点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
点击进入—> CV 微信技术交流群
本文主要介绍最近两篇 ECCV 2022 Oral 的工作,分别在 offline 和 online 范式下的视频实例分割(Video Instance Segmentation, VIS)任务上取得了目前最高的性能,并在CVPR2022第四届大规模视频物体分割挑战赛( 4th Large-scale Video Object Segmentation Challenge)的视频实例分割赛道上取得第一名,模型和代码均已开源!
SeqFormer:
https://arxiv.org/abs/2112.08275
IDOL:
https://arxiv.org/abs/2207.10661
官方代码地址:
https://github.com/wjf5203/VNext

SeqFormer:Sequential Transformer for Video Instance Segmentation, ECCV, 2022 (Oral).
SeqFormer:用于视频实例分割的序列Transformer
基于 vision transformer, 该文章提出了一种 offline 的 VIS 算法:SeqFormer。SeqFormer为视频中的每一个物体建立对应的特征,并使该特征拥有提取全局信息的能力。与现有的算法不同,SeqFormer 提出了一个 Query 分离的机制,将 Instance Query 分离成 Box Query,在每一帧分别去提取该物体对应位置的信息,然后进行聚合以在 video-level 更有效地表示每个 instance。在不使用任何tracking branches以及后处理的情况下,SeqFormer 在 YouTube-VIS 达到了 47.4 AP (ResNet-50)和 49.0 AP (ResNet-101) 的精度,分别超过了目前的最优算法 4.6 和 4.4 AP。
In Defense of Online Models for Video Instance Segmentation, ECCV, 2022 (Oral).
IDOL : 在线视频实例分割新范式
该文章是ECCV2022满分文章。文章首先分析了在VIS任务中,offline算法往往领先同时期online算法达到 10AP 左右的现象,并深入分析了导致 online 模型和 offline 模型的巨大性能差距的原因,提出了一个基于contrastive learning的 online 算法:IDOL。该算法可以学习更具有区分度的instance embedding,并且充分利用了视频的历史信息来保证算法的稳定性,将online模型表现提高到一个与offline模型相当甚至更高的水平上。IDOL 在 YouTube-VIS 2019 上达到了 49.5 AP,分别超越了之前的最优的 online / offline 算法 13.2 / 2.1 AP。在更有挑战的OVIS数据集上,IDOL 更是达到了30.2 AP,超越了之前的最优算法一倍。而在最近举行的 CVPR 2022 Large-Scale Video Object Segmentation Challenge, Video Instance Segmentation Track 上,IDOL也超越了一众 online/offline 模型,取得了第一名。

VNext是作者提出基于Detectron2的视频实例识别框架,以上两篇文章的代码目前都被整合进了VNext中。VNext旨在为视频实例识别领域提供一个统一且高效的框架来促进该领域的发展,欢迎大家在VNext上进行视频相关任务的探索和实验:https://github.com/wjf5203/VNext 。
Video Demo:
1
SeqFormer:Sequential Transformer for Video Instance Segmentation, ECCV, 2022 (Oral)
SeqFormer:用于视频实例分割的序列Transformer
一、Motivation
视频实例分割是一个近几年兴起的视觉任务,在图像实例分割的基础上引入了时序维度,在分割每一帧物体的同时要求在帧间跟踪这些物体,因此如何利用好视频的时序特征也是该任务的一大难点。最近Transformer的发展给这个领域带来一些新的解决思路,但是之前基于Transformer的方法会将整个视频的三维特征直接展平直接送入Transformer Decoder中,希望模型同时完成Segmentation和Tracking,这样直接的解决方案虽然有效,但是不符合对视频的直觉认知。文章认为,视频的二维空间特征和时序特征应该被分别以不同的方式处理。
因此,SeqFormer提出了Decoder中的Query分离机制,具体来说,SeqFormer把共享的实例Query分离到每一帧上,在每一帧上独立定位物体并提取对应特征,以此来保证模型在每一帧上提取的信息是准确的。最终,每一帧上的信息被聚合到一起成为一个全局的物体特征表示,这个特征最终被用来预测物体类别并且生成动态卷积的参数用来在每一帧上分割出物体。文章认为这样的一个聚合了全局信息的特征可以更加鲁棒和高效的表示视频中的物体,从而进一步提高Transformer在VIS上的表现。
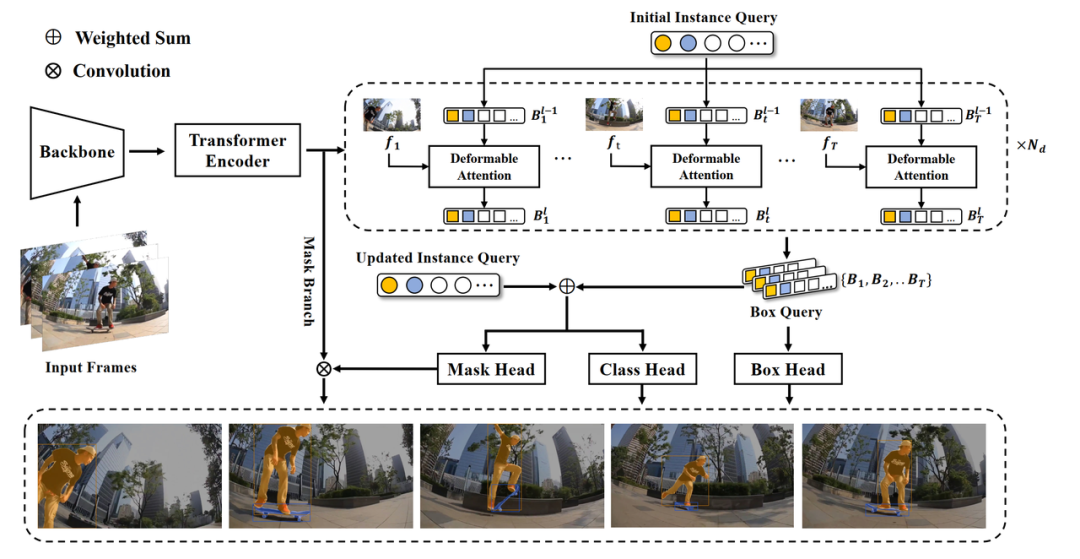
二、SeqFormer
SeqFormer的整体结构包括三部分 (1)骨干网络以及Transformer Encoder (2)Query Decompose Decoder (3)各种输出的Output Head。其中骨干网络和Transformer Encoder 都进行的是frame-level的特征提取。
2.1 Query Decompose Decoder
该部分是SeqFormer的核心结构。当给定的一个视频中,物体的形状、位置出现变化甚至被遮挡的时候,人们通常可以轻易分辨出该物体,因为人们会把这些不同帧的物体当做同一个来看待,这是视频和图片的关键区别。
因此,文章提出Instance Query和Box Query的概念:在Decoder的第一层,共享的Instance Query 会被分离到每一帧上,在每一帧上独立进行attention;且Box Query会通过Box Head预测出物体在每一帧上的包围框,并且在Decoder的每个layer之间迭代优化。Box Query 就像Instance Query留在每一帧上的Anchor,去定位并关注到同一个物体,并将提取到的信息重新聚合到Instance Query上。通过这样一个Query Decompose Decoder,SeqFormer完成了在每一帧上寻找物体并聚合全局特征的过程。

如图所示,可视化了在不同Decoder layer之后,Decoder中的同一个Instance Query 对应的Box Query 在每一帧上的关注区域。(a)是第一层Decoder的关注区域,由于每一帧上的Box Query有着相同的初始化值,所以他们的关注区域是相同的;(b)是第二层的关注区域,可以看出此时模型关注的区域已经分布在对应的物体周围了;(c)是最后一层Decoder 的关注区域,此时关注的区域更加精确。整个Decoder 以这样一种coarse-to-fine的方式定位到每个物体,并聚合得到每个物体的video-level的特征表示。
2.2 Output Head
在得到每个物体的video-level的特征表示之后,通过两个FFN分别得到该物体的分类结果以及Mask Head 的权重参数。Mask Head是一个三层的1x1卷积网络,在Encoder通过Mask Branch得到的高分辨率Feature Map上进行卷积,从而动态在每一帧上利用同一个MaskHead预测mask。由于物体在不同的帧上共用同一个Mask Head进行卷积,这使得SeqFormer对物体的分割非常高效,同时也可以利用在少量帧上生成Mask Head 在所有帧上进行卷积从而完成对整个视频的分割,扩展了SeqFormer的应用方式。
三、Demo
以下Demo 展示了SeqFormer在YouTube-VIS 2019 的一些视频上的可视化效果。
四、Performance
在Youtube-VIS 2019和 2021 上对SeqFormer进行了评测:
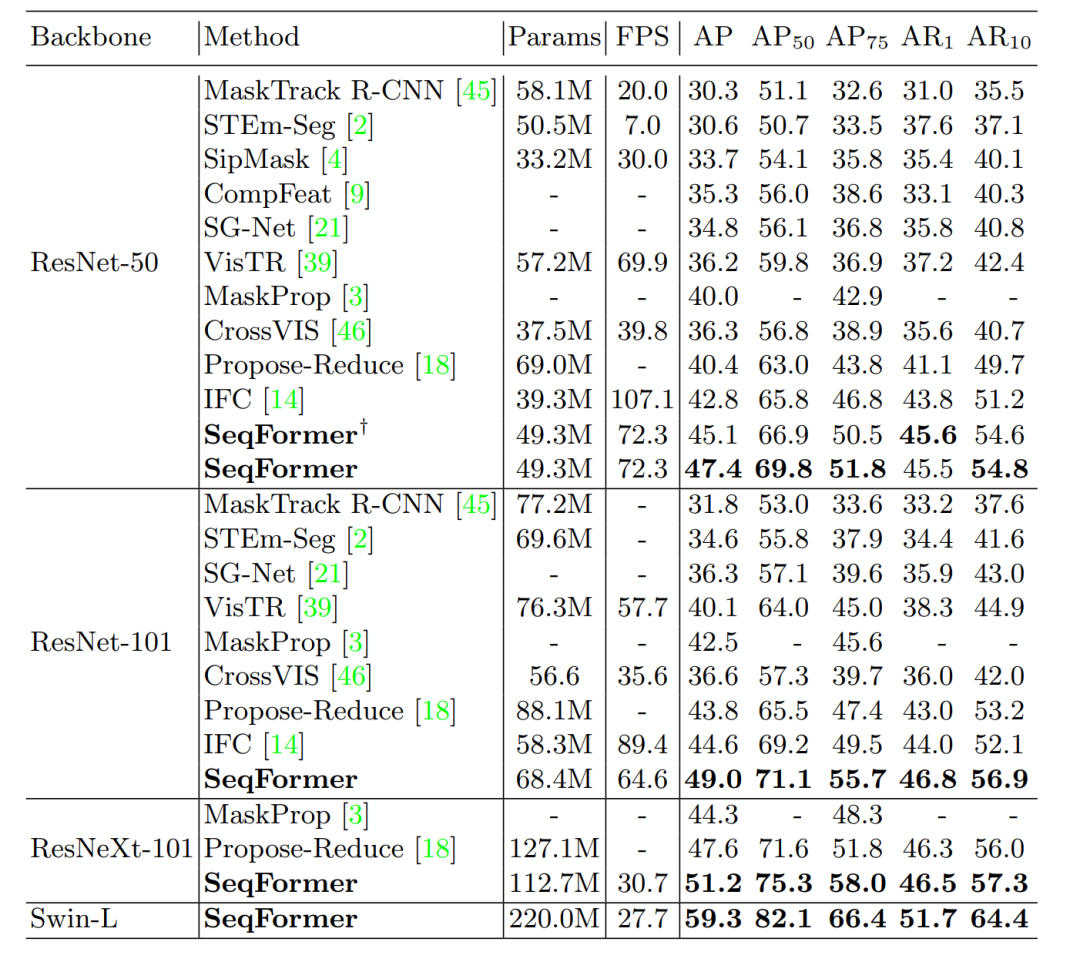
4.1 YouTube-VIS 2019
在YouTube-VIS 2019,SeqFormer在与各种backbone的组合下,均在mask AP上超越了之前算法一大截,在ResNet-50上mask AP能够达到47.4,通过与Swin-Transformer的组合,SeqFormer将这个benchmark上的表现推到了59.3的新高度。得益于Offline 模型能够以batch的形式对多帧并行处理,SeqFormer的FPS也达到72.3。
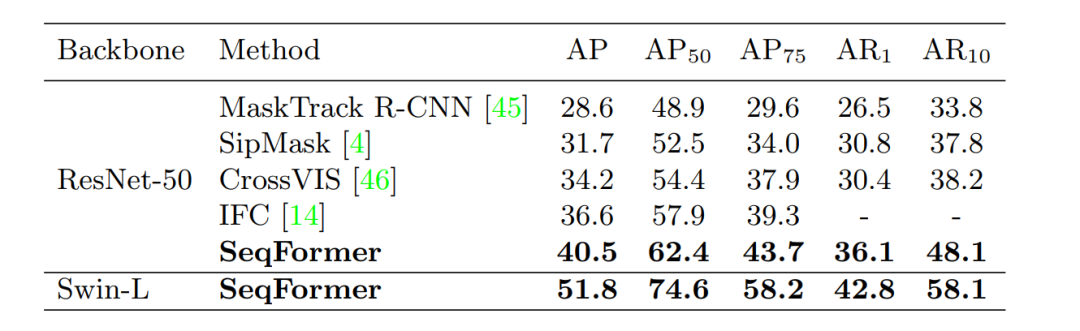
4.2 YouTube-VIS 2021
在YouTube-VIS 2021 上,SeqFormer也能够稳定达到state-of-the-art。
五、Conclusion
SeqFormer对齐了视频中不同帧上的物体信息且自然地解决了视频实例分割中的分割和跟踪问题,而不需要任何后处理,它将VIS的模型性能提高到一个新的台阶。作者希望简洁高效的SeqFormer能够给VIS领域带来一些启发,并且成为未来研究的一个强有力的baseline。
2
In Defense of Online Models for Video Instance Segmentation, ECCV, 2022 (Oral)
IDOL : 在线视频实例分割新范式
一、Motivation
在VIS任务中,以往offline算法往往领先同时期online算法达到 10AP 左右,然而online算法在处理长视频和持续视频等现实任务中拥有其固有的优势。为了理解VIS任务中 online 模型和 offline 模型性能的巨大差异的原因,作者设计了 frame 和 clip 两种 Oracle 实验,详细研究了现有 offline 模型 (IFC & SeqFormer):
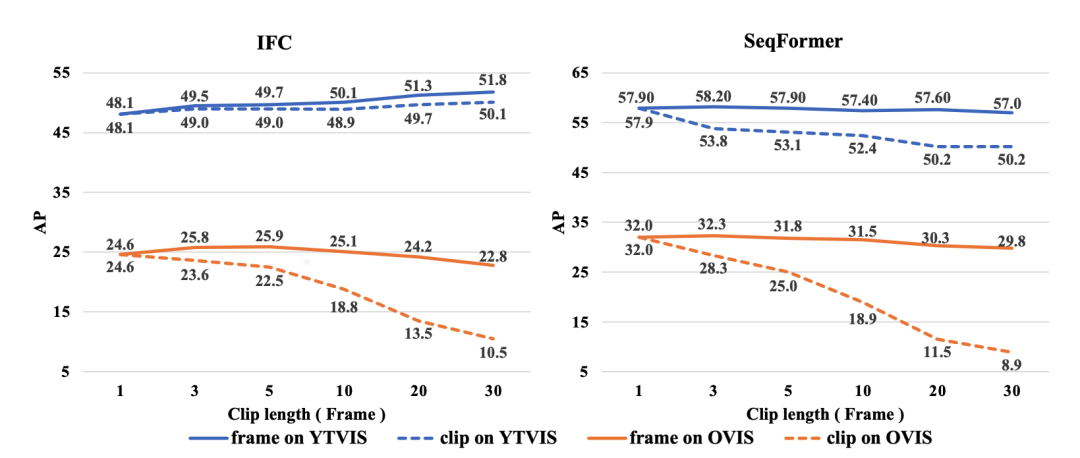
对于 frame oracles,在每个 clip 内和相邻 clip 之间提供 groundtruth 的实例 ID,此时算法的性能仅取决于所估计的 segmentation mask 的质量。对于 clip oracles,只提供相邻 clip 之间的 groundtruth 实例 ID,需要该方法自己在 clip 内进行关联。此时,frame oracles 与 clip oracles 的性能差距则反映了当前 offline 模型中完成的黑盒关联的效果。
同样,文章也对比了目前最佳的 online 算法 (CrossVIS):
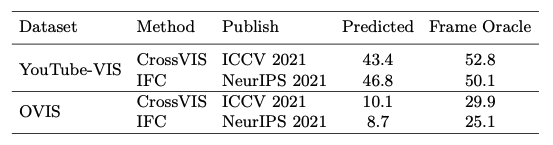
通过以上的实验,可以得到如下结论:
从实例分割的角度来看,per-clip 分割在 mask 质量上并没有比 per-frame 分割好很多,而且 mask 质量也不是 online 方法性能不佳的原因:CrossVIS 甚至优于其同时期的工作(即 IFC )
当前 SOTA offline 方法的 per-clip 分割并不总是有效和鲁棒:多帧确实提供了更多信息,但它只适用于某些情况:per-clip 分割分割并不能明显提高 SeqFormer 的性能。此外,在 OVIS 等更具挑战性的数据集上进行测试时,当片段大小变长时,多帧分割甚至会使 IFC 和 SeqFormer 上的性能分别降低 1.8 和 2.2 AP。虽然从理论上讲,offline 算法的 per-clip 分割具有使用多帧的固有优势,但它仍然需要进一步探索,特别是在如何利用多帧中的信息以及如何处理复杂的运动模式、遮挡和对象变形方面。
从跨帧匹配的角度来看,offline方法的一个巨大优势是它们可以使用黑盒网络进行 clip 内的匹配。这一优势在 YouTube-VIS 数据集上非常明显。作者证明这是造成当前online和offline范式之间性能差距的主要原因。然而,当视频变得复杂时,offline 算法的黑盒关联过程也会迅速恶化(在 OVIS 上,IFC/SeqFormer 的性能分别降低了 12.3/20.9 AP)。此外,在处理较长的视频时,offline 方法需要将输入视频分割成多个clip以避免超出计算限制,clip与clip 的匹配仍然不可避免。因此,匹配/关联是造成online 与 offline 模型性能差距的主要原因,同时对于 offline 模型仍然是不可避免的和非常重要的。
在充分理解了当先 online 与 offline 算法的表现后,作者发现提升online 算法的性能的核心在于提高匹配的性能。
因此,文章提出了IDOL。其关键思想是在 embedding 空间中确保相同实例在帧之间的相似性以及不同实例在所有帧中的差异,同时提供更具判别力的实例特征,具有更好的时间一致性,从而保证了更准确的帧间关联结果。其次,之前的方法往往通过手工设置来选择正负样本,这在遮挡和拥挤的场景中引入了 false positives 。为了解决这个问题,文章将样本选择问题表述为优化理论中的最优传输问题,从而减少 false positives 并进一步提高对比学习样本的质量。在推理过程中,通过使用一对多的时间加权 softmax,利用历史帧上的信息来重新识别由遮挡引起的缺失实例,并加强关联的一致性和完整性。
二、Details
为了提高匹配的性能,作者提出了一个基于对比学习的框架来提取更具有判别性的特征,整体网络结构如下图所示:
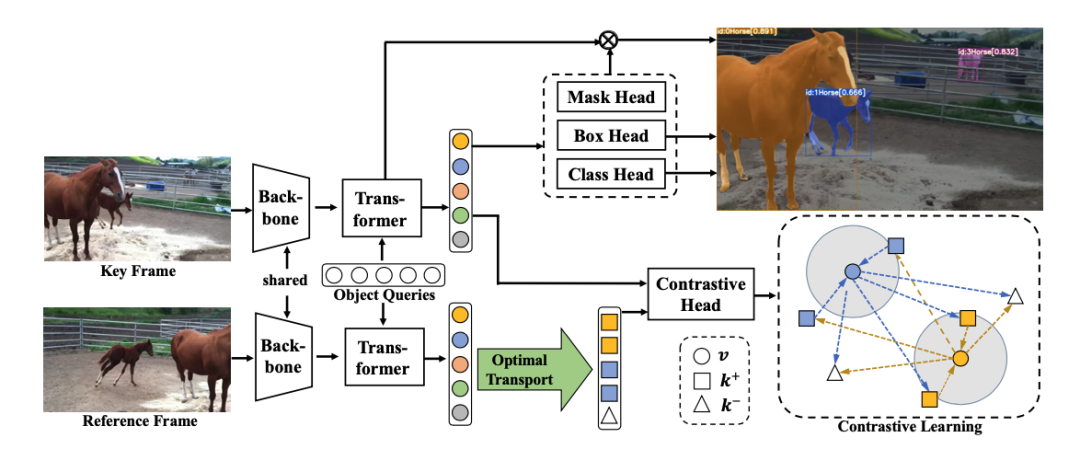
IDOL对每一帧图片进行单帧的实例分割,为了与SeqFormer公平对比,IDOL采用与SeqFormer相同的实例分割pipeline。IDOL包括模型训练和推理两个阶段:
训练阶段,如上图所示,训练时随机从训练集中抽取一帧作为关键帧,同时抽取同一个视频的相邻帧作为参考帧。关键帧和参考帧送入一个共享权重的backbone和 Transformer 中进行处理。Transformer 的作用是利用一系列固定数量 N 的可学习的物体查询器在特征图上提取特征,最后输出的 N 个特征表示,包含了图片中每个物体的特征。对于关键帧,这些特征表示被用来送入三个Output Head完成单帧的实例分割,此处为了提供更丰富的对比学习样本,原先SeqFormer中的预测结果与GT之间的一对一匹配,被更改为由最优传输完成的一对多匹配,以此来增加每个GT所对应的特征数量。对于参考帧,Transformer 生成的 N 个特征表示中包含了参考帧上每个物体的信息,对于这些特征表示,通过最优传输理论,根据检测器预测的包围框以及分类分数,为关键帧上的每个物体选择在参考帧上的多个正负样本。图中v 为关键帧上的每个物体的特征表示,k+ 和 k- 分别为其在参考帧上的正样本和负样本特征表示,这些正负样本,通过另外一个对比学习特征生成器,并通过对比的损失函数计算损失值,用来使网络学到更能区分不同物体的特征表示。
推理阶段,IDOL 将视频的每一帧依次送入训练好的模型中,模型在预测每一帧分割结果的同时,会给每个分割结果同时产生一个对比特征,该特征用于将每一帧的分割结果链接起来。具体来说,会先初始化一个实时更新记忆列表,在第一帧被检测出的物体被添加进该列表中,赋予初始化的 id 序号,在之后的每一帧上,被检测出的物体的对比特征会与列表中每个物体的对比特征算一个双向一对多的时间加权 softmax分数,根据该分数将新检测出的物体对应到记忆列表中的物体上,同时更新记忆列表中的对比特征用于下一帧的匹配。
三、Demo
以下Demo 展示了IDOL 在OVIS 以及 YouTube-VIS 2019 的一些视频上的可视化效果。
四、Performance
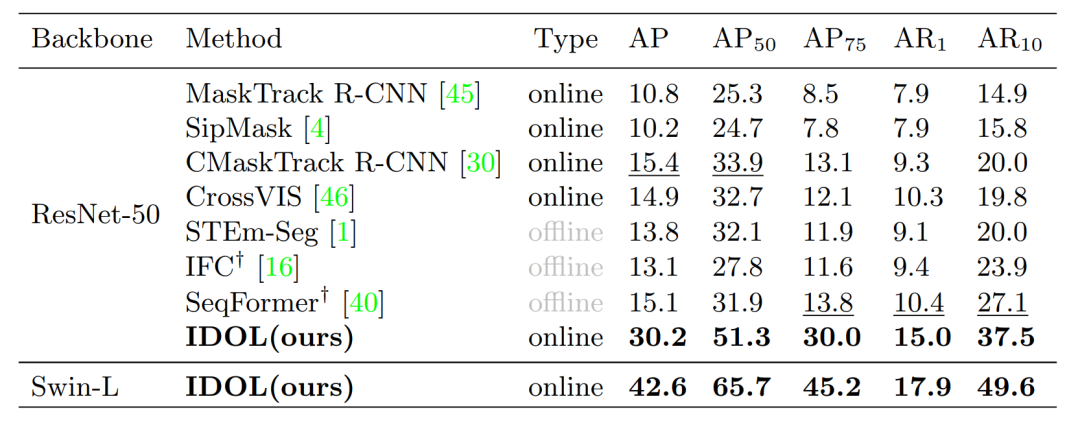
文章将IDOL与目前主流的online、offline 模型进行了对比,“V” 表示仅使用 YouTube-VIS 训练集进行训练。“V+I” 表示也选取了 COCO 上重叠类别的 synthetic 视频用于联合训练。 表示将COCO中的图片随机裁剪两次组成key-reference frame 对IDOL进行预训练。可以看到,IDOL大幅超过了目前的其他online算法,同时也超过了主流的offline算法。
Table1: Comparison on YouTube-VIS 2019 val set
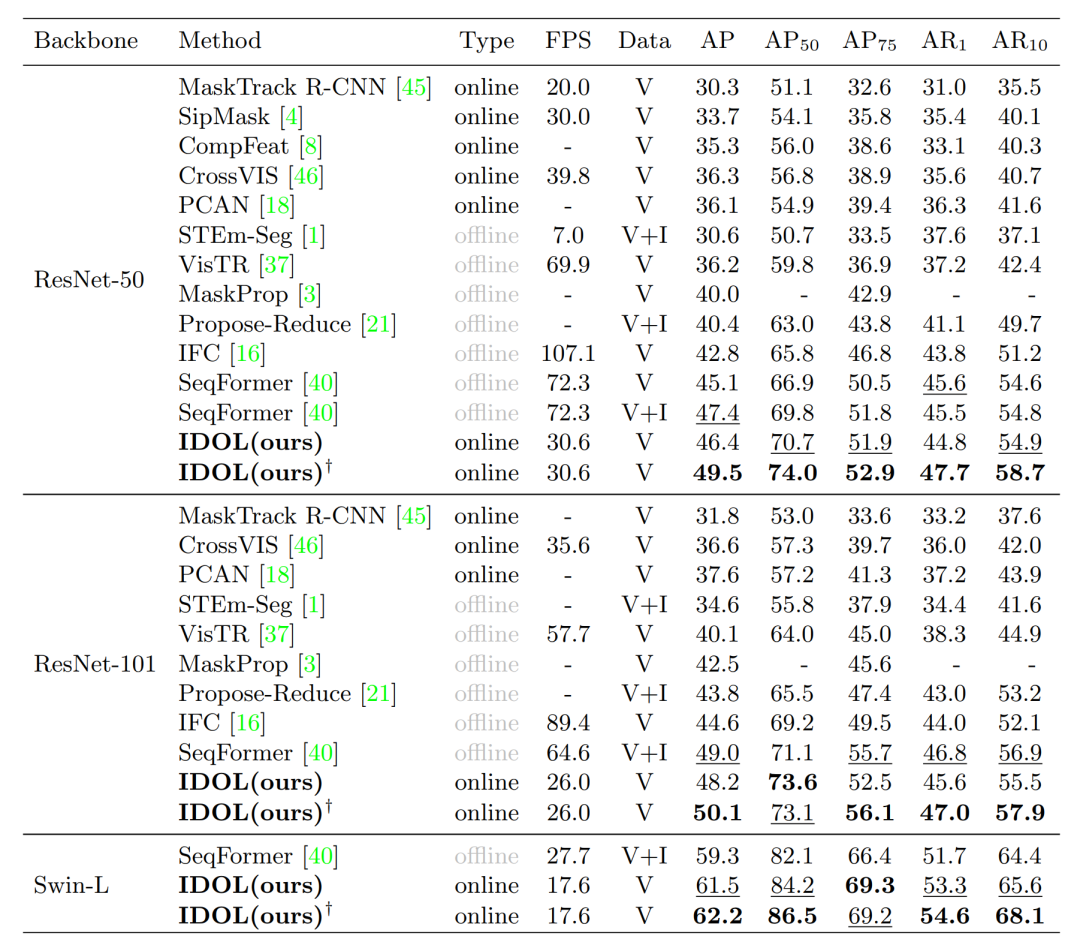
Table2: Comparison on YouTube-VIS 2021 val set
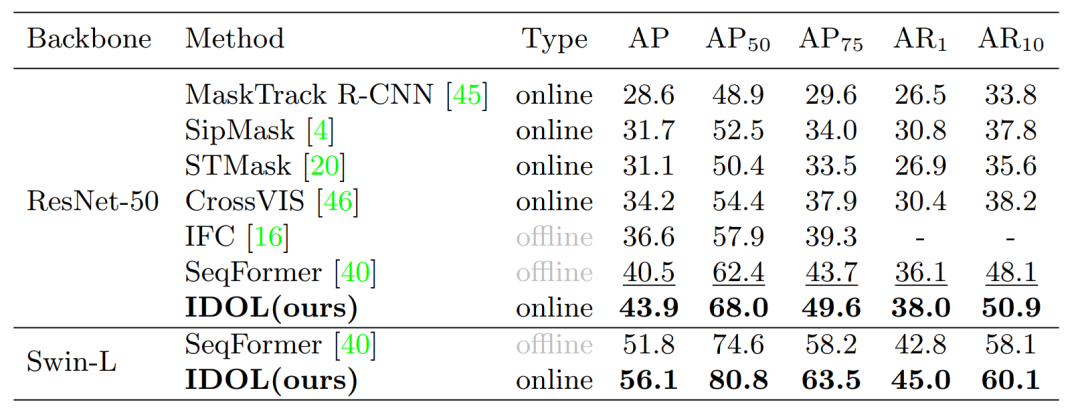
Table3: Comparison on OVIS 2021 val set
五、conclusion
Online VIS 方法在处理长时间/持续视频方面具有其固有的优势,但它们在性能上显著落后于 offline 模型,这项工作旨在弥补性能差距。文章首先深入分析当前的 online 和 offline 模型,发现差距主要来自帧之间的匹配。基于这一观察,文章提出了 IDOL,它使模型能够为 VIS 任务学习更具辨别力和鲁棒性的实例特征。它显着优于所有 online 和 offline 方法,并在所有三个数据集中取得了最新的SOTA结果。同时IDOL也在CVPR 2022 的 VIS workshop 中取得了第一名。期待该文章对当前 VIS 方法的分析可以为未来 online 和 offline 方法的工作提供帮助。
六、1st Place Solution for YouTubeVOS Challenge 2022: Video Instance Segmentation
在CVPR2022 workshop举办的第四届大规模视频物体分割挑战赛的视频实例分割赛道上,以IDOL作为baseline的方法取得了比赛的第一名,并超越了第二4.9%,这也证明了IDOL在各种场景下的优越性。具体参赛方案参见报告:https://youtube-vos.org/assets/challenge/2022/reports/VIS_1st.pdf。
作者:吴俊峰
Illustration by Pixeltrue from icons8
点击进入—> CV 微信技术交流群
CVPR 2022论文和代码下载
后台回复:CVPR2022,即可下载CVPR 2022论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
图像分割交流群成立
扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如图像分割+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信: CVer6666,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看