文章目录
一、线性规划简介
线性规划(Linear Programming)是运筹学中数学规划的一个重要分支。自从 1947 年 G. B. Dantzig 提出求解线性规划的单纯形法以来,线性规划在理论上趋向成熟,在实用中由于计算机能处理成千上万个约束条件和决策变量的线性规划问题之后,线性规划变成现代管理中经常采用的基本方法之一。 在解决实际问题时,需要把问题归结成一个线性规划数学模型,关键及难点在于选适当的决策变量建立恰当的模型,这直接影响到问题的求解。
二、线性规划常用求解方法
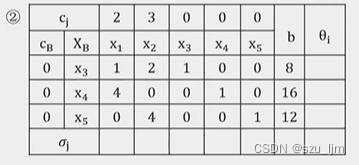
单纯形法是求解线性规划问题最常用、最有效的算法之一。满足线性规划问题约束条件的所有点组成的集合就是线性规划的可行域,单纯形法的基本想法是从线性规划可行域的某一个顶点出发,沿着使目标函数值下降的方向寻求下一个顶点,面顶点个数是有限的,所以,只要这个线性规划有最优解,那么通过有限步迭代后,必可求出最优解。
为了用迭代法求出线性规划的最优解,需要解决以下三个问题 :
最优解判别准则,即迭代终止的判别标准
换基运算,即从一个基可行解迭代出另一个基可行解的方法
进基列的选择,即选择合适的列以进行换基运算,可以使目标函数值有较大下降 。
简单来说,我们根据标准化后的线性方程组构建单纯形表,通过一些矩阵变换处理后,判断检验数的正负,若全部检验数小于等于0则表示此时求出的解即为最优解,否则不是最优解。若不是最优解的话要重新选取新的基变量,迭代到最终满足所有的检验数均不大于0
三、线性规划实现流程
1. 明确问题和变量
拿到一道可以用线性规划来解决的问题,首先我们要明确线性规划的几大要素:决策变量,目标函数,约束条件,特别是当条件和问题多起来后不进行清晰的要素分析会很容易出错,下面假设有一道投资和最大收益的问题

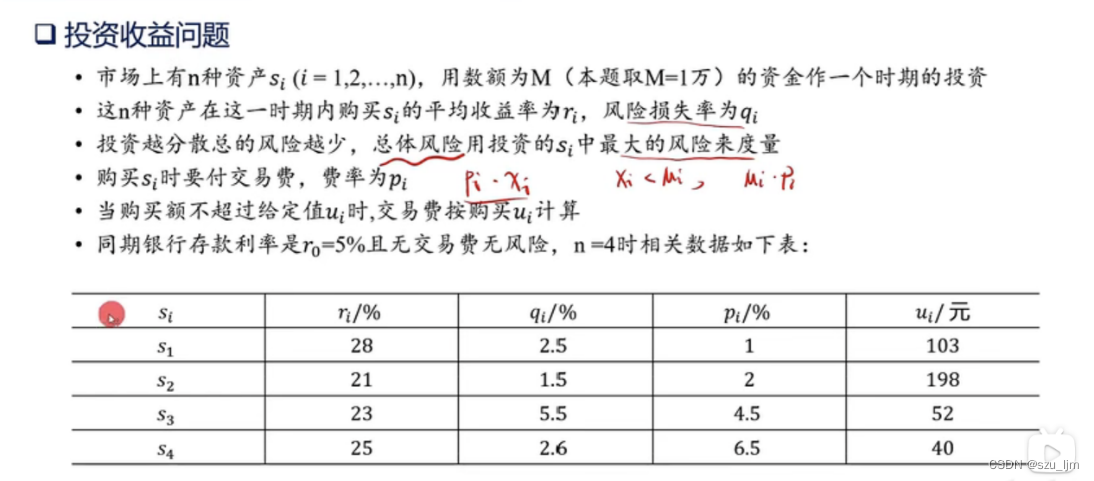
对于上述问题,我们的目标函数是使得收益最大化并且总体风险最小化,在投资资产一定的情况下,总收益就却取决于每种资产的投资金额、收益率和费率,总风险就取决于每种资产的投资金额、投资资产种类数和损失率。但为了简化模型的需要,我们可以将总风险最小化转化为针对不同人群的最小风险率,即该人群可以接受的最大损失。
决策变量主要是每种资产的投资金额,因为每类投资的收益率、费率、损失率都是一定的,我们也通过转化将目标函数转化为约束条件,最终约束条件是总投资金额为定值,每类投资的金额都为正值,总风险率低于某个定值
2. 建立数学模型
我们假设总收益函数为 Q Q Q,每个项目投资的资金为 X i X_{i} Xi,每个项目的平均收益率为 r i r_{i} ri,每个项目的平均风险损失率为 q i q_{i} qi,每个项目的费率为 p i p_{i} pi,还有我们在模型假设是可以说明投资金额 M M M 远大于 u i u_{i} ui来规避分类讨论的情形,下面是目标函数的表达式
max Q = max ∑ i = 0 4 ( r i − p i ) X i \max Q = \max \sum_{i=0}^4 (r_{i} - p_{i}) X_{i} maxQ=maxi=0∑4(ri−pi)Xi
下面是几个约束条件的数学表达式,其中最小风险率我们用平均损失率和每类项目的投资金额的乘积和总投资金额的比来衡量
q i X i M < = a , a 为某个特定的最小风险率 \frac{q_{i} X_{i}}{M} <= a,a为某个特定的最小风险率 MqiXi<=a,a为某个特定的最小风险率
∑ i = 0 4 ( 1 + p i ) X i = M \sum_{i=0}^4(1+p_{i}) X_{i} = M i=0∑4(1+pi)Xi=M
X i > = 0 , i = 0 , 1 , 2 , 3 , 4 X_{i} >= 0 , i=0,1,2,3,4 Xi>=0,i=0,1,2,3,4
上面就是我们简化后的数学模型,如果不对模型进行简化将总风险最小化的目标函数转化风险率小于某个值,我们就要解决表达式 min ( max 1 < = i < = 4 ( q i X i ) ) \min{(\max_{1<=i<=4} (q_{i} X_{i}))} min(max1<=i<=4(qiXi)) ,这个目标函数求解显然十分复杂
四、 Python实现线性规划
利用Python实现线性规划需要用到numpy和scipy库,再利用matplotlib来做数据可视化。其中scipy库需要导入optimize模块,通过该模块的linprog函数实现线性规划求解,linprog函数需要几个参数:目标函数,不等式系数矩阵,等式系数矩阵,决策变量范围等,linprog默认是求最小值,所以需要取负系数矩阵求出最大值的负数然后再加个负号,下面呈上代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy import optimize
#构建关于收益率、费率、损失率的矩阵
r_i = np.array([0.05,0.28,0.21,0.23,0.25])
q_i = np.array([0.00,0.025,0.015,0.055,0.026])
p_i = np.array([0.00,0.01,0.02,0.045,0.065])
beq = np.array([10000])
data = np.zeros(50)
#构建等式和不等式的系数矩阵
arr1 = r_i - p_i
aeq = (p_i + 1).reshape(1,5)
arr3 = np.zeros(20).reshape(4,5)
for i in range(1,5):
arr3[i-1][i] = q_i[i]/beq
arr4 = np.zeros(4).reshape(1,4)
print(arr1)
print('\n')
print(aeq)
print('\n')
print(arr3)
print('\n')
#针对不同风险率求其最优解
for i in range(0,50):
arr4 += 0.01
res = optimize.linprog(-arr1,A_ub=arr3,b_ub=arr4,A_eq=aeq,b_eq=beq)
print(res.fun)
data[i] = res.fun
# 最大收益关于风险率的数据可视化
plt.figure(figsize=(30, 30), dpi=100)
x1 = np.linspace(0, 0.5, 50)
plt.plot(x1, -data, 'r--', marker='*')
plt.show()
#/usr/bin/python3.8 /home/ljm/PycharmProject/pythoncode1/code5.py
[0.05 0.27 0.19 0.185 0.185]
[[1. 1.01 1.02 1.045 1.065]]
[[0.0e+00 2.5e-06 0.0e+00 0.0e+00 0.0e+00]
[0.0e+00 0.0e+00 1.5e-06 0.0e+00 0.0e+00]
[0.0e+00 0.0e+00 0.0e+00 5.5e-06 0.0e+00]
[0.0e+00 0.0e+00 0.0e+00 0.0e+00 2.6e-06]]
-2190.1960784313724
-2517.6470588235297
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
-2673.2673267326736
#Process finished with exit code 0

五、 非线性规划简介
非线性规划是一种求解目标函数或约束条件中有一个或几个非线性函数的最优化问题的方法,是运筹学的一个重要分支。20世纪50年代初,库哈(H.W.Kuhn) 和托克 (A.W.Tucker) 提出了非线性规划的基本定理,为非线性规划奠定了理论基础。这一方法在工业、交通运输、经济管理和军事等方面有广泛的应用,特别是在“最优设计”方面,它提供了数学基础和计算方法,因此有重要的实用价值。
六、 非线性规划常用求解方法
非线性规划和线性规划两种基本模型的最大区别在于,线性规划可以通过单纯形法求得最优解,且最优解一定会出现在顶点或者边缘;而非线性规划难以求出最优解,一般都为近似解,且最优解一般不在顶点边缘,也会出现在内部,这是非线性规划的难点
1. 拉格朗日乘数法
在数学最优问题中,拉格朗日乘数法(以数学家约瑟夫·路易斯·拉格朗日命名)是一种寻找变量受一个或多个条件所限制的多元函数的极值的方法。这种方法将一个有n 个变量与k 个约束条件的最优化问题转换为一个有n + k个变量的方程组的极值问题,其变量不受任何约束。这种方法引入了一种新的标量未知数,即拉格朗日乘数:约束方程的梯度(gradient)的线性组合里每个向量的系数
下面以二元目标函数和形式为等式的约束条件函数为例,用拉格朗日乘数法需先构建约束条件和函数的方程组
L ( x , y ) = f ( x , y ) + λ g ( x , y ) L(x,y) = f(x,y) + \lambda g(x,y) L(x,y)=f(x,y)+λg(x,y)

然后分别对 L ( x , y ) L(x,y) L(x,y) 关于变量 x x x , y y y 和 λ \lambda λ 求偏导并使所求得的偏导都为 0 0 0 ,求偏导为0的操作就等价于两个函数的梯度成比例,也就是两个函数的方向导数共线,此时两个方向导数就不会存在额外的分量来对目标函数最优解产生影响,所以此时求得为最优解
∂ L ∂ x = 0 \frac{\partial L}{\partial x} =0 ∂x∂L=0
∂ L ∂ y = 0 \frac{\partial L}{\partial y} =0 ∂y∂L=0
∂ L ∂ λ = 0 \frac{\partial L}{\partial \lambda} =0 ∂λ∂L=0

然后解方程可以求得驻点的 x x x , y y y , λ \lambda λ值,再代入目标函数即可求得最优解。通俗的理解,当一个人沿某个固定的路径爬山时想爬到最高点,只有当你的运动方向和山的梯度方向共线时,你才可以判断自己达到最高点,因为此时相对于山你不会再产生向上的位移,否则你还可以往上爬。
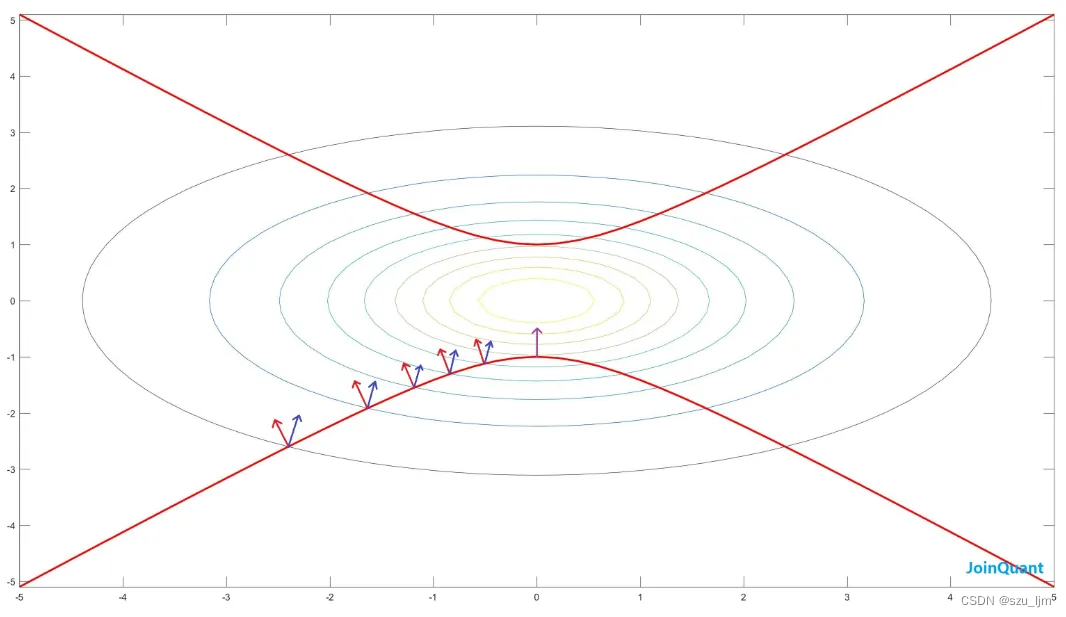
2. 梯度下降法
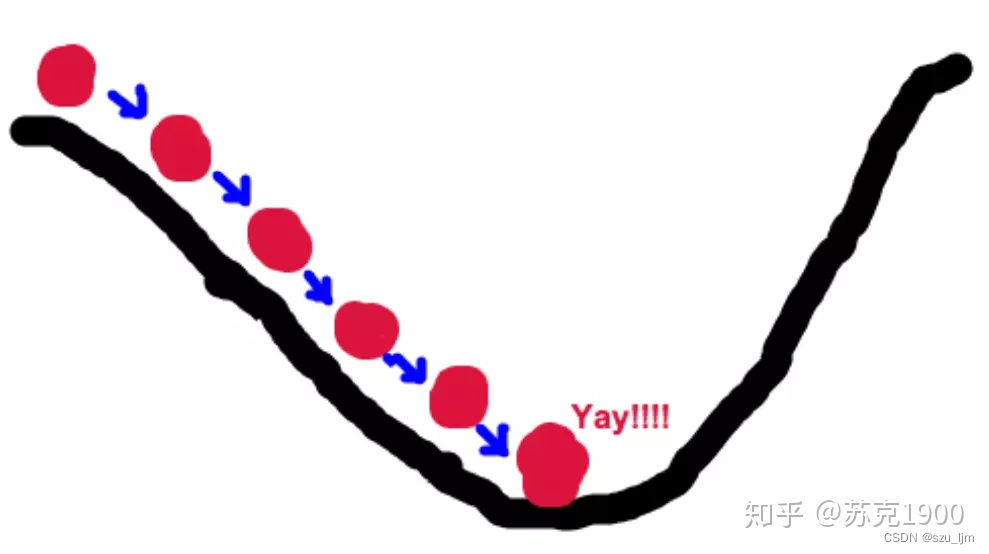
梯度下降方法可以说是机器学习中最耳熟能详的一种优化方法,它广泛应用于各种损失函数的优化上,它的迭代形式是: x k + 1 = x k − a k ∇ f ( x k ) x^{k+1} = x^{k} - a_{k}\nabla f(x^{k}) xk+1=xk−ak∇f(xk) ,这是一种很朴素的负梯度更新方法。
梯度下降法的优化思想是用当前位置负梯度方向作为搜索方向,因为该方向为当前位置的最快下降方向,所以也被称为是”最速下降法“。当搜索靠近最优值的时候,搜索的速度明显减缓,这会造成多次迭代,消耗计算资源,为了解决迭代次数过多速度过慢的问题,可以尝试随机梯度下降和批量梯度下降的优化方式。
批量梯度下降(BGD)
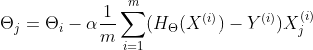
随机梯度下降(SGD)

批量梯度下降每次更新参数时都要动用所有样本数据,当样本量巨大时,这种更新方式虽然收敛效果好,但往往会非常缓慢。而相应的随机梯度下降则是每次更新只采用一个样本数据,这样一来可以大大加快更新速度,但同时也会面临收敛方向不直接,其梯度搜索的方向往往是来回扭曲的
七、 非线性规划实现流程
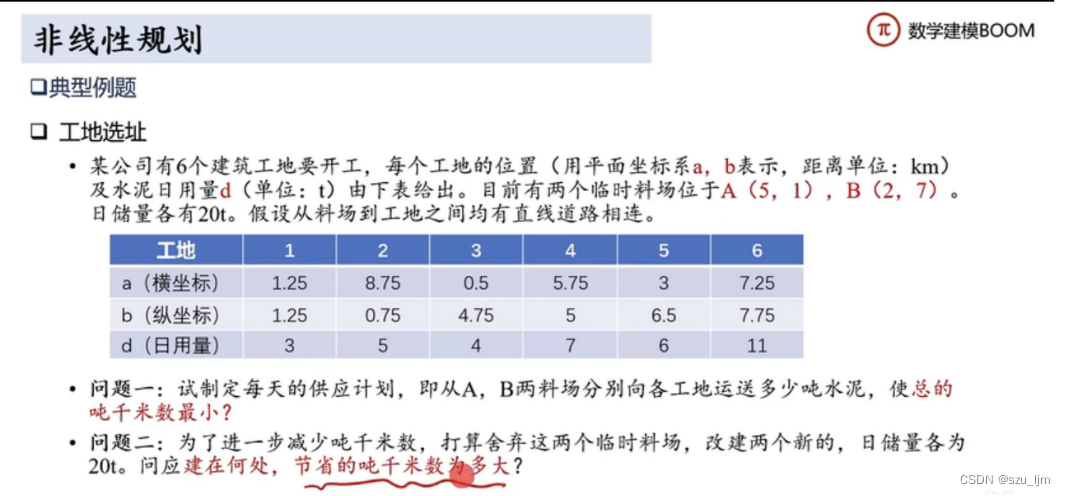
1. 明确问题和变量
上述非线性规划问题中一共有两大问题,问题呈现递进式层次,对于第一个问题,工地的坐标和料场的坐标都是已知量,所以只要规划决策不同的工地由料场运送水泥的量即可,因为不一定是离该工地最近的料场一次运完该工地所需水泥量的决策方案是最佳的,还要考虑该料场是追求往近的工地多运还是往尽可能多的工地运的最划算的情况等等,决策变量是单次运送水泥量,目标函数就是求运送量和路程乘积的最小值,约束条件是运送水泥总量满足工地日常需求,运送水泥总量不超过料场日储量

第二个问题则更加复杂,需要求解在未知位置下的料场运输水泥总吨量和距离乘积的最值,决策变量是单次运送水泥量和料场的坐标,目标函数就是求运送量和路程乘积的最小值,约束条件是运送水泥总量满足工地日常需求,运送水泥总量不超过料场日储量
2. 建立模型

我们主要对第二个问题进行建模求解,假设 X i j X_{ij} Xij表示单次运送水泥量, x j x_{j} xj表示料场的横坐标, y j y_{j} yj表示料场的纵坐标,目标函数 f f f表达式为
min f = min ∑ j = 1 2 ∑ i = 1 6 X i j ( x j − a i ) 2 + ( y j − b i ) 2 \min{f} = \min{ \sum_{j=1}^2{\sum_{i=1}^6}{X_{ij}\sqrt{(x_{j} - a_{i})^{2} + (y_{j} - b_{i})^{2}}}} minf=minj=1∑2i=1∑6Xij(xj−ai)2+(yj−bi)2
约束条件表面上只有两个,但转化成程序后需要拆成8个约束条件,一共16个决策变量
∑ i = 1 6 X i j < = e j , j = 1 , 2 \sum_{i=1}^6{X_{ij}} <= e_{j},j = 1,2 i=1∑6Xij<=ej,j=1,2
∑ j = 1 2 X i j = d i , i = 1 , 2 , 3 , 4 , 5 , 6 \sum_{j=1}^2{X_{ij}} = d_{i},i= 1,2,3,4,5,6 j=1∑2Xij=di,i=1,2,3,4,5,6
八、 Python实现非线性规划
Python实现非线性规划的方法用很多种,每种方法都有自己的局限,我们这里用scipy库的optimize模块进行操作,该模块进行非线性规划时需要给定初始化的预测值,而初始的预测值也会影响最后的最优化解,这也是该模块的弊端,我们也可以用蒙特卡罗法进行优化,蒙特卡罗法主要核心是大数定理,当试验次数足够多的时候将试验所得的样本数据分布看作总体样本数据的分布,可以统计不同的预测值输入最后统计最优解分布来逼近最优解
import numpy as np
from scipy.optimize import minimize
func = 0
args1 = [[1.25,1.25],[8.75,0.75],[0.5,4.75],[5.75,5],[3,6.5],[7.25,7.75]]
# 目标函数和参数
def objective(args):
global func
loc_1 = args
i = 0
j = 0
func = lambda x: sum(x[2*i+j] * (((x[12+2*j]-loc_1[i][0]) ** 2 + (x[13+j*2]-loc_1[i][1])) ** 1/2)for i,j in zip (range(6),range(2)))
return func
args2 = [20, 20, 3, 5, 4, 7, 6, 11]
def con(args):
# 约束条件 分为eq 和ineq
# eq表示表达式结果等于0 ; ineq 表示表达式大于等于0
b1, b2, d1, d2, d3, d4, d5, d6 = args
cons = ({
'type': 'ineq', 'fun': lambda x: -x[0] - x[2] - x[4] - x[6] - x[8] - x[10] + b1}, \
{
'type': 'ineq', 'fun': lambda x: -x[1] - x[3] - x[5] - x[7] - x[9] - x[11] + b2}, \
{
'type': 'eq', 'fun': lambda x: -x[0] - x[1] + d1}, \
{
'type': 'eq', 'fun': lambda x: -x[2] - x[3] + d2}, \
{
'type': 'eq', 'fun': lambda x: -x[4] - x[5] + d3}, \
{
'type': 'eq', 'fun': lambda x: -x[6] - x[7] + d4}, \
{
'type': 'eq', 'fun': lambda x: -x[8] - x[9] + d5}, \
{
'type': 'eq', 'fun': lambda x: -x[10] - x[11] + d6})
return cons
cons = con(args2)
#设置初始预测值
x0 = np.array([1, 2, 1, 4, 1, 3, 1, 6, 1, 5, 1, 10, 3, 3, 5, 5])
# 计算
solution = minimize(objective(args1), x0, method='SLSQP', constraints=cons)
x = solution.x
print(solution)
print('\n')
print('最优解 = ' + str(solution.fun))
print('料场1横坐标 = ' + str(x[12]))
print('料场1纵坐标 = ' + str(x[13]))
print('料场2横坐标 = ' + str(x[14]))
print('料场2纵坐标 = ' + str(x[15]))
#/usr/bin/python3.8 /home/ljm/PycharmProject/pythoncode1/code6.py
message: Inequality constraints incompatible
success: False
status: 4
fun: -8330466284030726.0
x: [-4.565e+04 4.565e+04 ... 3.222e+05 -2.365e+04]
nit: 4
jac: [ 3.355e+08 0.000e+00 ... -5.161e+10 0.000e+00]
nfev: 68
njev: 4
最优解 = -8330466284030726.0
料场1横坐标 = -24603.887006224133
料场1纵坐标 = -7864.964381965315
料场2横坐标 = 322189.52738244593
料场2纵坐标 = -23652.50564799086
#Process finished with exit code 0
总结
以上就是今天笔记的内容,本文简单介绍了线性规划和非线性规划的总体实现思路和求解方法,线性规划和非线性规划在数学建模和机器学习中被广泛地应用,特别适合一些最优化方案的求解,线性规划和非线性规划的模型也有自身的局限性,总之善于利用不同模型的优势才能更加彻底的剖析事物背后的数学逻辑。