四、优化
4-1 Momentum
如果我们把梯度下降法当作小球从山坡到山谷的一个过程,那么在小球滚动时是带有一定的初速度,在下落过程,小球积累的动能越来越大,小球的速度也会越滚越大,更快的奔向谷底,受此启发就有了动量法 Momentum。
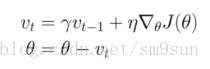
动量的引入是为了加速SGD的优化过程。分析上式就会明白动量的作用原理:利用惯性,即当前梯度与上次梯度进行加权,如果方向一致,则累加导致更新步长变大;如果方向不同,则相互抵消中和导致更新趋向平衡。动量 γ 常被设定为0.9或者一个相近的值。
4-2 Nesterov accelerated gradient
带动量的SGD可以加速超车,但是却不知道快到达终点时减速。NAG就是用来解决这个问题的。在动量法中,小球下滚过程如果遇到上坡则会减小速度,那么更好的做法应该是遇到上坡之前就减慢速度。这就是 NAG 的大致思想,相较于动量法,NAG在计算参数的梯度时,在损失函数中减去了动量项,这种方式相当于预估了下一次参数所在的位置。公式如下:
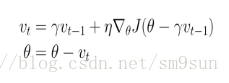
很明显,同带动量的SGD相比,梯度不是根据当前位置 θ 计算出来的,而是在移动之后的位置(θ−γνt−1)计算梯度。 (已经确定会移动 γνt−1,那不如之前去看移动后的梯度)。
4-3 Adagrad
能否根据参数的重要性自适应学习率呢?Adagrad 的提出思想是:在学习的过程中自动调整学习率。对于出现频率低的参数使用较大的学习率,出现频率高的参数使用较小的学习率。Adagrad为每一个参数 θi提供了一个与自身相关的学习率,公式如下:

其中 Gt为一个对角矩阵,其对角上的每一个元素 Gt,ii为 t时刻前所有施加到参数 θi 上的梯度的平方的和。 ϵ 用来防止除0操作。
简单分析上式,有三点结论:
(1) 经常出现(累积梯度大)的参数的学习率会被拉低,较少出现(累积梯度小)的参数的学习率会被拉高;
(2) 随着训练次数增加,累积梯度肯定会上升,导致分母变大,则学习率会自动下降。因此,Adagrad可以自动调节学习率,而我们只需给其一个初始学习率即可;
(3) 同样是随着训练参数增加,学习率会下降的很快,这可能导致后期学习率过低而学不到东西。
Adagrad 的在日常利用率较高,同时也存在着很多「坑」希望大家尽量避免。以 TensorFlow 为例,θ 是防被除零的项,但 TensorFlow 只提供了累积梯度平方和的初始值,并且默认为 0.1。如果我们设置的较小时,会导致初始学习率偏大。实际使用中,可以调整此参数可能有意外收获。
4-4 Adadelta
Adadelta 是 Adagrad 的一种改进算法,更新过程中参照了牛顿法(二阶优化方法),它利用 Hessian 矩阵的逆矩阵替代人工设置的学习率,在梯度下降的时候可以完美的找出下降方向,不会陷入局部最小值。

但是它的缺点十分明显,求逆矩阵的时间复杂度近似 O(n3),计算代价太高,不适合大数据。
Adagrad 随着时间增加导致学习率不断变小导致过早收敛,Adadelta 采用梯度平方的指数移动平均数来调节学习率的变化:
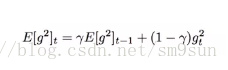
但论文中认为这个参数的更新没有遵循参数的单元假设,于是作者第二次尝试采用梯度平方的指数移动平均数来调整得到了:

Adagrad 最大的变化是没有学习率的设置,但是到训练后期进入局部最小值雷区之后就会反复在局部最小值附近抖动。
4-5 RMSprop
RMSprop 是 AdaDelta 的一个特例, 基本上等同于未做 单位统一 的Adadelta。它由 Geoff Hinton 在公开课中提出,采用梯度平方的指数移动平均数来调整,当参数更新较大时会对它进行「惩罚」,它的公式如下:
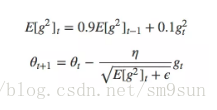
RMSprop 相对 Adagrad 梯度下降得较慢,被广泛应用在 CNN 领域。RMSprop 在 Inception v4 内取衰减因子γ 设置为0.9
4-6 Adam
Adaptive Moment Estimation (自适应矩估计Adam)是另外一种为每个参数提供自适应学习率的方法。可以看作是 RMSprop 和动量法的结合体。同RMSprop、Adadelta相比,Adam在对梯度平方(二阶矩)估计的基础上增加了对梯度(一阶矩)的估计,使得整个学习过程更加稳定。
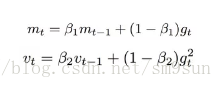
由于基于指数移动平均数的方式存在偏差,特别是在下降初期 m 和 v 被初始化为0并且接近 1 时。为此,引入偏差修正过程:
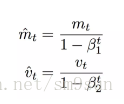
于是最终的更新公式为:
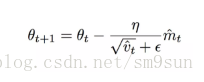
通常 β1,β2分别被设置为0.9和0.999
4-7 AdaMax
AdaMax是Adam的一种变种。主要是对原来的二阶矩估计扩展到无穷阶矩。(高阶矩往往不稳定,但无穷阶矩通常趋于稳定)
通过替换Adam中的分母项:
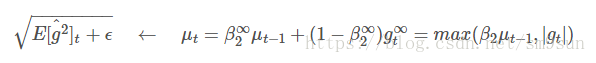
于是最终的更新公式为:
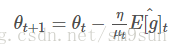
五、小结
Adam 即 Adaptive Moment Estimation(自适应矩估计),类比于动量法的过程也就是有偏一阶矩估计过程,RMSprop 则对应于有偏二阶矩估计。在日常使用中,往往采用默认学习率 0.001 就可以取得不错的结果。
Adam 计算效率高,适用于稀疏数据&大规模数据场景,更新的步长能够被限制在合理的范围内,并且参数的更新不受梯度的伸缩变换影响。但它可能导致不收敛,或者收敛局部最优点。
由于 Adam 可能导致不收敛,或者收敛局部最优点,因此谷歌在 ICLR 2018 提出了 AMSGrad,该论文中提到这样一个问题:
对于 SGD 和 AdaGrad 可以保证学习率总是衰减的, 而基于滑动平均的方法则未必。实际上,以 Adam 为代表的自适应算法存在两个主要问题:
1、可能不收敛
2、可能收敛于局部最优点
RMSprop 会对最近增加的值提出比较大的更新,随着步数梯的增加慢慢消散它的作用;Adagrad 以梯度的平方进行累积,所以说基于滑动平均的方法不一定能够保证走势衰减。AMSGrad 在二阶局部更新过程中通过取当前值与上一次的值的最大值用于计算∆x,确保学习率的衰减。

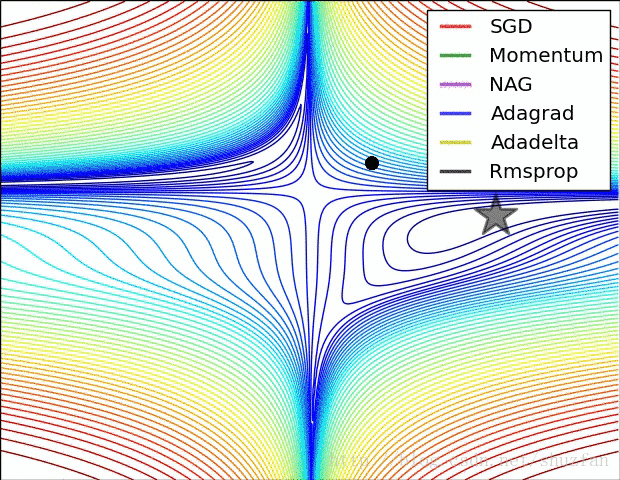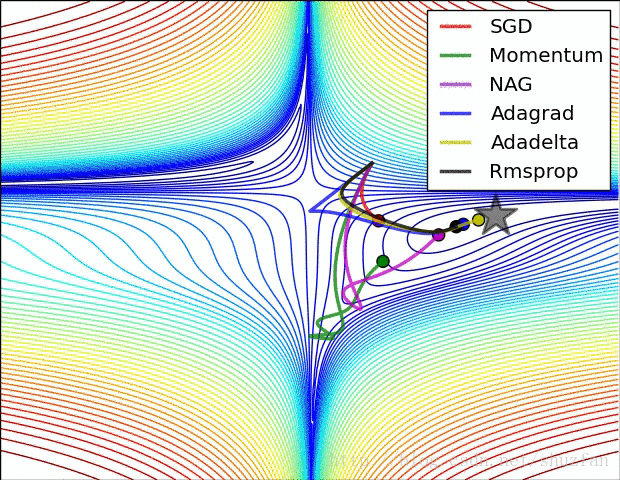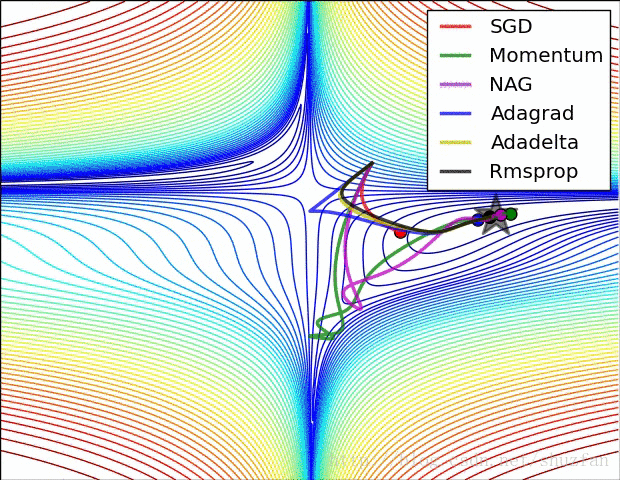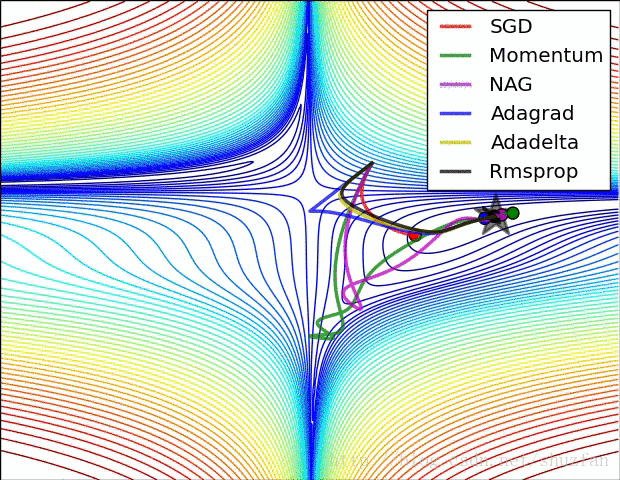
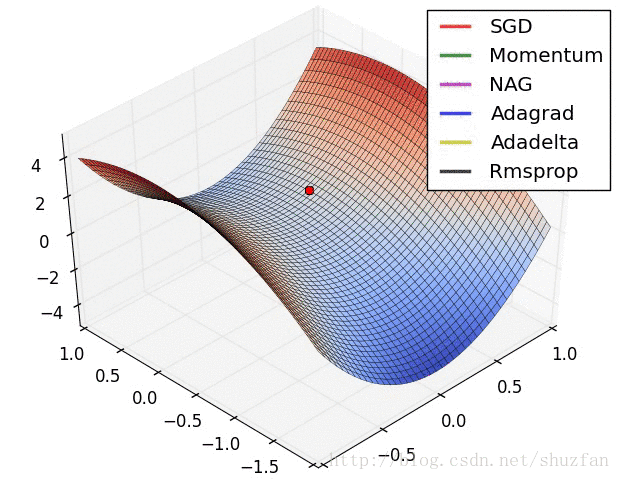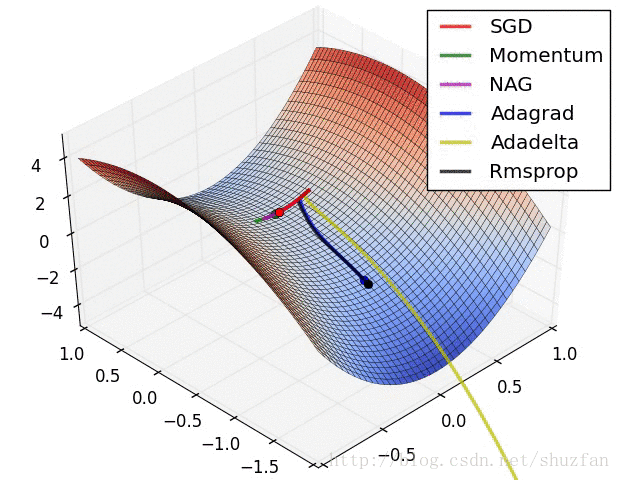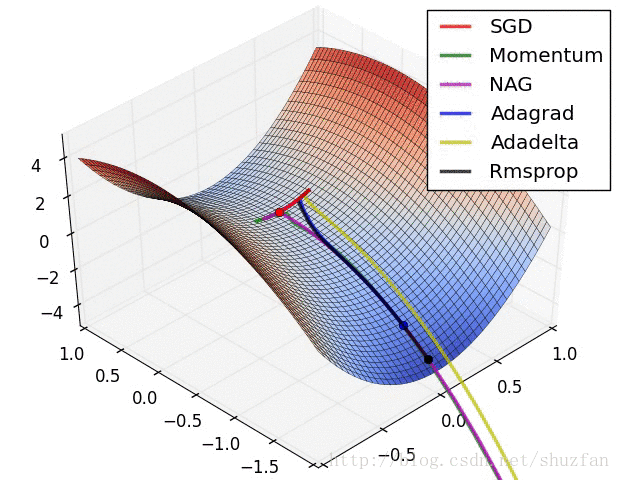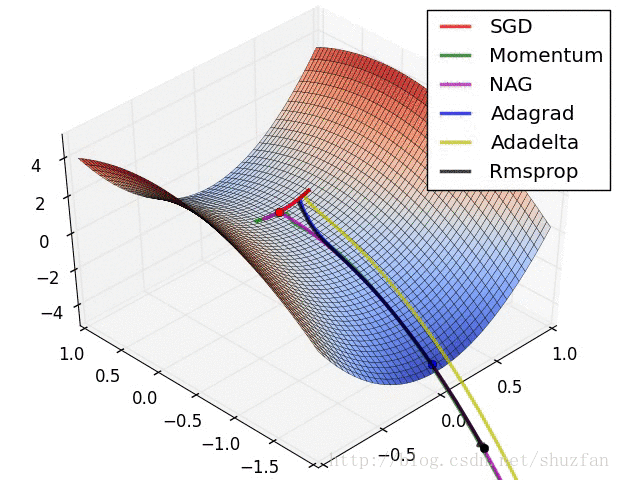
以上就是现有的主流梯度下降优化算法,总结一下以上方法,如上图所示,SDG 的值在鞍点中无法逃离;动量法会在梯度值为0时添加动能之后跳过该点;而 Adadelta 虽然没有学习率但在收敛过程非常快。