一、金融情绪分析语料库
按开放方式不同数据集(datase)可以分为公开数据集和(公开 私有(人)数据集。开数据集一般由研究所比赛举办方公共机构公开发布协算法建模研究用于模型评测结果比较和复现;使用公开数据集得出的结论往往更具说服力,便于审稿人对公开发表论文的评审,容易得到业内人士的认可。成为业内公开评测模型性能的基准数据集(benchmark dataset),从而得到当前最佳模型排行榜,数据使用者必须遵守数据集所有者的协议要求。公开数据集的缺点是尽管已经进行脱敏处玛来保护个人隐私安全,但仍要避免隐私攻击(恶意攻击者可以发现公开数据集中看似名或随机采样的信息链接到特定的个人);而且,公开数据集不可能覆盖所有应用领域,无法满足所有研究问题的需求,比如特定领域文本或限定条件下的标注或分析等,因此在很多分支领域的应用时仍然需要特定的私有数据集
语料库(corpus,复数形式corpora)是自然语言处理和语料库语言学(corpus Linguistics)领域的数据集,指在为特定的应用目标而对真实出现过的语言材料专门收集加工、可被计算机程分析的文本或文档集合数据结构类型一般都是非结构化数据或半结构化数据。在自然语言处理实践中,大多数情况下,语料库的选择决定了任务的成败。常用的情绪分类评测基准语料库有:英文情绪语料库有斯坦福情绪树库-情绪二分类(Stanford Sentiment Treebankbinary sentiment classification.SST-2)康奈尔大学庞博提供的影评语料库(movie reviewdata),互联网电影资料库电影评论语料库(Internet Movie DataBaseIMDB)、国际语义评测大会-2014(international workshop on Semantic Evaluation-2014,SemEval-2014)任务4方面级情绪分析笔记本电脑和餐厅特定领域、子任务2方面词语级情绪极性分类、子任务4方面类别级情绪极性分类语料库、任务9推特情绪分析语料库、Yelp美国商户点评网站餐厅评论语料库、国际语义评测大会-2016任务5方面级情绪分析笔记本电脑、餐厅和酒店特定领域评论语料库城市社区问答平台方面级对象抽取语料库SentiHood、亚马逊笔记本电脑评论语料库数百万条亚马逊客户评论(输人文本)和星级评级(输出标签)数据集、包含正负向、性、显/隐式表达、讽刺等多视角情绪语料库、金融短语库(Financial PhraseBank)、分报告文本(analyst reporttext)金融意见挖掘和问答2018面级金融绪分(FiQA 2018 Task1)数据集,等等;中文情绪语料库有第一至第八届中文倾向性分评测的语料库(the first to eighth Chinese Opinion Analysis Evaluation,COAE00
英文情绪分析语料库

中文情绪分析语料库

原始内容上的中文金成财经两地真t金限新闻(上公司票新的主标题这些网站包括金融牌(https证网htp cm)和讯网htxuhwfcn)为2018-2020年整理去重并保存为每行一个句子,无空行(onesentenceper-ime without emty limes)的一个文本文件。
第二、标注数据、选取部分采集数据、使用人工标注方法、手动将每条新闻主标题妇人“利多(看涨)、“利空”(看跌)和“其他(持平)三种不同类别的情结,在每个标题的标注类别许期特殊符号1分隔、
第三、保留少量操作误差、主观误差或脏数据(不究整、含噪声、不一致的数据)、真实的标注数据集往住是不完美的、存在人为造成的误解,误读,误算或者没有意义的数据、本语料库中包含非金融领城的新闻主标题、与金融知识不相关的词和符号(例如[快讯【图解】(2019))空格或未标注的语料。
该评测标注语料库(表31)必须是目标域小样本(fewshot)或处于少资源(low resource)情景、符合金融领城高质量的标注数据十分稀缺的真实情景,这也是当前自然语言处理研究重点关注的领域。同时,避免样本单一、得出结论不牢固。虽然,该语料库来自互联网公开数据、不涉及国家秘密、商业秘密、个人隐私和他人知识产权或他合法权利问题
二、描述统计分析
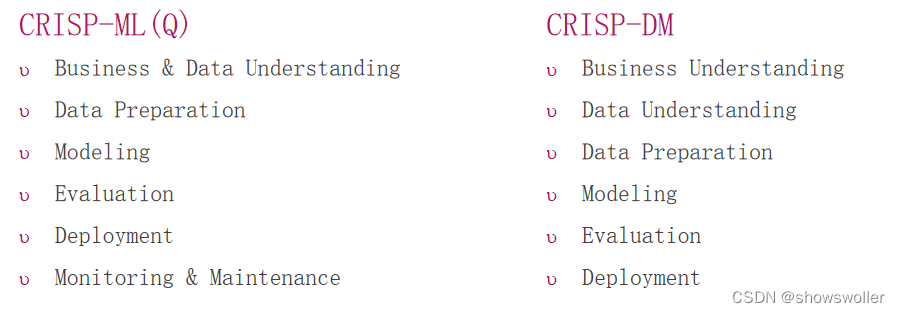
具有质量保证方法的跨行业机器学习标准流程
金融情绪类别

类别平衡
