrossEntropyLoss(ignore_index=-1, weight=self.alpha.to(ner_prediction_scores))
ner_loss = loss_fct_ner(ner_prediction_scores.view(-1, self.num_labels), labels.view(-1))
outputs = (ner_loss, ) + outputs
return outputs # (ner_loss, ner_prediction_scores) + (hidden states , attention)
** 与PURE比较**

span的表征 h e ( s i ),ϕ(si)表示学习到的跨度宽度特征的嵌入[学习方法以及span表征he(si)拼接方法如下]
def batchify(samples, batch_size):
"""
Batchfy samples with a batch size
"""
num_samples = len(samples)
list_samples_batches = []
# if a sentence is too long, make itself a batch to avoid GPU OOM
to_single_batch = []
for i in range(0, len(samples)):
if len(samples[i]['tokens']) > 350:
to_single_batch.append(i)
for i in to_single_batch:
logger.info('Single batch sample: %s-%d', samples[i]['doc_key'], samples[i]['sentence_ix'])
list_samples_batches.append([samples[i]])
samples = [sample for i, sample in enumerate(samples) if i not in to_single_batch]
for i in range(0, len(samples), batch_size):
list_samples_batches.append(samples[i:i+batch_size])
assert(sum([len(batch) for batch in list_samples_batches]) == num_samples)
return list_samples_batches
spans = list_samples_batches[“spans”]
def _get_input_tensors(self, tokens, spans, spans_ner_label):
start2idx = []
end2idx = []
bert_tokens = []
bert_tokens.append(self.tokenizer.cls_token)
for token in tokens: #将start2end tokenizer
start2idx.append(len(bert_tokens))
sub_tokens = self.tokenizer.tokenize(token)
bert_tokens += sub_tokens
end2idx.append(len(bert_tokens)-1)
bert_tokens.append(self.tokenizer.sep_token)
indexed_tokens = self.tokenizer.convert_tokens_to_ids(bert_tokens)
tokens_tensor = torch.tensor([indexed_tokens])
bert_spans = [[start2idx[span[0]], end2idx[span[1]], span[2]] for span in spans]
bert_spans_tensor = torch.tensor([bert_spans])
spans_ner_label_tensor = torch.tensor([spans_ner_label])
return tokens_tensor, bert_spans_tensor, spans_ner_label_tensor
spans = bert_spans_tensor
def _get_span_embeddings(self, input_ids, spans, token_type_ids=None, attention_mask=None):
sequence_output, pooled_output = self.albert(input_ids=input_ids, token_type_ids=token_type_ids, attention_mask=attention_mask)
sequence_output = self.hidden_dropout(sequence_output)
"""
spans: [batch_size, num_spans, 3]; 0: left_ned, 1: right_end, 2: width
spans_mask: (batch_size, num_spans, )
"""
spans_start = spans[:, :, 0].view(spans.size(0), -1)
spans_start_embedding = batched_index_select(sequence_output, spans_start)
spans_end = spans[:, :, 1].view(spans.size(0), -1)
spans_end_embedding = batched_index_select(sequence_output, spans_end)
spans_width = spans[:, :, 2].view(spans.size(0), -1)
spans_width_embedding = self.width_embedding(spans_width)
spans_embedding = torch.cat((spans_start_embedding, spans_end_embedding, spans_width_embedding), dim=-1)
"""
spans_embedding: (batch_size, num_spans, hidden_size*2+embedding_dim)
"""
return spans_embedding
因为在原来的句子表示时,我们加入marker之后get到的上下文信息是不一样的,因为marker改变了句子结构。为了能够复用单词的信息表示,我们采用如下策略:我们将marker的位置信息和span开头结尾的位置信息绑定。这样原句子的位置信息embedding就不会更改了。然后,我们限制attention层。我们强制文本token只注意文本token,而不会注意到marker token,所有这4个token对应同一个span对。这种更改使得我们能够复用token。在实践中,我们把所有的marker加到句尾。
————————————————
版权声明:本文为CSDN博主「alkaid_sjtu」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_44047857/article/details/122074084
3 BertForSpanMarkerBiNER(符合论文公式实现)
# ...表示省略不写,后同
def forward(
...
):
outputs = self.bert(
...
)
hidden_states = outputs[0]
if self.onedropout:
hidden_states = self.dropout(hidden_states)
seq_len = self.max_seq_length
bsz, tot_seq_len = input_ids.shape
ent_len = (tot_seq_len-seq_len) // 2
e1_hidden_states = hidden_states[:, seq_len:seq_len+ent_len]
e2_hidden_states = hidden_states[:, seq_len+ent_len: ]
m1_start_states = hidden_states[torch.arange(bsz).unsqueeze(-1), mention_pos[:, :, 0]]
m1_end_states = hidden_states[torch.arange(bsz).unsqueeze(-1), mention_pos[:, :, 1]]
m1 = torch.cat([e1_hidden_states, m1_start_states], dim=2) #h_a^s
m2 = torch.cat([e2_hidden_states, m1_end_states], dim=2) #h_b^e
feature_vector = torch.cat([m1, m2], dim=2)
if not self.onedropout:
feature_vector = self.dropout(feature_vector)
ner_prediction_scores = self.ner_classifier(feature_vector)
# m1 = self.dropout(self.reduce_dim(m1))
# m2 = self.dropout(self.reduce_dim(m2))
m1 = F.gelu(self.reduce_dim(m1))
m2 = F.gelu(self.reduce_dim(m2))
ner_prediction_scores_bilinear = self.blinear(m1, m2)
ner_prediction_scores = ner_prediction_scores + ner_prediction_scores_bilinear
outputs = (ner_prediction_scores, ) + outputs[2:] # Add hidden states and attention if they are here
if labels is not None:
loss_fct_ner = CrossEntropyLoss(ignore_index=-1, weight=self.alpha.to(ner_prediction_scores))
ner_loss = loss_fct_ner(ner_prediction_scores.view(-1, self.num_labels), labels.view(-1))
outputs = (ner_loss, ) + outputs
return outputs
4 ACEDataset(RE模块)
相比1,多了
self.max_pair_length = max_pair_length #
self.max_entity_length = self.max_pair_length*2 #
self.use_typemarker = args.use_typemarker #
self.no_sym = args.no_sym #label_list 多两个;self.sym_labels = ['NIL'];#无'PER-SOC'
5 BertForACEBothOneDropoutSub(代码默认Re调用)
inputs = {'input_ids': batch[0],
'attention_mask': batch[1],
'position_ids': batch[2],
'labels': batch[5],
'ner_labels': batch[6],
}
inputs['sub_positions'] = batch[3]
inputs['mention_pos'] = batch[4]
inputs['sub_ner_labels'] = batch[7]
def forward(
self,
input_ids=None,
attention_mask=None,
mentions=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
sub_positions=None,
labels=None,
ner_labels=None,
):
outputs = self.bert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
)
hidden_states = outputs[0]
hidden_states = self.dropout(hidden_states)
seq_len = self.max_seq_length
bsz, tot_seq_len = input_ids.shape
ent_len = (tot_seq_len-seq_len) // 2
e1_hidden_states = hidden_states[:, seq_len:seq_len+ent_len]
e2_hidden_states = hidden_states[:, seq_len+ent_len: ]
feature_vector = torch.cat([e1_hidden_states, e2_hidden_states], dim=2)
ner_prediction_scores = self.ner_classifier(feature_vector)
m1_start_states = hidden_states[torch.arange(bsz), sub_positions[:, 0]]
m1_end_states = hidden_states[torch.arange(bsz), sub_positions[:, 1]]
m1_states = torch.cat([m1_start_states, m1_end_states], dim=-1)
m1_scores = self.re_classifier_m1(m1_states) # bsz, num_label
m2_scores = self.re_classifier_m2(feature_vector) # bsz, ent_len, num_label
re_prediction_scores = m1_scores.unsqueeze(1) + m2_scores
outputs = (re_prediction_scores, ner_prediction_scores) + outputs[2:] # Add hidden states and attention if they are here
if labels is not None:
loss_fct_re = CrossEntropyLoss(ignore_index=-1, weight=self.alpha.to(re_prediction_scores))
loss_fct_ner = CrossEntropyLoss(ignore_index=-1)
re_loss = loss_fct_re(re_prediction_scores.view(-1, self.num_labels), labels.view(-1))
ner_loss = loss_fct_ner(ner_prediction_scores.view(-1, self.num_ner_labels), ner_labels.view(-1))
loss = re_loss + ner_loss
outputs = (loss, re_loss, ner_loss) + outputs
return outputs # (masked_lm_loss), prediction_scores, (hidden_states), (attentions)
6 BertForACEBothOneDropoutLeviPair(符合论文Re公式)
# ...表示省略不写,后同
def forward(
...
):
outputs = self.bert(
...
)
hidden_states = outputs[0]
hidden_states = self.dropout(hidden_states)
seq_len = self.max_seq_length
bsz, tot_seq_len = input_ids.shape
ent_len = (tot_seq_len-seq_len) // 4
e1_hidden_states = hidden_states[:, seq_len:seq_len+ent_len] #h_a-1
e2_hidden_states = hidden_states[:, seq_len+ent_len*1: seq_len+ent_len*2] #h_b+1
e3_hidden_states = hidden_states[:, seq_len+ent_len*2: seq_len+ent_len*3] #h_c^s
e4_hidden_states = hidden_states[:, seq_len+ent_len*3: seq_len+ent_len*4] #h_d_e
m1_feature_vector = torch.cat([e1_hidden_states, e2_hidden_states], dim=2)
m2_feature_vector = torch.cat([e3_hidden_states, e4_hidden_states], dim=2)
feature_vector = torch.cat([m1_feature_vector, m2_feature_vector], dim=2) #/phi
m1_ner_prediction_scores = self.ner_classifier(m1_feature_vector)
m2_ner_prediction_scores = self.ner_classifier(m2_feature_vector)
re_prediction_scores = self.re_classifier(feature_vector) # bsz, ent_len, num_label
outputs = (re_prediction_scores, m1_ner_prediction_scores, m2_ner_prediction_scores) + outputs[2:] # Add hidden states and attention if they are here
if labels is not None:
loss_fct_re = CrossEntropyLoss(ignore_index=-1, weight=self.alpha.to(re_prediction_scores))
loss_fct_ner = CrossEntropyLoss(ignore_index=-1)
re_loss = loss_fct_re(re_prediction_scores.view(-1, self.num_labels), labels.view(-1))
m1_ner_loss = loss_fct_ner(m1_ner_prediction_scores.view(-1, self.num_ner_labels), m1_ner_labels.view(-1))
m2_ner_loss = loss_fct_ner(m2_ner_prediction_scores.view(-1, self.num_ner_labels), m2_ner_labels.view(-1))
loss = re_loss + m1_ner_loss + m2_ner_loss
outputs = (loss, re_loss, m1_ner_loss+m2_ner_loss) + outputs
return outputs # (masked_lm_loss), prediction_scores, (hidden_states), (attentions)
至于Relation,PURE是将subject和object的output和embedding拼接起来[BertForRelation和BertForRelationApprox]
PL-marker vs PURE
总的来说,PL-Marker对PURE的改进主要包括:
针对PURE的levitated marker 方式,提出打包策略packed levitated marker。
在NER阶段,PURE使用标准的基于span的方式(T-concat),本文同样使用packed levitated marker的方法做NER任务。
RE阶段,引入Inverse Relation,进一步提升了RE性能。同时,取消了PURE使用的typed marker,改用 entity type loss 函数
PS
- 本文通过实验发现,相比于
PURE,使用typed marker反而对性能造成了负面影响。个人认为,从遵循直觉角度而言,实体类型信息肯定是会对关系分类起到启发性作用的(特别的,如在“出生日期”和“国籍”两个候选关系类型中,如果存在类型分别是“人物”和“时间”的两个实体,它们之间的关系就是“出生日期”等,而不会是“国籍”),造成本文实验结果的原因可能是使用方式与模型架构不适用导致的,后续可以在这方面进行改进。 NER阶段通过分组的方法,缩减了训练的时间,但时间成本相对于以前的 SOTA 仍较高,毕竟是在枚举所有可能的span。除了分组,是否还有别的方法可以缩减计算时间?