文章目录
一、导读
继去年 LAION-400M 这个史上最大规模多模态图文数据集发布之后,今年又又又有 LAION-5B 这个超大规模图文数据集发布了。
其包含 58.5 亿个 CLIP 过滤的图像-文本对的数据集,比 LAION-400M 大 14 倍,是世界第一大规模、多模态的文本图像数据集,共 80T 数据,并提供了色情图片过滤、水印图片过滤、高分辨率图片、美学图片等子集和模型,供不同方向研究。
2022 年大火的 DALL·E 2 再次掀起了多模态图文匹配研究热潮。
在图文匹配领域,CLIP 模型使得在 ImageNet 上的 zero-shot 分类精度从 11.5% 提升到 76.2%,受此启发,ALIGN、BASIC 等大型图文多模态模型进一步改进,除了本身的模型优化之外,目前的进展其实都比较依赖底层的上亿图文对数据,但这些数据集及模型仅有少数公开,所以 LAION 提出了 LAION-5B 及在该数据集上训练的模型,并提供 web 界面提供预先计算的向量和搜索功能。
LAION-5B 通过 CommonCrawl 获取文本和图片,OpenAI 的 CLIP 计算后获取图像和文本的相似性,并删除相似度低于设定阈值的图文对(英文阈值 0.28,其余阈值 0.26),500 亿图片保留了不到 60 亿,最后形成 58.5 亿个图文对,包括 23.2 亿的英语,22.6 亿的 100+ 语言及 12.7 亿的未知语言。
官网:
https://laion.ai/blog/laion-5b/
数据集信息:
https://opendatalab.org.cn/LAION-5B
论文:
https://openreview.net/pdf?id=M3Y74vmsMcY
LAION-400M介绍:
https://mp.weixin.qq.com/s/vzyOF4esJCkBZDMiNScE5A
二、数据集背景信息
CLIP、DALLE这些模型证明了大规模多模态数据的重要性,即使不需要手动标注,也能超越很多优秀的有监督模型,经典如CLIP使用400M对网络图文对进行训练,不仅在ImageNet上zero-shot超越在ImageNet 1.2M有监督数据上训练的resnet50性能1.9%,并且能够识别普通视觉模型无法识别的素描图、油画图、艺术图等(图2)。
紧接着发布的ALIGN、GLIDE等证实了这一点,但是这些大型数据集都没有开源,因此这一领域的研究,只集中在少数几个机构中,2021年公布的LAION-400M是当时最大的公开图文数据集,本次发布的LAION-5B是LAION-400M的14倍,足够规模的公开数据使得该领域的研究更多元化,能够让更多的研究者参与到这一领域的研究中。

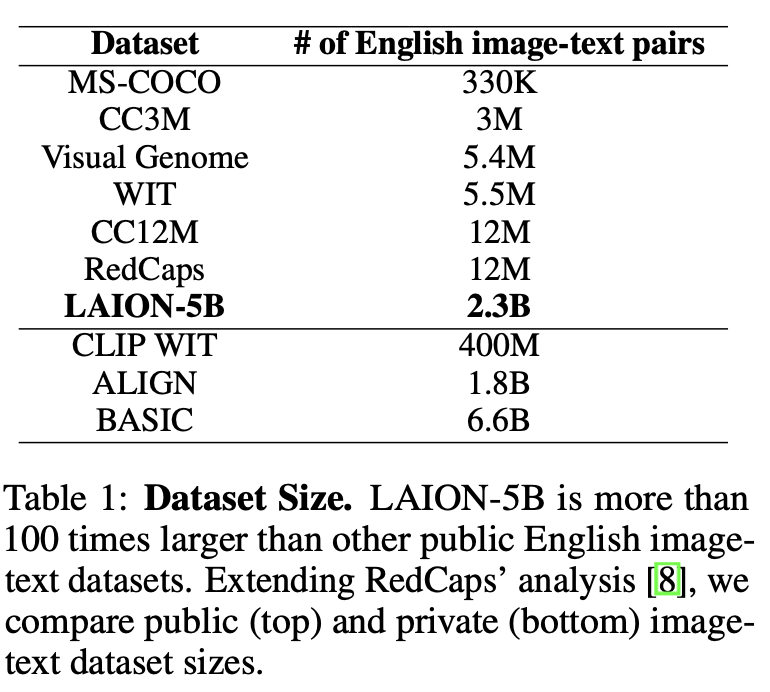
各个机构陆续发布过多模态数据集及图像数据集,但是由于数量不多或并未公开,并不能在多模态预训练模型上取得较好的效果,这里将LAION和以前的部分数据集进行了简单对比。
2.1 图文对数据集
最开始,数据集均通过人工注释生成,如COCO和Visual Genome,COCO Captions在COCO图片数据基础上,由人工标注图片描述得到。Visual Genome是李飞飞2016年发布的大规模图片语义理解数据集,含图像和问答数据,标注密集,语义多样。这两个数据集主要用于图像生成描述(Visual Genome也可以用于图像问答),然而由于图片数量较少,仅有330k和5M对,模型发展受到限制。
后来逐渐出现了非人工注释的多模态数据集,如Conceptual Captions 3M和Conceptual Captions 12M,对应描述从网站的alt-text属性过滤而来。随着CLIP模型的出现,大规模预训练模型逐渐成为多模态领域趋势,类似的还有ALT200M和ALIGN1.8B,数据集规模逐渐扩大到数十亿,虽然没有经过人工注释,但由于数据量大,在NLP、零样本视觉推理、多模态检索等多种下游任务中仍能取得良好甚至SOTA的效果。但可惜的是,CLIP所使用的4亿图文对以及ALIGN等数据集均没有公开。
去年公开的LAION-400M拥有4亿图文对,是当时最大的公开图文数据集,一经公开获取了很好的反响,也有多个模型基于该数据进行训练取得了较好效果,但相较官方CLIP仍有轻微差距,并且LAION-400M中含有大量令人不适的图片,对于模型,尤其是生成模型影响较大。比如stable diffusion模型,很多人会用来生成色情图片,产生了不好的影响,更大更干净的数据集成为需求。
这次公开的LAION-5B除了扩大规模之外,还提供了一些模型进行过滤,LAION训练了色情内容识别模型NSFW过滤绝大部分不适图片,水印检测模型可以过滤水印图片,由于部分隐私或不适内容若删除会影响研究丰富性,所以在总体数据内不会删除,会提供不同的子集用于不同用途。
2.2 图像数据集
大型如Instagram-1B、JFT300M、JFT3B均为私有数据集,暂未公开。
LAION-5B的数据规模目前最大,可以对许多未公开的多模态模型进行训练并获得较好效果,并公开了第一个开源的CLIP模型。并且数据多样,包含各种领域图片,对于后续研究提供了更多的方向,比如数据重叠、图片噪声、不适图片筛选、低资源语言、自然语言对于多模态的作用、模型偏差等等。
但如果将LAION-5B直接应用于工业,需要注意清洗图片,因为LAION-5B中含水印图片及不适图片,模型会因此产生偏差。
三、LAION-5B有什么
在LAION400M发布之后,在接连的研究中发现了未过滤引起的问题,受这些启发,除了50亿图文对之外,LAION还提供了多种子集。之前的研究中,为了限制生成模型不生成种族主义图片,尝试在训练集中删除了与暴力相关的物体、人和面部的图像,然而,这显然限制了模型的通用能力—比如人脸生成。因此,为了研究的多样性,在整体数据集中并没有删除此类内容,而是提供了多种子集。
除此之外,LAION还提供了复现的CLIP等模型,展示了基于LAION训练的模型拥有不输于原模型的能力。和KNN索引、Web界面方便检索合适的图片。
当然,为了大规模数据集方便下载,LAION也提供了img2dataset分布式下载,可以指定图像和文本大小,可以20个小时内单个节点下载1亿张图像(1Gbps速度,32G内存和16个内核的i7 CPU)
3.1 子集
LAION-5B中包括23.2亿的英语,22.6亿的100+语言及12.7亿的未知语言,我们将子集分别标记为:
- laion2B-en
- laion2B-multi
- laion1B-nolang
LAION训练了一个基于CLIP嵌入的色情内容识别模型NSFW,可以过滤3%的不适图片,NSFW准确率约96%,过滤后有子集:
- laion2B-en-safety
- laion2B-multi-safety
- laion1B-nolang-safety
LAION训练了一个水印识别模型,过滤后有子集:
- laion2B-en-watermark
- laion2B-multi-watermark
- laion1B-nolang-watermark
一个170M的超分辨率子集:
- laion-high-resolution
一个120M的美学图片子集,可以用来做图片生成:
- laion-aesthetic
3.2 开源模型
对现有未开源的多模态模型,LAION在子集上重新训练或微调,取得了较好的效果。
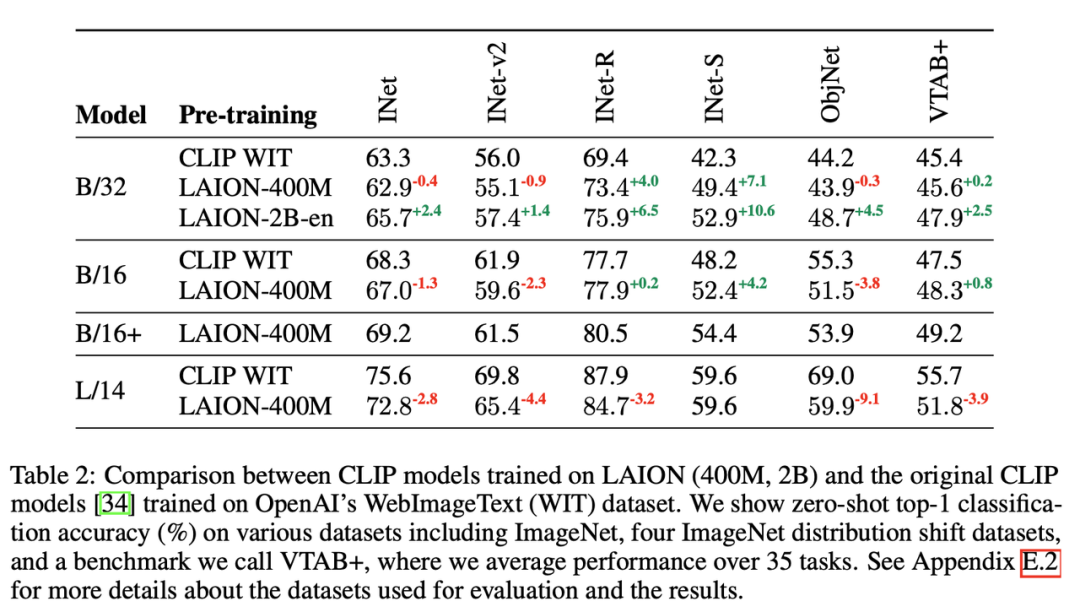
CLIP:通过openCLIP开源了CLIP模型,分别在LAION-400M和LAION-5B上训练,前者效果略低于OpenAI,后者zero-shot效果高于OpenAI。
BLIP:重新在LAION-400M中115M子集上训练,再使用CLIP对候选描述排序,评测后优于其他模型,用于描述生成和图文匹配。
Glide:在LAION-2B对Glide模型进行微调,获得了不错的效果。
除此之外,还提供了水印识别模型和色情内容识别模型NSFW。
3.3 KNN index/web界面
LAION使用autofaiss工具构建了KNN索引,共800GB。
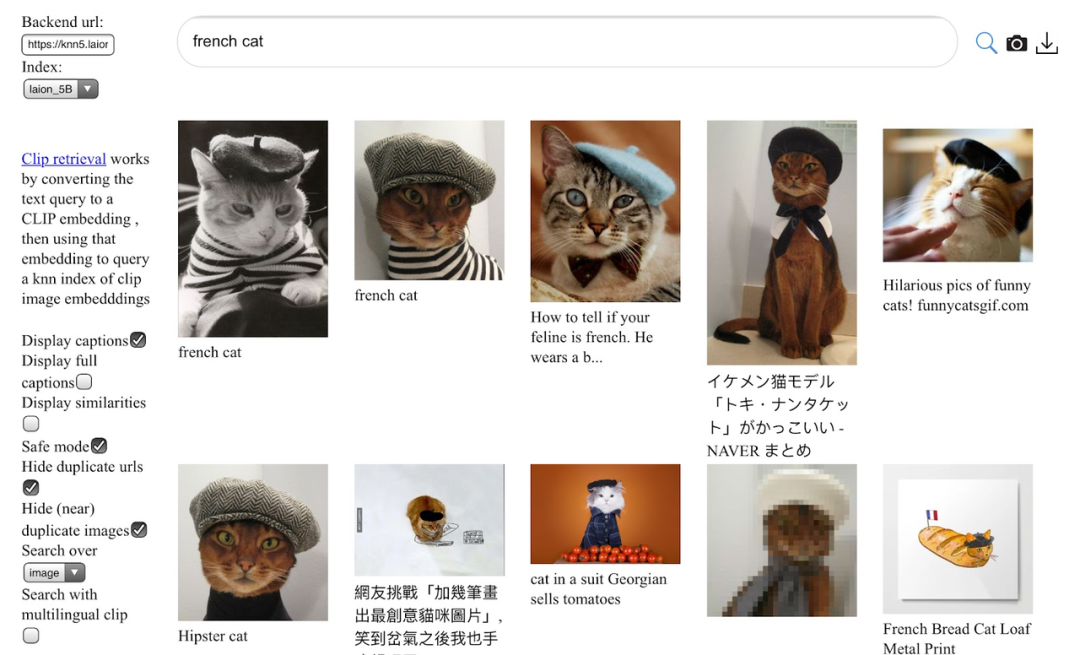
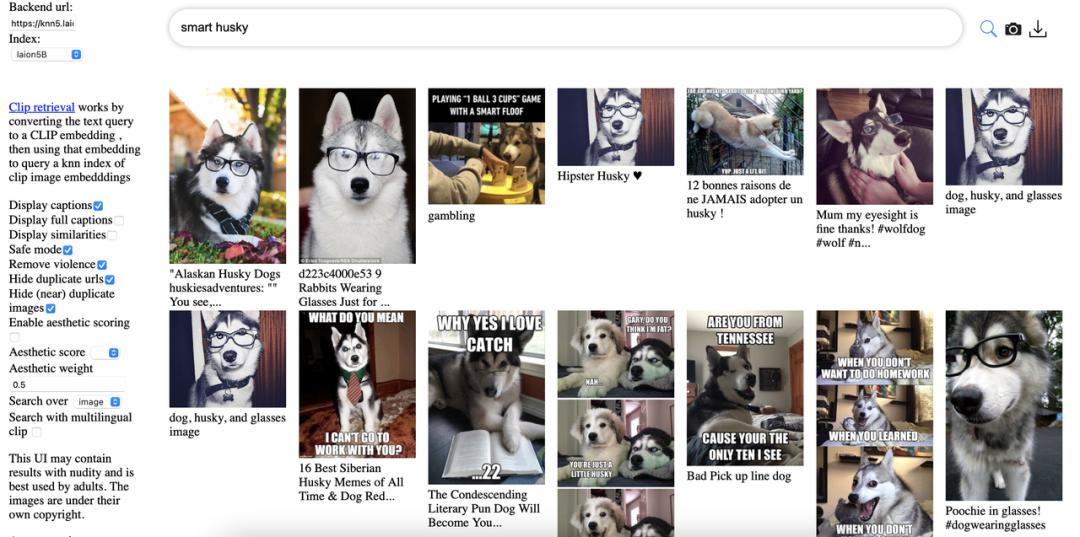
为了方便使用,将索引集成到网站中。web界面基于查询图像/文本来搜索图像/文本。通过CLIP的embedding来检索语义相似性较高的图像文本,鉴于高分辨率图片的丰富性,可以生成图像子集来训练自定义模型,也可以选择特定训练目的的图像分辨率。
检索网站左侧添加了safe mode,可以筛选不适图片。
检索网站:
https://rom1504.github.io/clip-retrieval/?back=https%3A%2F%2Fknn5.laion.ai&index=laion5B&useMclip=false
四、LAION可以做什么任务
LAION提供了大规模的图文数据,可以用来做大部分多模态及CV工作,多模态方面包括大规模预训练、图文匹配、图像生成(图像生成、图像修复/编辑等)和文本生成(图像生成文本、VQA等)等下游任务,CV方面包含分类等,LAION也提供了使用数据集训练的模型作为参考。
4.1 图文匹配及多模态预训练
包括但不限于任务:多模态预训练、图文匹配、图文检索。
CLIP模型使用对比学习将图像和文本嵌入到相同空间,标志着图像-文本的多模态的进展,用于图文匹配/检索、zero-shot分类等领域。但CLIP并未公开训练数据,因此LAION分别使用LAION-400M和LAION-2B重新训练了CLIP模型,准确率和OpenAI版本不相上下。
4.2 生成任务
- 图像生成
包括但不限于任务:高分辨率图像生成、图像修复/编辑、文本生成图片、条件图像生成。
LAION提供了子集来过滤不适图片和水印图片,为图像生成进一步提供了条件。目前有不少模型可以基于LAION子集来生成,DALLE这种自回归模型或者GLIDE这种扩散模型,以下给出几个例子:
-
Stable Diffusion使用LAION-5B的子集,在压缩的空间对图像进行重建,可生成百万像素的高分辨率图片,用于图像修复、图像生成等。
-
VQ-Diffusion模型使用矢量量化变异自动编码器,在LAION-400M训练文本生成图像的模型,获得更高的图像质量。
-
Imagen在LAION-400M的子集上训练,使用强大的语言模型抽取特征,并指导生成对应文本的高质量图像,击败DALLE-2实现SOTA。
-
也可以挑选其中领域图片进行生成,如人脸生成FARL。
文本生成:
包括但不限于任务:图像生成文本、VQA、Visual Entailment
-
BLIP重新在LAION-400M中115M子集上训练,再使用CLIP对候选描述排序,评测后优于其他模型,用于描述生成和图文匹配。
-
MAGMA在LAION子集上训练,基于适配器的微调来增强语言模型的生成,为视觉问题生成答案,仅使用simVLM的0.2%的数据量但生成了较好的结果。
4.3 分类任务
可以做zero-shot、finetune和训练。
通过web搜索子集或官方提供的子集,可以做构建分类识别,水印识别、色情内容识别、面部特征学习等等。也可以通过提供的大规模预训练模型,在下游任务做zero-shot和finetune。
4.4 其他任务
LAION数据丰富,可以筛选需要的数据做其他任务,比如可以在LAION-2B-multi中筛选指定语言数据做低资源语言任务,可以做数据重叠对模型的影响、模型偏见等等。
五、总结
LAION-5B,这个包含超过50亿图像文本对的数据集,进一步扩展了语言视觉模型的开放数据集规模,使得更多研究者能够参与到多模态领域中。并且为了推动研究,提供了多个子集用于训练各种规模的模型,也可以通过web界面检索构建子集训练。已有多个模型和论文证明了基于LAION子集训练的模型能够取得良好甚至SOTA的效果。