1 计算机视觉应用
计算机视觉是一种利用计算机和数学算法来模拟人类视觉的技术,可以应用于许多领域。以下是计算机视觉的八大应用:
- 图像识别:利用计算机视觉技术,可以对图像进行分类、识别和分割,从而实现自动化的图像处理。
- 视频监控:利用计算机视觉技术,可以对视频进行实时监控和分析,从而实现对安全和环境的监控。
- 人脸识别:利用计算机视觉技术,可以对人脸进行识别和分析,从而实现身份验证和安全控制。
- 视觉导航:利用计算机视觉技术,可以对场景进行三维重建和定位,从而实现自动驾驶和机器人导航。
- 医学影像分析:利用计算机视觉技术,可以对医学影像进行分析和诊断,从而实现精准医疗和疾病预防。
- 智能交通:利用计算机视觉技术,可以对交通流量进行监测和管理,从而实现交通拥堵的缓解和交通安全的提升。
- 智能家居:利用计算机视觉技术,可以对家居环境进行监测和控制,从而实现智能化的家居管理。
- 虚拟现实:利用计算机视觉技术,可以对虚拟环境进行建模和渲染,从而实现沉浸式的虚拟现实体验。
2 计算机视觉任务
- 物体检测(目标检测):用于零售或医学
- 线/边缘检测:用于制造业
- 图像分割:用于自动驾驶汽车
- 姿态预测/关键点识别:用于情绪检测
- 图像分类:用于图像类别划分
3 不同视觉任务训练数据的标注技术
要完成计算机视觉的任务,就需要建立并训练出一个模型,用这个训练出的模型进行完成上面的视觉任务。但训练这个模型需要数据,而数据往往是图片,并且这些图片需要进行人工标注,并给出这些图片的语义标签,如下图

3.1 目标检测
对于目标检测类图片数据进行标注
进行目标检测的技术主要有两种,即2D和3D包围框。
3.1.1 2D 包围框
在这种方法中,只需要在被检测的物体周围绘制矩形框。它们用于定义对象在图像中的位置。边框可以由矩形左上角的x、y轴坐标和右下角的x、y轴坐标来确定。

优点和缺点:
- 标注起来快速和容易。
- 不能提供重要的信息,如物体的方向,这对许多应用来说是至关重要的。
- 包括不属于物体一部分的背景像素。这可能会影响训练。
3.1.2 3D包围框或者立方体
类似于2D边框,除了它们还可以显示目标的深度。这种标注是通过将二维图像平面上的边界框向后投影到三维长方体来实现的。它允许系统区分三维空间中的体积和位置等特征。

优点和缺点:
- 解决了物体方向的问题。
- 当物体被遮挡,这种标注可以想象包围框的维度,这可能会影响训练。
- 这种标注也会包括背景像素,可能会影响训练。
3.1.3 多边形
有时,必须标记形状不规则的物体。在这种情况下,使用多边形。注释时只需标记物体的边缘,我们就能得到要检测的物体的完美轮廓。

优点和缺点:
- 多边形标记的主要优点是它消除了背景像素,并捕获了物体的精确尺寸。
- 非常耗时,如果物体的形状是复杂的,很难标注。
3.2 线/边缘检测(线和样条)
对于边缘检测类图片数据进行标注
在划分边界时,线和样条是有用的。将区分一个区域和另一个区域的像素进行标注。

优点和缺点:
- 这种方法的优点是,连线上的像素不需要都是连续的。这样在检测有中断的线或部分遮挡的物体是非常有用的。
- 手动标注图像中的线是非常累人和费时的,特别是图像中有很多的线的时候。
- 当物体碰巧是对齐的时候,可能会给出误导的结果。
3.3. 姿态预测 / 关键点识别
对人体的姿势或者人脸的识别等图片进行数据标注
在许多计算机视觉应用中,神经网络常常需要识别输入图像中重要的感兴趣的点。我们把这些点称为地标或关键点。在这种应用中,我们希望神经网络输出关键点的坐标(x, y)。

3.4. 分割
对连续图像进行图像标注
图像分割是将一幅图像分割为多个部分的过程。图像分割通常用于在像素级定位图像中的物体和边界。图像分割方法有很多种。
- 语义分割: 语义分割是一项机器学习任务,它需要像素级标注,其中图像中的每个像素都被分配给一个类。每个像素都带有语义意义。这主要用于环境背景非常重要的情况。
- 实例分割: 实例分割是图像分割的一种子类型,它在像素级别上标识图像中每个物体的每个实例。实例分割和语义分割是图像分割的两种粒度级别之一。
- 全景分割: 全景分割结合了语义分割和实例分割,所有像素都被分配一个类标签,所有目标实例都被唯一地分割。

3.5. 图像分类
对需要分类的图片进行标注,使用候选框+文字
图像分类分为两种:
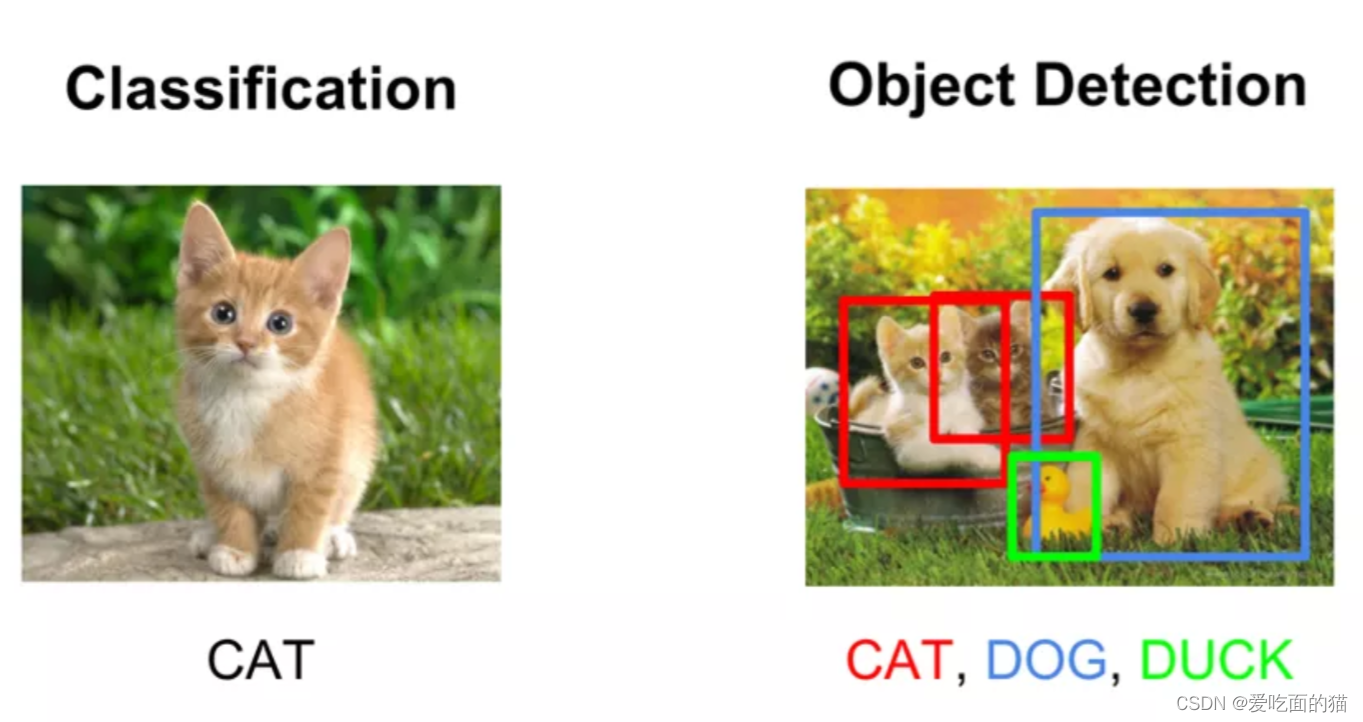
- 1、单一的图像进行分类,如下图左侧,判断是否是猫。
- 2、复杂的图像进行分类,如下图右侧,需要先进行图像的识别,识别后再进行分类。
因此图像分类不同于目标检测。目标检测的目的是识别和定位目标,而图像分类的目的是识别和定位目标,并进行目标分类。这个用例的一个常见示例是对猫和狗的图片进行分类。标注者必须为一只狗的图像分配一个类标签“dog”,对猫的图像分配类标签“cat”。
4 视觉任务应用
4.1 物体检测(目标检测)
应用于零售业和医学
- 零售: 目标检测中的2D边框可以用于标注产品的图像,然后机器学习算法可以使用这些图像来预测成本和其他属性。图像分类在这方面也有帮助。
- 医学:目标检测中的多边形可用于在医用x射线中标记器官,以便将它们输入深度学习模型,以训练x射线中的畸形或缺陷。这是图像标注最重要的应用之一,需要医学专家具有较高的领域知识。
4.2 线/边缘检测
边缘检测应用于制造业
- 制造行业: 线和样条可用于标注工厂的图像线跟随机器人工作。这可以帮助自动化生产过程,人力劳动可以最小化。
4.3 图像分割:
图像分割应用于自动驾驶汽车
- 自动驾驶汽车: 这是另一个重要的领域,图像标注可以应用。利用语义分割对图像中的每个像素进行标记,使车辆能够感知到道路上的障碍物。这一领域的研究仍在进行中。
4.4 姿态预测/关键点识别
应用于情绪检测或者人体姿势预测
- 情绪检测: 这是里程碑,可以用来检测一个人的情绪(高兴,悲伤,或自然)。这可以应用于评估受试者对特定内容的情绪反应。
4.5 图像分类
图像分类一般用于图像类别划分
总结:
图像标注在计算机视觉中起着至关重要的作用。图像标注的目标是为和任务相关的、特定于任务的标签。这可能包括基于文本的标签(类),绘制在图像上的标签(即边框),甚至是像素级的标签。
人工智能需要的人工干预比我们想象的要多。为了准备高精度的训练数据,我们必须对图像进行标注以得到正确的结果。数据注释通常需要较高水平的领域知识,只有来自特定领域的专家才能提供这些知识。