感谢刘老师
视频链接:https://www.bilibili.com/video/BV1Y7411d7Ys?p=4&spm_id_from=pageDriver&vd_source=2314316d319741d0a2bc13b4ca76fae6

找到使得cost最小的权重w
梯度下降算法
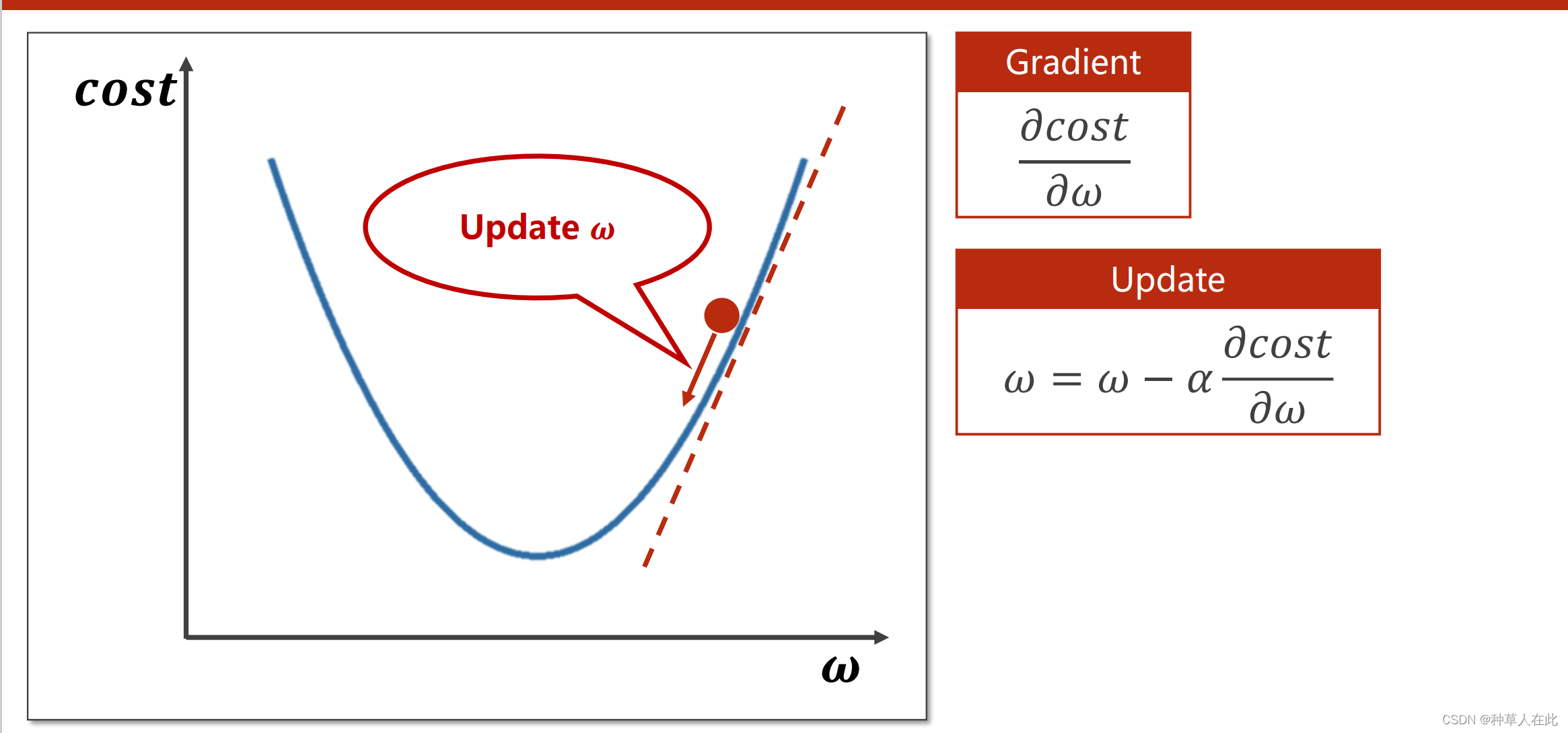
核心公式:权重w
α为学习率【一般不要太大,太大容易跑过】
下降方向是负梯度方向【梯度为正,x增大,函数值增大;梯度为负,x增大,函数值减小;要想下降,取梯度负方向。这块我也没搞清楚,如果梯度正,增大的方向为正方向,那么想要下降就是去负梯度方向;如果梯度负,正方向(负梯度?)为下降方向。是这样理解么?】
在DL中,目标函数没有很多局部最优点,存在鞍点【梯度为0(一维) or 0向量(多维) 】
DL中需解决最大的问题:鞍点问题【因为陷入鞍点后,就没法继续迭代了。因为梯度为0,前后w不变化】
损失函数的图像,会出现局部振荡大问题,一般绘图时,会用指数加权均值来平滑曲线。
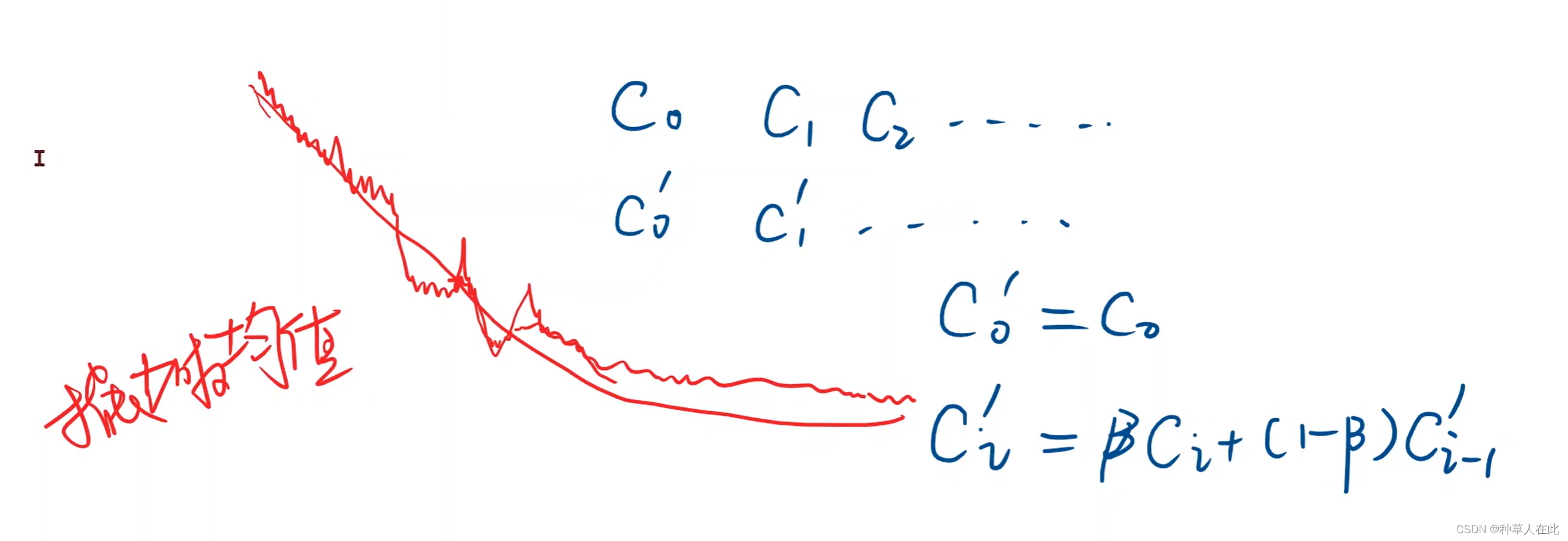
损失函数如果出现先下降后增大的情况,说明发散了,训练失败了。常见的问题是:学习率取大了。【DL实验需要多次尝试权重和参数】
import numpy as np
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0] # 准备训练集数据
y_data = [2.0, 4.0, 6.0]
_cost=[] # 记录cost变化,为画图
w = 1.0 # 初始权重的猜测
def forward(x): # 定义前馈计算,即predict_y如何计算
return x * w # 线性model
def cost(xs, ys): # 定义计算MSE
cost = 0
for x, y in zip(xs, ys):
y_pred = forward(x)
cost += (y_pred - y)**2
return cost / len(xs)
def gradient(xs, ys): # 定义计算梯度
grad = 0
for x, y in zip(xs, ys):
grad += 2 * x * (x * w - y)
return grad / len(xs)
print('Predict (before training)', 4, forward(4))
for epoch in range(100): # 训练过程
cost_val = cost(x_data, y_data) # 计算当前这一步损失值
_cost.append(cost_val) # 将每次迭代的cost值添加到列表,为作图
grad_val = gradient(x_data, y_data)# 求梯度
w -= 0.01 * grad_val # 0.01是学习率
print('Epoch:', epoch, 'w=', w, 'cost=', cost_val)
print('Predict (after training)', 4, forward(4))
#绘图
plt.plot(_cost,range(100))
plt.ylabel("Cost")
plt.xlabel('Epoch')
plt.show()
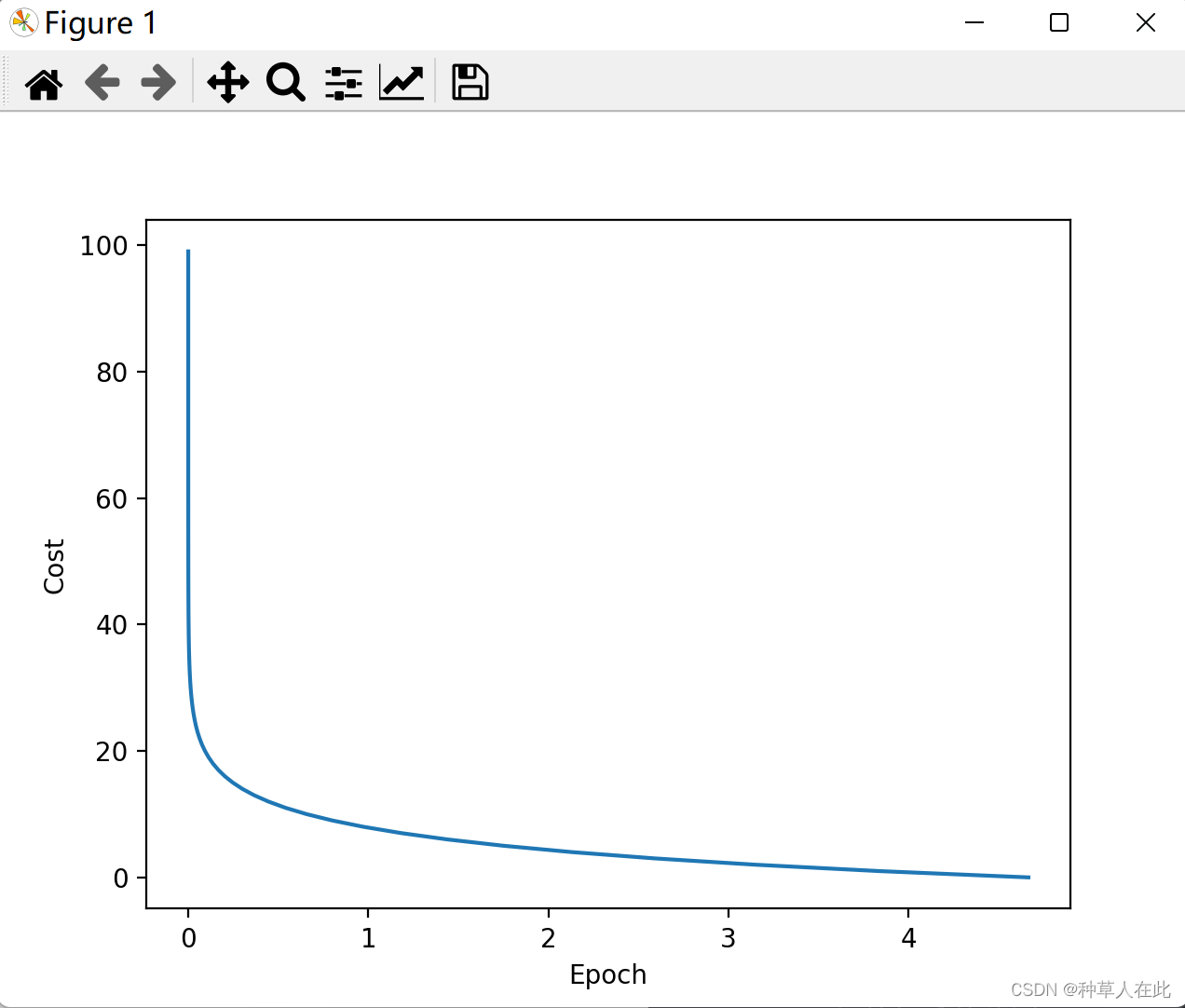
运行结果与老师ppt的不一样,【不知为何】但我试着修改学习率,如果改为0.1,很快收敛了。所以参数值需要多次尝试修改,进行实验。选择相对好的结果。
随机梯度下降
在实际中,梯度下降用的比较少,多用随机梯度下降

拿单个样本的损失函数对权重求导然后进行更新。
为什么用随机梯度下降?
因为带有鞍点的损失函数在DL中很常见,然而用梯度下降,损失函数会在鞍点停滞不前,只用一个样本即随机梯度下降就有可能让其从鞍点跨越到最优点。因为数据是有噪声的,一个样本的存在就引入了随机噪声,即使陷入鞍点,随机噪声可以把我们向前推动,引入随机性后,更新过程中就有可能跨越过鞍点。【这在DL中已被证明有效性】
x_data = [1.0, 2.0, 3.0] # 准备训练集数据
y_data = [2.0, 4.0, 6.0]
w = 1.0 # 初始权重的猜测
def forward(x): # 定义前馈计算,即predict_y如何计算
return x * w # 线性model
def loss (x, y): # 定义计算loss,不需要求和取平均,求一个样本即可
y_pred = forward(x)
return (y_pred - y)**2
def gradient(x, y): # 定义计算随机梯度
return 2 * x * (x * w - y) # 采用随机梯度下降
print('Predict (before training)', 4, forward(4))
for epoch in range(100): # 训练过程
for x, y in zip(x_data,y_data):
grad = gradient(x, y)
w = w -0.01 * grad
print("\tgrad: ", x, y, grad) # 这两步为了输出信息
l = loss(x,y)
print('Epoch:', epoch, 'w=', w, 'loss=', l)
print('Predict (after training)', 4, forward(4))
梯度下降和随机梯度下降的代码区别
(1)随机是把原来的cost(所有样本求和求平均)改成loss(单个样本求loss);
(2)梯度由原来的求和形式变成了单个样本的梯度;
(3)训练过程,之前是把整个样本产生的梯度求均值去更新权重,现在是对每一个样本,求梯度,进行更新。
在实际的DL中会出现
有很多数据样本,如果用梯度下降,对于每个样本用模型计算前后两个函数是没有相互依赖关系的,所以这些运算是可以并行计算的;但如果用随机梯度下降,在整个训练过程中两个样本梯度之间是不能并行的,是有依赖的。所以,利用并行计算优势,梯度下降算法效率高;利用随机梯度下降,性能好(找更优的点),但运算时间复杂度高。
综上,DL会用一种折中的方法——Batch(mini-Batch):批量的随机梯度下降。【将数据按若干个一组分,用一组样本求相应梯度,然后进行更新】