目录
1)dataframe类型数据和dataframe类型数据对齐(对齐NAME列);
数据对齐后的数据集(通过pandas.merge()函数对齐):
2)dataframe类型数据和geopandas类型数据对齐(对齐STATE_NAME字段);
数据对齐前的两组数据集(两个数据集都有很多行,这里只截取其中一部分):
0.环境
windows + jupyter notebook + python + pandas
1.适用场景
我是在做地理数据可视化的过程中遇到这个需求,我有一个dataframe类型的数据集(数据集A)和一个geopandas类型的数据集(数据集B),我需要用这两个数据绘制【分区统计图】,题目要求为“使用 PySal 数据,创建美国的分区统计路径,该路径描述了 2009 年美国每个州的人均收入。”但是我在直接使用数据的过程中,发现两个数据集的数据无法对齐(数据对齐概念在下一段详述),数据不对齐,就会导致可视化的结果是错误的,比如两个数据集中都有名为NAME的列,但是两个数据集中对于NAME列的顺序是不同的,数据集A中的NAME列顺序可能为:[name1,name3,name2] ,数据集B中NAME列的顺序可能为:[name3,name1,name2],其他对应行的数据肯定也随之不同,这个时候我就不能直接利用两个数据集来做数据可视化,这样可能会将原本不属于name1的数据,安插到name1上,从而导致最终可视化结果出错。为了解决这个问题,我采用数据对齐的方式(使用merge()方法),将两个数据集对齐为一个数据集(geopandas类型)
2.pandas.merge()函数详细介绍
merge(left, right, how=‘inner’, on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=(’_x’, ‘_y’), copy=True, indicator=False, validate=None)
官方文档介绍merge()的作用:用数据库样式的连接合并DataFrame或者已命名的Series

3.名词解释“数据对齐”(来自chatGPT3.5)
数据对齐是一种重要的数据处理技术,它可以确保数据在相同的索引或列名上对应匹配,从而简化数据处理操作,并提高数据分析的准确性和可靠性。
数据对齐是指在数据处理过程中,将不同数据集或不同索引的数据按照相同的索引进行匹配和对齐的操作。这样做的目的是为了方便数据的比较、合并、计算等操作。
当我们有多个数据集或多个DataFrame对象时,它们可能具有不同的索引或列名。数据对齐的过程可以通过对齐索引或列名来确保数据在相同的位置上对应匹配。这样做有助于消除数据之间的不匹配和缺失值,使得数据处理更加方便和准确。
在数据对齐的过程中,如果两个数据集的索引或列名不完全匹配,那么会自动进行对齐,缺失的值将被填充为缺失值(例如NaN或None)。这样,我们可以确保在进行数据操作时,每个数据点都有相应的值,避免了数据不一致导致的错误或结果偏差。
4.本文将给出两种数据对齐的例子
1)dataframe类型数据和dataframe类型数据对齐(对齐NAME列);
-
数据对齐前的两组数据集:
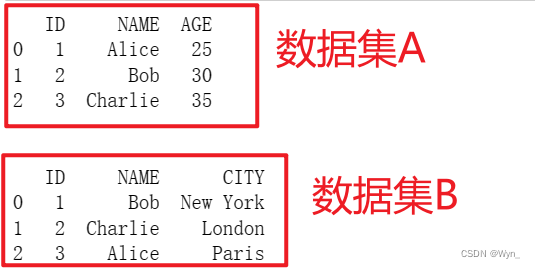
-
数据对齐后的数据集(通过pandas.merge()函数对齐):

可以看到两个数据集A和B通过NAME字段进行了对齐
-
代码
import pandas as pd
# 创建第一个DataFrame
data1 = {'ID': [1, 2, 3],
'NAME': ['Alice', 'Bob', 'Charlie'],
'AGE': [25, 30, 35]}
df1 = pd.DataFrame(data1)
print(df1)
print("\n")
# 创建第二个DataFrame
data2 = {'ID': [1, 2, 3],
'NAME': ['Bob', 'Charlie', 'Alice'],
'CITY': ['New York', 'London', 'Paris']}
df2 = pd.DataFrame(data2)
print(df2)
print("\n")
# 使用merge方法对齐两个DataFrame的'NAME'列
merged_df = pd.merge(df1, df2, on='NAME')
# 打印对齐后的DataFrame
print(merged_df)2)dataframe类型数据和geopandas类型数据对齐(对齐STATE_NAME字段);
-
数据对齐前的两组数据集(两个数据集都有很多行,这里只截取其中一部分):
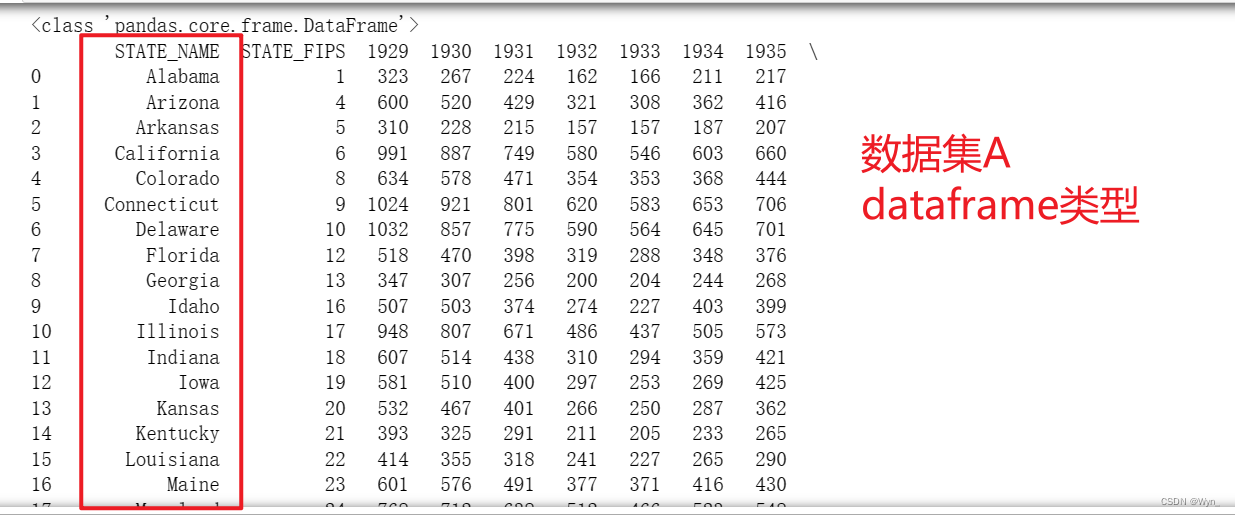
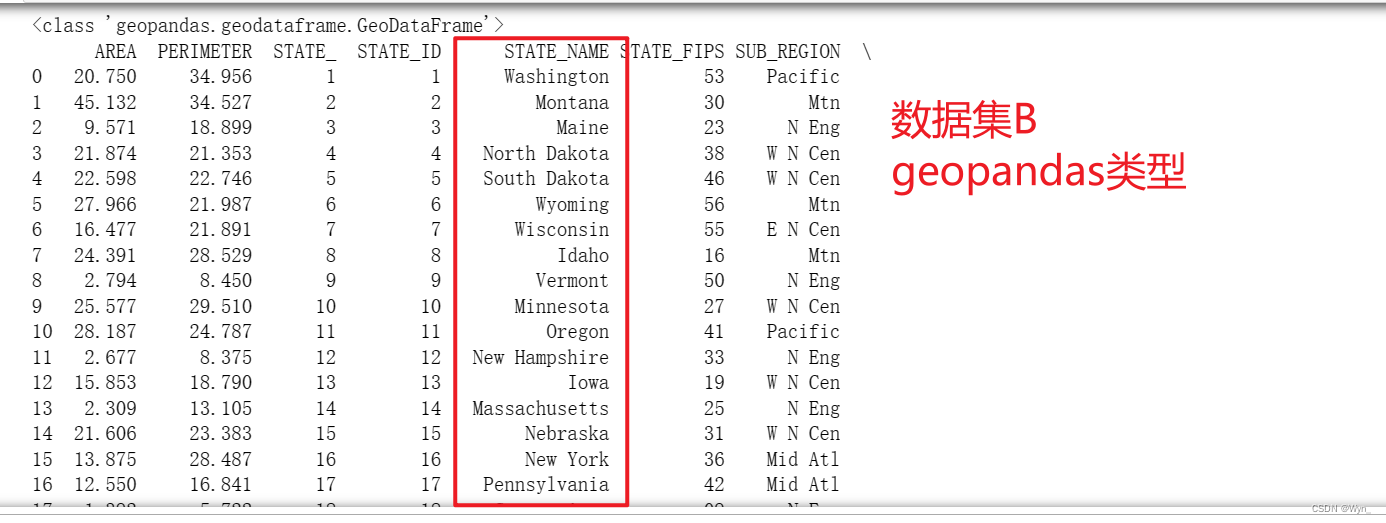
-
数据对齐后得到一组geopandas类型数据:
可以看到通过STATE_NAME字段,将两个数据集合成了一个geopandas类型的数据集,具体是将两个数据集的所有列根据STATE_NAME字段排序并整合进一个数据集内,还有很多行和列,无法在一个界面显示,这里只截取一部分
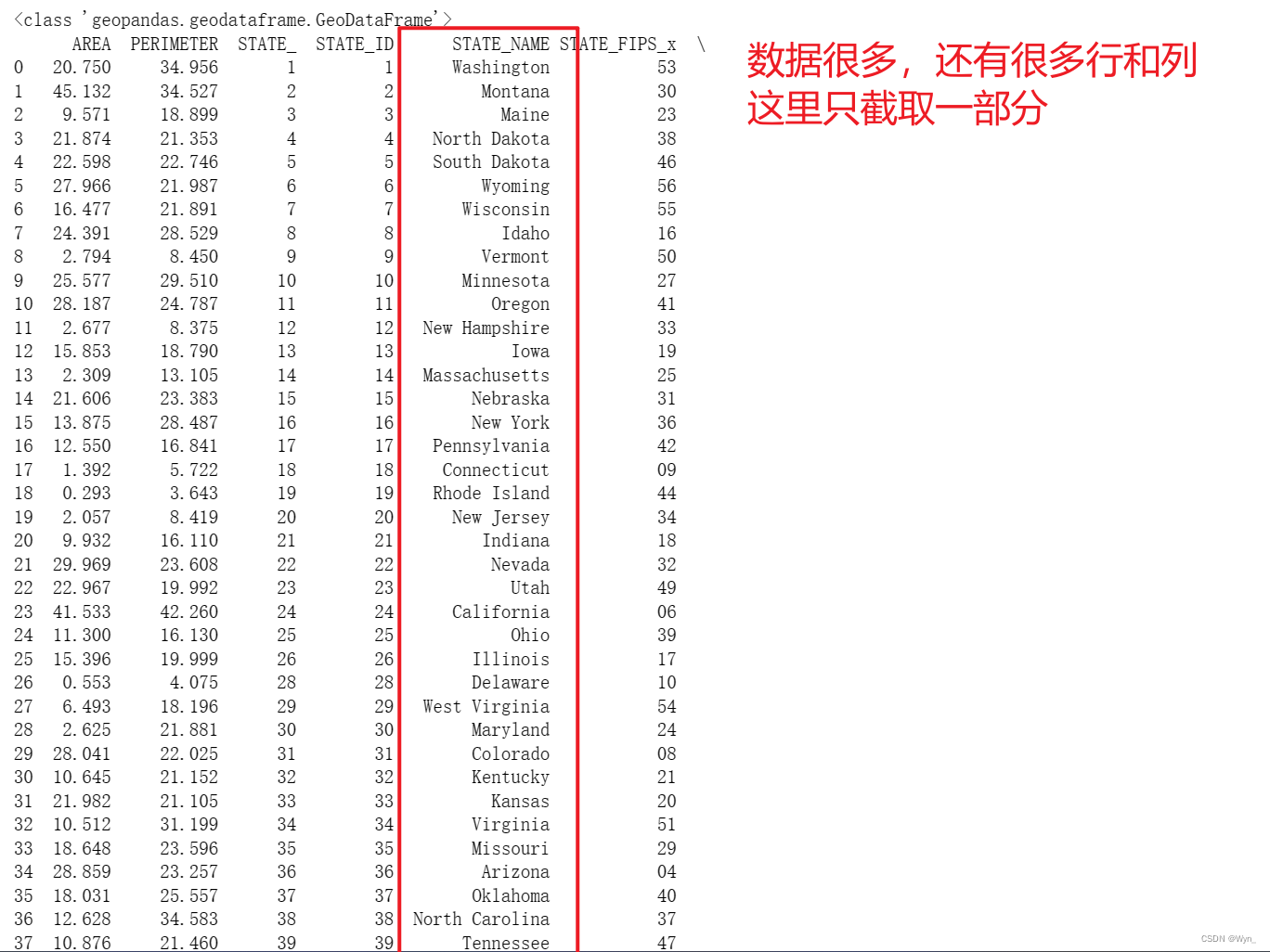
-
代码
注意:代码运行前需要安装对于的模块,如pysal 、geopandas、libpysal等,可以在【Anaconda prompt中用pip install XXX命令下载】
具体下载过程可以参考博客:
import pysal as ps
import geopandas as gpd
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# your code here
from libpysal import examples
#2009年的人均收入数据
income_data = examples.get_path('usjoin.csv')
#用pandas读数据
usincome = pd.read_csv(income_data)
#重命名dataframe数据(usincome)的Name列
usincome.rename(columns={'Name':'STATE_NAME'}, inplace=True)
# print(type(usincome))
print("对齐前dataframe类型数据:\n")
print(usincome)
#48个州的形状
us_states = examples.get_path('us48.shp')
us48 = gpd.read_file(us_states )
# print(type(us48))
print("\n对齐前geopandas类型数据:\n")
print(us48)
#数据对齐 STATE_NAME
merged_gdf = us48.merge(usincome, on='STATE_NAME')
# print(type(merged_gdf))
print("\n对齐后geopandas类型数据:\n")
print(merged_gdf)参考:
(35条消息) python pandas.merge()函数 详解_python中merge函数用法_Late whale的博客-CSDN博客pandas数据合并之一文弄懂pd.merge() - 知乎 (zhihu.com)(35条消息) python pandas.merge()函数 详解_python中merge函数用法_Late whale的博客-CSDN博客
--END--