计算机视觉任务概述
参考另外两个博客
https://blog.csdn.net/weixin_44523062/article/details/104577628
https://blog.csdn.net/weixin_44523062/article/details/104535650
总结一下CV的研究方向,对计算机视觉的任务做一下自己的概述。方便今后再根据CV各个研究方向的动态来进行更新。
系统阐述CV领域的课程、书籍
- 课程1:Li FeiFei CS231n 2019年 教学理念关注intuition thinking
- 课程2:叶梓 计算视觉深度学习实践 2017
- 书籍:计算机视觉 一种现代方法 第二版
文章目录
CV四大基本任务来自cs231n:分类、定位、检测、分割
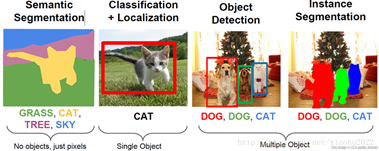
一、图像分类CNN+FC+softmax
- 任务:分类,input-Img–>output-label
- 方法:利用已标记的数据集–>提取特征–>训练分类器
Lenet1998、Alexnet2012、ZFnet2013、Vggnet2014、GoogleNet2014、Resnet2015、Densenet2016 - 数据集:Mnist手写数字、CIFAR10、Imagenet1000
MNIST 60k 训练图像、10k测试图像、10个类别、图像大小1×28×28。
CIFAR-10 50k 训练图像、10k测试图像、10个类别、图像大小3×32×32。
CIFAR-100 50k 训练图像、10k测试图像、100个类别、图像大小3×32×32。
ImageNet 1.2M 训练图像、50k验证图像、1k个类别。2017年及之前,每年会举行基于mageNet数据集的ILSVRC竞赛,这相当于计算机视觉界奥林匹克 - 应用:CV图像理解的基础,目标识别、目标分割做准备
- 评价:准确度:classification right-num/all-num
- 扩展分类器的种类:判别式、生成式(来源 cv一种现代方法) - 参考https://blog.csdn.net/u010358304/article/details/79748153

从概率分布的角度考虑,对于一堆样本数据,每个均有特征Xi对应分类标记yi。
- 生成模型:以统计学和Bayes作为理论基础。学习得到联合概率分布P(x,y),即特征x和标记y共同出现的概率,然后求条件概率分布。能够学习到数据生成的机制。
- 1、朴素贝叶斯 2、混合高斯模型 3、隐马尔可夫
- 判别模型:学习得到条件概率分布P(y|x),即在特征x出现的情况下标记y出现的概率。
- 1、感知机 2、k近邻法 3、决策树 4、logistic回归 5、最大熵模型 6、SVM 7、Boosting(AdaBoost) 8、条件随机场(Conditional random field,CRF) 9、 CNN
- 代码:pytorch自带Resnet,Vggnet,以及torchvision的dataset:Minist、CIFAR,都是应用在更深层的图像理解的任务上的backbone—并且都是利用已经训练过的prerain模型finetune
二、目标检测(定位+分类)
将定位任务是输出特定目标的boundingbox:如人脸检测、行人检测。是目标检测的一部分
目标检测任务:1定位+2类别+3置信度
传统方法是手工特征进行搜索
深度学习方法2种:1基于候选区域提取特征,再进行boundingBox回归;2 one stage 基于回归定位检测
2.1、 目标定位(object localization)
-
在图像分类的基础上,我们还想知道图像中的目标具体在图像的什么位置,通常是以包围盒的(bounding box)形式。基本思路 多任务学习,网络带有两个输出分支。一个分支用于做图像分类,即全连接+softmax判断目标类别,和单纯图像分类区别在于这里另外需要一个“背景”类。另一个分支用于判断目标位置,即完成回归任务输出四个数字标记包围盒位置(例如中心点横纵坐标和包围盒长宽),该分支输出结果只有在分类分支判断不为“背景”时才使用。
-
人体位姿定位/人脸定位 目标定位的思路也可以用于人体位姿定位或人脸定位。这两者都需要我们对一系列的人体关节或人脸关键点进行回归。
-
弱监督定位 由于目标定位是相对比较简单的任务,近期的研究热点是在只有标记信息的条件下进行目标定位。其基本思路是从卷积结果中找到一些较高响应的显著性区域,认为这个区域对应图像中的目标。
2.2、 目标检测
-
任务:识别全景图像目标位置Bounding Box、类别标签、置信度。通用的检测框架有faster rcnn可用于检测单一特定目标、多目标。根据任务的训练数据可以训练出各种检测模型:如人脸、行人、口罩
-
方法:
传统方法:
1区域选择(滑窗):滑窗遍历没有针对性(尺度、时间复杂度高、窗口冗余)
2特征提取(SIFT、HOG等)手工特征不稳定
3分类器(SVM、Adaboost等)+NMS和soft NMS高检索率下高精度
harrlike人脸特征+级联分类器, HOG行人特征+SVM分类器, DPM可变性部件模型 物体检测
深度学习方法:RCNN、yolo、ssd、fcn多特征融合
1 基于候选区域two stage 基于region proposal
RCNN,Fast-RCNN,Faster-RCNN(RPN候选区域网络)、R-FCN
候选区域(合并相似滑动窗):较少的窗,较高的recall(利用了图像中的纹理、边缘、颜色等)
(1) 使用Selective Search提取Proposes,然后利用CNN等识别技术进行分类。
(2) 使用识别库进行预训练,而后用检测库调优参数。
(3) 使用SVM代替了CNN网络中最后的Softmax,同时用CNN输出的4096维向量进行Bounding Box回归。
(4) 流程前两个步骤(候选区域提取+特征提取)与待检测类别无关,可以在不同类之间共用;同时检测多类时,需要倍增的只有后两步骤(判别+精修),都是简单的线性运算,速度很快
2 基于回归 one stage
You only look once(Yolo-v1-3)
Single Shot multiBox Detector(SSD)
FPN:重点,多重特征融合,将深层的特征图进行反卷积后再和浅层的特征融合
RetinaNet解读https://blog.csdn.net/JNingWei/article/details/80038594 -
数据集 Imagenet1000、PASCAL VOC20类 2007、MS COCO80类
PASCAL VOC 包含20个类别。通常是用VOC07和VOC12的trainval并集作为训练,用VOC07的测试集作为测试。
COCO比VOC更困难。COCO包含80k训练图像、40k验证图像、和20k没有公开标记的测试图像(test-dev),80个类别,平均每张图7.2个目标。通常是用80k训练和35k验证图像的并集作为训练,其余5k图像作为验证,20k测试图像用于线上测试。 -
应用:追踪、重识别
-
评价方法:mAP,一般设交并比IoU>0.5-0.7为检测到,调和平均数F1分数=2PR/R+P
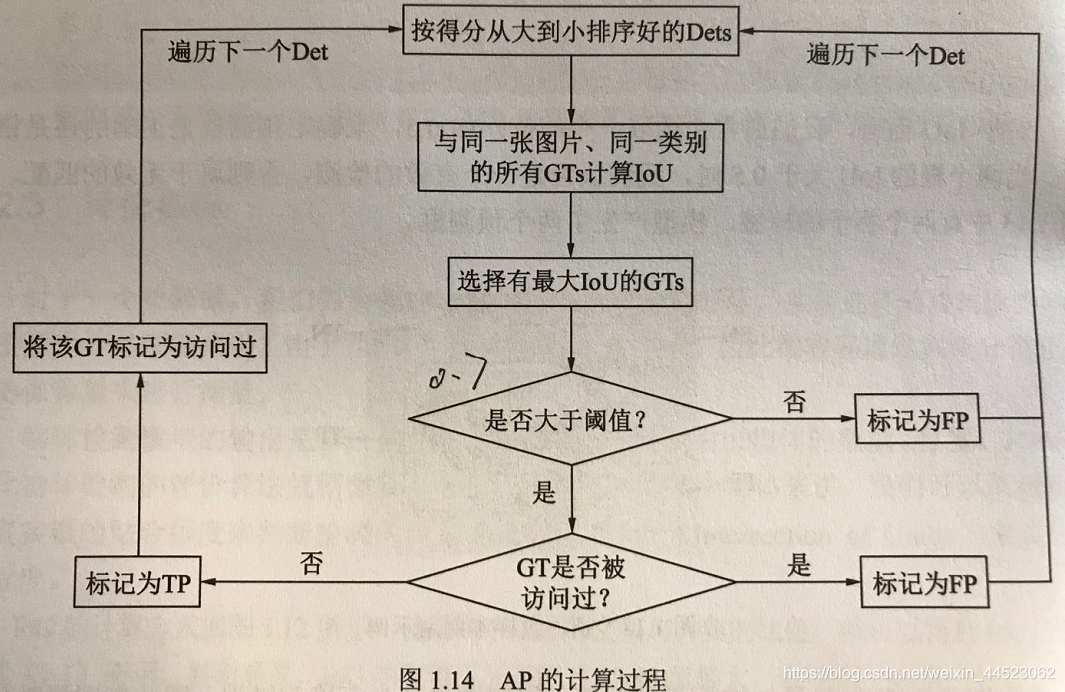
mAP (mean average precision) 目标检测中的常用评价指标,计算方法如下。当预测的包围盒和真实包围盒的交并比大于某一阈值(通常为0.5),则认为该预测正确。对每个类别,我们画出它的查准率-查全率(precision-recall)曲线,平均准确率是曲线下的面积,编程按检测到的目标数分别按阈值分割计算。之后再对所有类别的平均准确率求平均,即可得到mAP,其取值为[0, 100%]。
交并比(intersection over union, IoU) 算法预测的包围盒和真实包围盒交集的面积除以这两个包围盒并集的面积,取值为[0, 1]。交并比度量了算法预测的包围盒和真实包围盒的接近程度,交并比越大,两个包围盒的重叠程度越高。 -
难点或技巧
非最大抑制(non-max suppression, NMS) 目标检测可能会出现的一个问题是,模型会对同一目标做出多次预测,得到多个包围盒。NMS旨在保留最接近真实包围盒的那一个预测结果,而抑制其他的预测结果。NMS的做法是,首先,对每个类别,NMS先统计每个预测结果输出的属于该类别概率,并将预测结果按该概率由高至低排序。其次,NMS认为对应概率很小的预测结果并没有找到目标,所以将其抑制。然后,NMS在剩余的预测结果中,找到对应概率最大的预测结果,将其输出,并抑制和该包围盒有很大重叠(如IoU大于0.3)的其他包围盒。重复上一步,直到所有的预测结果均被处理。
在线困难样例挖掘(online hard example mining, OHEM) 目标检测的另一个问题是类别不平衡,图像中大部分的区域是不包含目标的,而只有小部分区域包含目标。此外,不同目标的检测难度也有很大差异,绝大部分的目标很容易被检测到,而有一小部分目标却十分困难。OHEM和Boosting的思路类似,其根据损失值将所有候选区域进行排序,并选择损失值最高的一部分候选区域进行优化,使网络更关注于图像中更困难的目标。此外,为了避免选到相互重叠很大的候选区域,OHEM对候选区域根据损失值进行NMS。
在对数空间回归 回归相比分类优化难度大了很多。\ell_2 损失对异常值比较敏感,由于有平方,异常值会有大的损失值,同时会有很大的梯度,使训练时很容易发生梯度爆炸。而 \ell_1 损失的梯度不连续。在对数空间中,由于数值的动态范围小了很多,回归训练起来也会容易很多。此外,也有人用平滑的 \ell_1 损失进行优化。预先将回归目标规范化也会有助于训练。
原文链接:https://blog.csdn.net/Fire_to_cheat_/article/details/88551011 -
代码:Yolo、fasterR-CNN在Imagenet或coco上run
三、目标分割(语义、实例)
- 任务:分割到像素级别,轮廓区域的mask。语义分割是类间区分,实例分割类内也要区分
语义分割,语义semantic:语义上理解每个像素的角色(比如,识别它是汽车、摩托车还是其他的类别)数据所对应的现实世界中的事物所代表的概念的含义,将具有同一概念意义的物体进行分割开
实例分割:基本思路 目标检测+语义分割。先用目标检测方法将图像中的不同实例框出,再用语义分割方法在不同包围盒内进行逐像素标记。
除了语义分割之外,实例分割将不同类型的实例进行分类,比如用 5 种不同颜色来标记 5 辆汽车。分类任务通常来说就是识别出包含单个对象的图像是什么,但在分割实例时,我们需要执行更复杂的任务。我们会看到多个重叠物体和不同背景的复杂景象,我们不仅需要将这些不同的对象进行分类,而且还要确定对象的边界、差异和彼此之间的关系! - 方法:
语义分割
FCN全卷积神经网络 U型网络
空洞卷积 ( Dilated Convolutions ),DeepLab 和 RefineNet,Cascades2015
实力分割:Mask R-CNN - 数据集:MSCOCO、VOC
PASCAL VOC 2012 1.5k训练图像,1.5k验证图像,20个类别(包含背景)。
COCO 有83k训练图像,41k验证图像,80k测试图像,80个类别 - 应用:医疗影像分割
- 评价方法: IoU,mAP
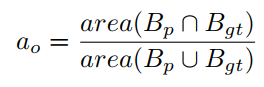
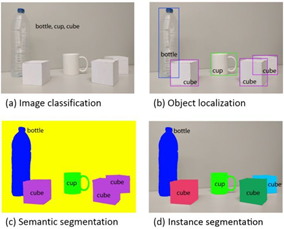
- 区别分类、定位、更一般的目标识别、语义分割、实例分割
这四个任务需要对图像的理解逐步深入。给定一张输入图像,图像分类任务旨在判断该图像所属类别。定位是在图像分类的基础上,进一步判断图像中的目标具体在图像的什么位置,通常是以包围盒的(bounding box)形式。在目标定位中,通常只有一个或固定数目的目标,而目标检测更一般化,其图像中出现的目标种类和数目都不定。语义分割是目标检测更进阶的任务,目标检测只需要框出每个目标的包围盒,语义分割需要进一步判断图像中哪些像素属于哪个目标。但是,语义分割不区分属于相同类别的不同实例。例如,当图像中有多只猫时,语义分割会将两只猫整体的所有像素预测为“猫”这个类别。与此不同的是,实例分割需要区分出哪些像素属于第一只猫、哪些像素属于第二只猫。此外,目标跟踪通常是用于视频数据,和目标检测有密切的联系,同时要利用帧之间的时序关系。
- 研究团队:foolwood同一人WangQiang
SiamMask https://zhuanlan.zhihu.com/p/58154634 - 代码:MaskRCNN
四、目标追踪(视频)
-
任务:基于全景MTSC,MTMC,多目标单摄像头 多目标多摄像头
STSC给定一张切好块的行人图像 (probe image), 从一段全景视频 (panorama track, 视野中只有一小部分是这个行人) 中找到 probe 所在的位置。这段全景视频是由单个摄像头拍摄的连续帧。 -
方法:生成算法 判别算法
生成算法使用生成模型来描述表观特征,并将重建误差最小化来搜索目标,如主成分分析算法( PCA );
判别算法用来区分物体和背景,其性能更稳健,并逐渐成为跟踪对象的主要手段(判别算法也称为 Tracking-by-Detection ,深度学习也属于这一范畴)
传统方法:
1生成式 光流法、meanshif 只关注目标,忽略背景
2相关滤波方法 CSK 有预测,提速
深度学习方法:
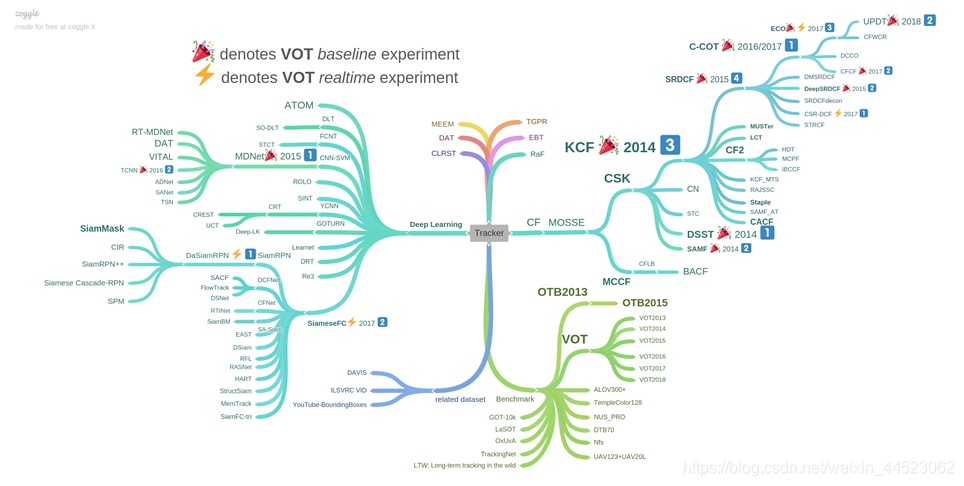
C-COT、ECO、MDnet、siamFC
深度网络模型:堆叠自动编码器( SAE )和卷积神经网络( CNN )。 -
数据集
OTB50、OTB100、VOT2016
cityflow 首个跨摄像头汽车跟踪数据集,或车辆REID
https://www.jiqizhixin.com/articles/2019-03-26-13 包括现有追踪算法分析 Deep SORT -
应用:智能监控、城市安防
综述https://www.cnblogs.com/liuyihai/p/8338369.html -
评价方式
实时性、准确性(需要补充,代码里vot比赛如何定义) -
研究团队:旷世王濛濛浙大
-
代码:
foolwood-Siammask作者,tracker的总结https://github.com/foolwood/benchmark_results
as
yolo v3+跟踪https://blog.csdn.net/weixin_42035807/article/details/89496378
KCF文章http://www.robots.ox.ac.uk/~joao/publications/henriques_tpami2015.pdf
KCFhttps://github.com/HenryZhangJianhe/KCF
-
代码:KCF(核化滤波),Correlation Filter
五、目标重识别(ReID:person、car)
- 任务:图像检索子任务,给定probe在gallery中搜索与之相同的跨摄像头的图像不是基于全景,数据集是已经检测好包含目标的图像
- 方法:
表征学习交叉熵分类、对比损失、属性损失
度量学习:三元组损失
局部对齐匹配:PCB
基于GAN生成 - 数据集
汽车:cityflow2019 ,北邮的 VeRi-776、北大的 VehicleID 北大的 PKU-VD
行人:Market1501、Duke - 应用
寻人、聚类 - 评价方法:mAP
解答目标重识别、目标追踪区别
https://www.zhihu.com/question/283460186/answer/869165399
解答行人追踪和重识别区别罗浩
https://www.zhihu.com/question/68584669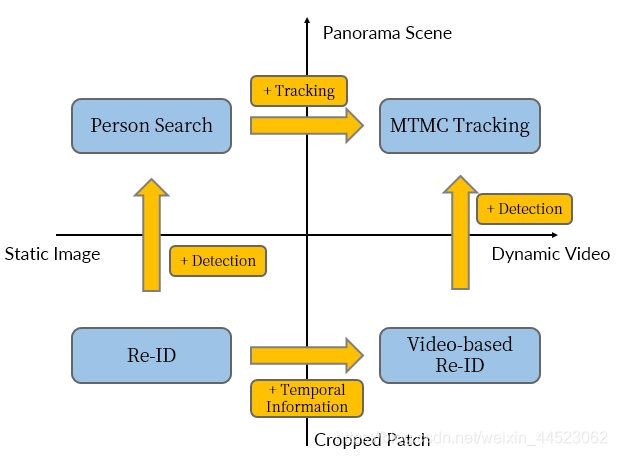
7、研究团队:罗浩、郑良
六、图像描述RNN+attention
-
任务:图像–>文字。训练带文字描述的图像,input Img–> output describe word
-
方法:编码解码,RNN中的LSTM,attention机制
-
数据集:
-
应用:盲人向导
-
评价方法:翻译文字的评价方法
-
难点
-
数据缺乏
七、图像生成:GAN
- 任务
- 方法
- 数据集
- 应用
- 评价标准
- 难点
八、finetune和迁移学习
九、Cross Domain adaptive
1、用于分割
2、用于重识别
3、用于跟踪
十、无监督学习问题
十一、常用数据集整理
常用数据集整理网址https://www.cnblogs.com/liuyihai/p/8338020.html
十二、几何属性的计算机视觉任务
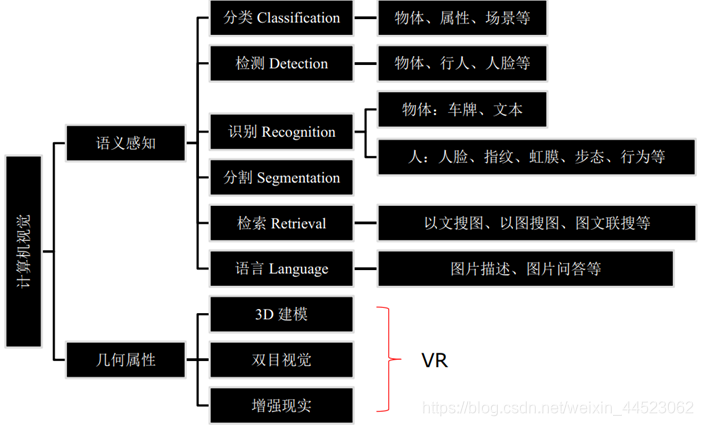
以上8项都是语义感知CV任务,基于几何属性任务分为3D建模、增强现实、双目视觉
十三、应用综合
- 人脸识别: Snapchat 和 Facebook 使用人脸检测算法来识别人脸。
- 图像检索:Google Images 使用基于内容的查询来搜索相关图片,算法分析查询图像中的内容并根据最佳匹配内容返回结果。
- 游戏和控制:使用立体视觉较为成功的游戏应用产品是:微软 Kinect。
- 监测:用于监测可疑行为的监视摄像头遍布于各大公共场所中。
- 生物识别技术:指纹、虹膜和人脸匹配仍然是生物识别领域的一些常用方法。
- 智能汽车:计算机视觉仍然是检测交通标志、灯光和其他视觉特征的主要信息来源。
- 云拿无感支付 零售http://www.yunatop.com/
十四、参考
详解计算机视觉五大技术:图像分类、对象检测、目标跟踪、语义分割和实例分割

