内容整理自《拿下offer 数据分析师求职面试指南》—徐粼著 第四章编程技能考查
其他内容:
【数据分析师求职面试指南】必备基础知识整理
【数据分析师求职面试指南】必备编程技能整理之Hive SQL必备用法
【数据分析师求职面试指南】实战技能部分
熟悉Python
懂R语言
掌握SQL
一篇Hive SQL 在互联网公司实习中使用Hive SQL的一些体会和注意点
大数据基础
Hive时Hadoop的一个数据仓库工具,将结构化的数据文件映射为一个数据库表,并提供类SQL查询功能:Hive SQL
Hadoop主要解决两大问题:大数据存储和大数据分析。解决分别依赖HDFS和Mapreduce。
HDFS:可扩展的、容错的、高性能的分布式文件系统,异步复制,一次写入、多次读取,主要负责存储。
MapReduce使分布式计算框架,包含Map映射和Reduce归约过程,负责在HDFS上进行计算。
Hadoop存储计算海量数据但是需要前端实时展示数据变化情况时,无法保证实时性。MySQL是将数据存储在本地服务器的关系数据库,可满足实时展示,但可能因计算量大使任务杀死。
目前通用方法在Hadoop中通过Hive SQL 对原始数据集进行处理,尽量在Hive中完成大数据量的计算,之后将处理好的数据通过出仓的方式导入MySQL。
下面是以Hive SQL为例:
数据库常用类型
不涉及子查询的单表查询SQL语句:select,from,where,group by,having,order by
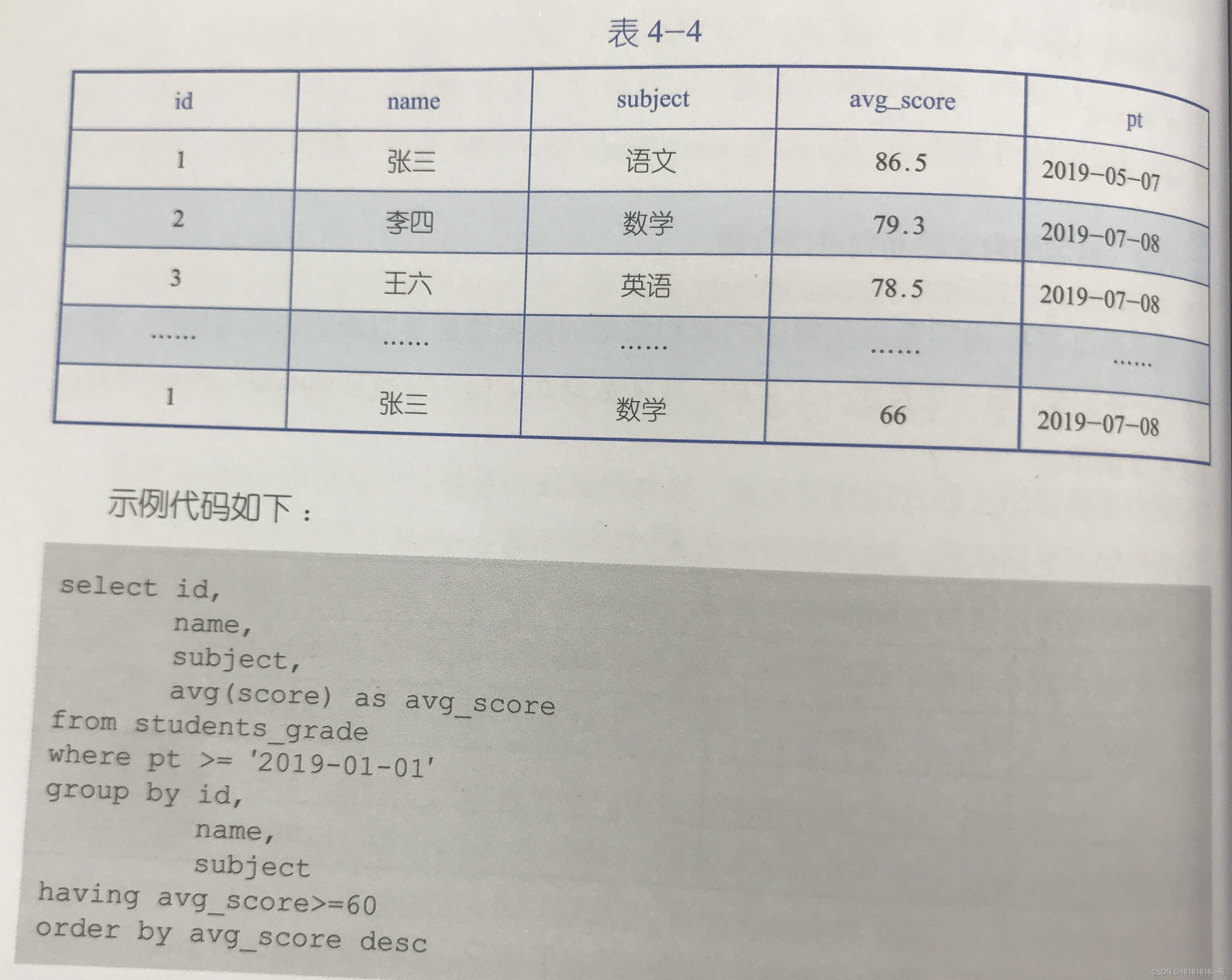
select执行顺序:from->where->group by ->select->having->order by
group by存在时,select后非聚合字段都会被视为分组字段,要保证一一对应!group by在sellect之前,所以不能直接使用别名。
只有存在group by才使用having,主要针对聚合后字段及逆行筛选,可以使用字段别名。
desc降序,asc升序
多表查询
join:以字段(列)为单位连接 【使用更广泛】。
1. inner join(内连接):只保留两个表同时存在的记录
2. left join(左连接):保留左表所有记录,无匹配用NULL
3. right join:保留右表所有记录
4. full join:左右表记录都保留
union:以记录(行)为单位连接,需要保证连接的两表字段数量相同,且按顺序一一对应。
mysql中有union.union all;Hive 只有union all(不去重)
Hive大多是分区表,加快查询速度,节省计算资源。没有索引,每次查询要全量扫描,增加分区可以减少每次扫描的数量。
分区表:增量表和全量表。
更多
聚合函数
出现select后,对记录按照分组字段进行汇总
| 聚合函数 | 含义 |
|---|---|
| sum(col) | 计算分组后组内所有记录的和 |
| avg(col) | …均值 |
| count(col) | 记录的数量 |
| stddev(col) | 标准差 |
| variance(col) | 方差 |
| max()min() | 最大最小值 |
| percentile(col,p) | p分位数,p:0~1 |
distinct
去重,两个场景:
一使select后使用,对整体记录去重(所有字段值相同)select distinct id,name... ;
二是聚合函数时,实现分组后去重,再进行聚合计算。count(distinct subject):统计参加过考试的学科数
case when
- 使用在分组语句和选择语句中,group by后(不可使用字段别名),提供新的分组字段。
select case when city in ('青岛','济南')then '山东'
else '其他'
end as province
count(1) as total
from table
where pt>='2019-01-01'
group by case when city in ('青岛','济南')then '山东'
else '其他'
end
- select后,基于现有字段生成新字段
- 聚合函数中:
count(distinct case when score>=60 then subject end)as total_suc_subject:统计考试通过的学科数
聚合函数+distinct+case when 基本完成SQL分组计算!
窗口函数
推荐阿里云文档
类似聚合函数也会对记录分组后进行聚合计算,但不会为每组只返回一个值,而是多个。准确说,为分组中每条记录都返回特定值。
只能出现select后,并且不会再使用group by
基本结构函数名() over (partition by col1,col2 order by col3 desc/asc,col4 asc/desc)
partition by表示对所有记录按照col1,col2分组,有相同的记录按照col3,col4降序或升序排列。
常用(一定要掌握,可以减少表与表的连接)的:

动态更新
用户留存率:n天前使用App的用户今天依然使用的占比。指标在原始数据产生n天后获得,需要对n天前分区数据进行更新,涉及动态分区概念。
Hive不支持insert、update、delete,无法直接修改记录,通过对分区全量更新实现数据修改。
首先建分区表 ;

一行变多行
group by 多行变一行
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vSF3Djdb-1678341151851)(images/Pasted%20image%2020230309133003.png)]](https://img-blog.csdnimg.cn/3ed8131e33a74e9b9f7a98c11a5b7797.png)
调优
比如当需要对大表小表进行join操作时,可以使用MAPJOIN将小表加载到内存中,通常小表大小营销与25MB。
若上述操作后,计算速度依旧不快,考虑数据倾斜问题。
执行Hive SQL语句过程中经历Map,Reduce两个步骤,

