一、阈值处理
由于阈值处理直观、实现简单且计算速度快,因此图像阈值处理在图像分割应用中处于核心地位。
1. 基础知识
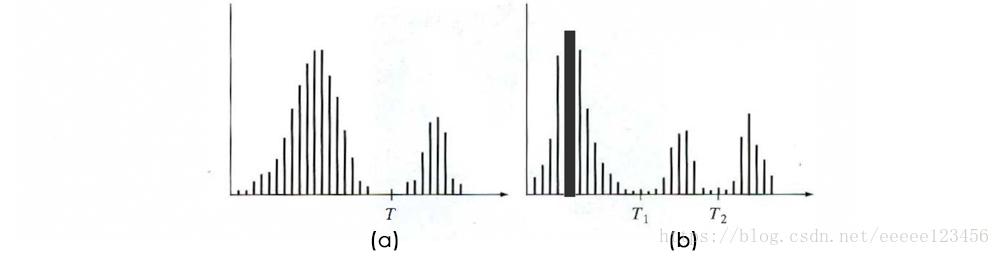
假设图1(a)中的灰度直方图对应于图像
,该图像由暗色背景上的较亮物体组成,以这样的组成方式,物体像素和背景像素所具有的灰度值组成了两种支配模式。从背景中提取物体的一种明显方法是,选择一个将这些模式分开的阈值
。然后,
的任何点
称为一个对象点;否则该点称为背景点。分割后的图像
由下式给出:
当
是一个适用于整个图像的常数时,上式给出的处理称为全局阈值处理。当
值在一幅图像上改变时,我们把该处理称为可变阈值处理(局部阈值处理或区域阈值处理有时用于表示可变阈值处理)。若
取决于空间坐标
本身,则可变阈值处理通常称为动态阈值处理或自适应阈值处理。
图1(b)显示了一个更为困难的阈值处理问题,它包含有三个支配模式的直方图。分割的图像由下式给出:
式中,a、b和c是任意三个不同的灰度值。
2. 基本的全局阈值处理
当物体和背景像素的灰度分布十分明显时,可以用适用于整个图像的单个(全局)阈值。能对每幅图像自动估计阈值的算法如下:
① 为全局阈值
选择一个初始估计值。
② 在式(1)中用
分割该图像。这将产生两组像素:
由灰度值大于
的所有像素组成,
由所有小于等于
的像素组成。
③ 对
和
的像素分别计算平均灰度值(均值)
和
。
④ 计算一个新的阈值:
⑤ 重复步骤2到步骤4,直到连续迭代中的
值间的差小于一个预定义的参数
为止。
通常,
越大,则算法执行的迭代次数越少。所选的初始阈值必须大于图像中的最小灰度级而小于最大灰度级。图像的平均灰度对于
来说是较好的初始选择。
3. 用Otsu方法的全局阈值处理
令
表示一幅大小为
像素的数字图像中的
个不同的灰度级,
表示灰度级为
的像素数。图像中的像素总数为
。归一化的直方图具有分量
。由此有
假设使用阈值把输入图像处理为两类
和
,Ostu算法如下:
① 计算输入图像的归一化直方图。使用
,
表示该直方图的各个分量。
② 使用
对于
,计算累积和
。
③ 使用
对于
,计算累积均值
。
④ 使用
计算全局灰度均值
。
⑤ 使用
对于
,计算类间方差
。
⑥ 得到Otsu阈值
,即使得
最大的
值。如果最大值不唯一,用相应检测到的各个最大值
的平均得到
。
⑦ 在
处计算
得到可分性测度
,该测度可用于得到类别可分性的定量估计。
4. 用图像平滑改善全局阈值处理
噪声会将简单的阈值处理问题变为不可解决的问题。当噪声不能在源头减少,并且阈值处理又是所选择的分割方法时,通常能增强性能的一种技术是,在阈值处理之前平滑图像。
经平滑和分割后的图像,由于对边界的模糊,会造成物体和背景间的边界稍微有点失真。对一幅图像平滑越多,分割后的结果中的边界误差就越大。
5. 利用边缘改进全局阈值处理
表示输入图像,利用边缘改进全局阈值处理算法如下:
① 采用特征检测中讨论的任何一种方法来计算一幅边缘图像,无论是
梯度的幅度还是拉普拉斯的绝对值均可。
② 指定一个阈值
。
③ 用步骤2中的阈值对步骤1中的图像进行阈值处理,产生一幅二值图像
。在从
中选取对应于“强”边缘像素的下一步中,该图像用做一幅模板图像。
④ 仅用
中对应于
中像素值为1的位置的像素计算直方图。
⑤ 用步骤4中的直方图全局地分割
,例如使用Ostu 方法。
6. 多阈值处理
迄今为止,我们关注的是用单个全局阈值对图像进行分割。我们可将用Otsu方法的全局阈值处理扩展到任意数量的分类。在
个类
的情况下,类间方差可归纳为下面的表达式:
式中,
类由
个阈值分离,这些值
是式的最大值。
对于由三个灰度间隔组成的三个类(这三个类由两个阈值分隔),类间方差由下式给出:
式中,
两个最佳阈值
和
是使得
最大的值。阈值处理后的图像由下式给出:
式中,a、b和c是任意三个有效的灰度值。最后,为单个阈值定义的可分性测度可直接扩展到多个阈值:
7. 可变阈值处理
噪声和非均匀光照这样的因素的阈值处理算法的性能影响起着重要作用。前面说过,图像平滑和边缘信息的使用有益于阈值处理,然而,常常会出现这种情况,要么预处理不切实际,要么对这一情形的改进简单而无效。在这种情况下,更为高级且复杂的阈值处理涉及可变阈值问题。
① 图像分块
把一幅图像分成不重叠的矩形,选择的矩形要足够小,以便每个矩形的光照都近似是均匀的。最后对每个矩形进行阈值处理。
② 基于局部图像特性的可变阈值处理
与图像分块相比,更为一般的方法是在一幅图像中的每点
计算阈值,该阈值以一个或多个在
领域计算的特性为基础。令
和
表示一幅图像中以坐标
为中心的邻域
所包含的像素集合的标准差和均值。下面是可变局部阈值的通用形式:
式中,a和b是非负常数,且
其中,
是全局图像均值。分割后的图像计算如下:
式中,
是输入图像。该式对图像中的所有像素位置进行求值,并在每个点
处使用邻域
中的像素计算不同的阈值。

③ 使用移动平均
以上讨论的局部阈值处理的一种特殊情形,是以一幅图像的扫描行计算移动平均为基础的。通常,为减少光照偏差,扫描是以Z字姓模式逐行执行的。令
表示步骤
中扫描序列遇到的点的灰度。这个新点出的移动平均(平均灰度)由下式给出:
式中,
是用于计算平均的点数。因为对图像中的每个点都计算移动平均,因此用式实现分割,其中
,
是常数,
是在输入图像中的点
处使用式得到的移动平均。
8. 多变量阈值处理
在某些情况下,传感器可产生多个可利用的变量来表征图像中的每个像素,这样,就允许多变量阈值处理。最显著的例子就是彩色成像,其中红(R)、绿(G)、蓝(B)分量用于形成一幅合成彩色图像。在这种情况下,每个“像素”由三个值来表征,并且可以表示为一个三维向量
,其分量是一个点的RGB彩色。这些三维点通常称为体素,以便与图像元素相对应来表示体积元素。
多变量阈值处理可视为一种距离计算。计算任意彩色点
和平均彩色
间的距离测度
,我们按如下方式分割图像:
其中,
是一个阈值。根据n维欧几里得距离定义:
一种更有用的距离测度是所谓的马氏(Mahalanobis)距离,定义为:
其中,
是
的协方差矩阵。
二、基于区域的分割
本段讨论以直接寻找区域为基础的分割技术。
1. 区域生长
区域生长是根据预先定义的生长准则,将像素或子区域组合为更大区域的过程。基本方法是从一组“种子”点开始,将与种子预先定义的性质相似的那些邻域像素添加到每个种子上,来形成这些生长区域(如特定范围的灰度或颜色)。
令
表示一个输入图像阵列;
表示一个种子阵列,阵列中种子点位置处为1,其他位置处为0;
表示在每个位置
处所用的属性。假设阵列
和
的尺寸相同。基于8连接的一个基本区域生长算法如下:
① 在
中寻找所有连通分量,并把每个连通分量腐蚀为一个像素;把找到的所有这种像素标记为1,把
中的所有其他像素标记为0.
② 在坐标对
处形成图像
:若输入图像在该坐标处满足给定的属性
,则令
,否则令
。
③ 令
是这样形成的图像:即把
中为8连通种子点的所有1值点,添加到
中的每个种子点。
④ 用不同的区域标记标出
中的每个连通分量。这就是由区域生长得到的分割图像。
2. 区域分裂与聚合
区域分裂与聚合指,首先将一幅图像细分为一组任意的不相交区域,然后聚合和/或分裂这些区域,试图满足我们所需的分割条件。
令
表示整幅图像区域,并选择一个属性
。对
进行分割的一种方法是,依次将它细分为越来越小的四象限区域,以便对于任何区域
有
。具体过程如下:
① 把满足
的任何区域
分裂为4个不相交的象限区域。
② 不可能进一步分裂时,对满足条件
的任意两个邻域区域
和
进行聚合。
③ 无法进一步聚合时,停止操作。
三、用形态学分水岭的分割
1. 背景知识
形态学分水岭分割将前面讨论的分割方法中的许多概念进行了具体化,因此通常会产生更稳定的分割结果,包括连接的分割边界。
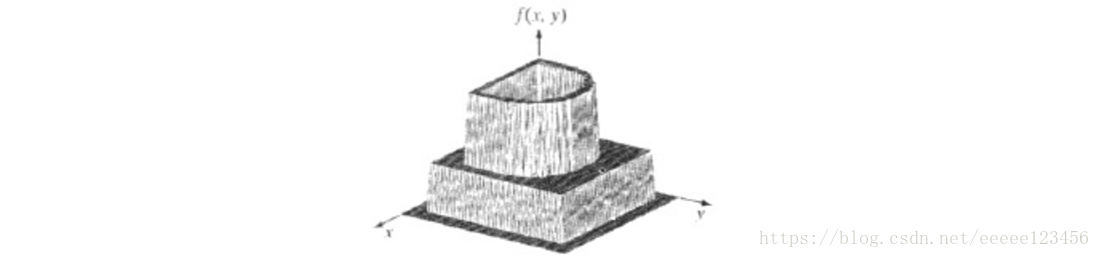
分水岭的概念是以三维方式来形象化一幅图像为基础的:两个空间坐标作为灰度的函数,如图2所示。在这种“地形学”解释中,我们考虑三种类型的点:
(a) 属于一个区域最小值的点;
(b) 把一点视为一个水滴,如果把这些点放在任意位置上,水滴一定会下落到某个最小值点;
(c) 处在该点的水会等概率地流向不止一个这样的最小值点。
对于一个特定的区域最小值,满足条件(b)的最小值点的集合称为该最小值的汇水盆地或分水岭。满足条件(c)的点形成地面的峰线,它称为分割线或分水线。
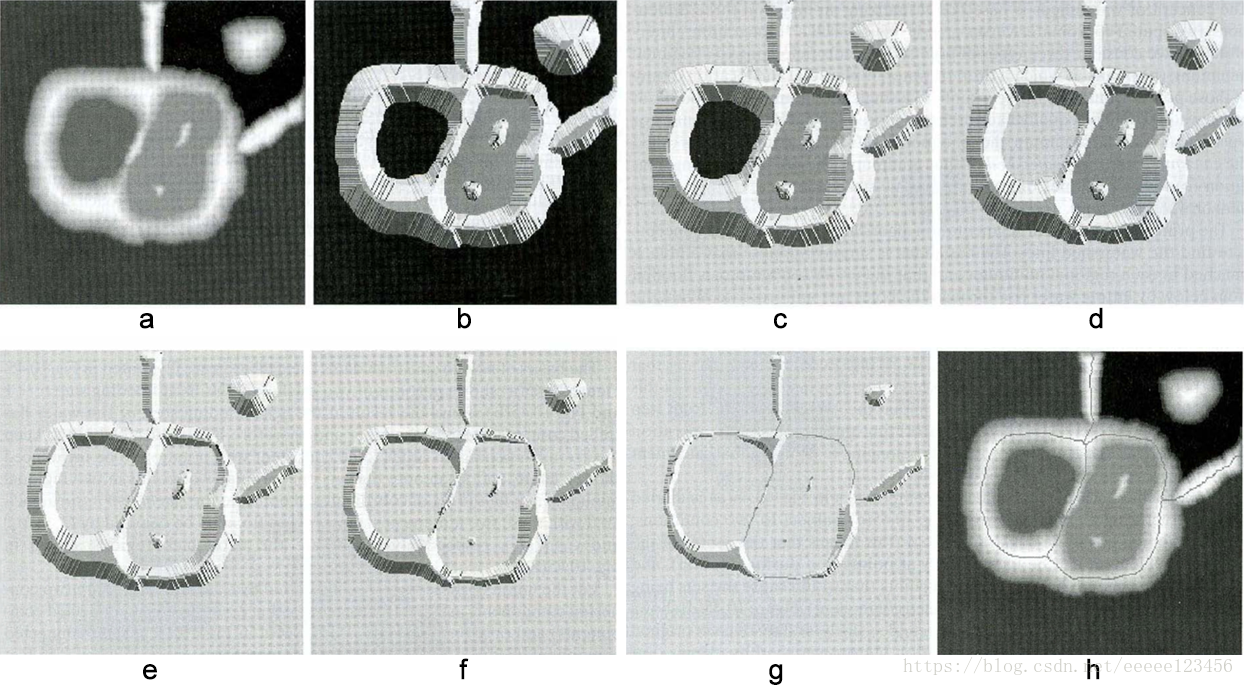
基于这些概念的分割算法的主要目标是找出分水线,其基本思想非常简单。假设在每个区域的最小值上打一个洞,并且让水通过洞以均匀的速率上升,从低到高淹没整个地形。当不同汇水盆地中上升的水聚集时,修建一个水坝来阻止这种聚合。水将达到在水线上只能见到各个水坝的顶部的程度。这些大坝的边界对应于分水岭的分割线。具体见图3。
分水岭分割的主要应用之一是,从背景中提取近乎一致的物体。由变化较小的灰度表征的区域有较小的梯度值。因此,我们经常见到分水岭分割方法用于一幅图像的梯度,而不是图像本身。
2. 分水岭分割算法
令
是梯度图像
中区域最小值点的坐标集。令
是与区域最小值
相关的汇水盆地中的点的坐标集。符号
和
表示
的最小值和最大值。最后,令
表示满足
的坐标
的集合,即:
令
表示汇水盆地中与淹没阶段
的最小值
相关联的点的坐标集,即:
接下来,令
表示阶段
中已被水淹没的汇水盆地的并集:
然后,令
表示所有汇水盆地的并集:
寻找分水线的算法使用
来初始化。然后,该算法进行递归处理,由
计算
。由
求得
的过程如下:令
表示
中的连通分量的集合。然后,对于每个连通分量
,有如下三种可能性:
①
为空集。
②
包含
的一个连通分量
③
包含
的一个以上的连通分量
由
构建
取决于这三个条件中的哪个条件成立。
遇到一个新的最小值时,条件①发生,这种情况下,连通分量
并入
中形成
。
当
位于某些局部最小值的汇水盆地内时,条件②发生,这种情况下,
并入
中形成
。
当遇到全部或部分分隔两个或多个汇水盆地的山脊线时,条件③发生。进一步淹没会导致这些汇水盆地中的水位聚合。因此,必须在
内构筑一个水坝(如果涉及两个以上的汇水盆地,就要构筑多个水坝)以阻止汇水盆地间的水溢出。
四、代码实现(Python+OpenCV)(未完,待续)
使用分水岭算法进行图像分割
import cv2
以上全部内容参考书籍如下:
冈萨雷斯《数字图像处理(第三版)》
Joe Minichino、Joseph Howse《OpenCV 3计算机视觉Python语言实现(原书第2版)》