Yolo目标检测
一、 YoloV1
YOLOv1采用的是“分而治之”的策略,将一张图像平均分成7×7个网格, 每个网格分别负责预测中心点落在该网格内的目标。通过划分得到了7×7个网格,这49个网格就相当于是目标的感兴趣区域。

对于每一个网格(grid),都会预测出B个边界框,每个边界框有5个量,分别是物体的中心位置(x,y)和它的高(h)和宽(w),以及这个边界框包含目标的概率。还要预测该边界框的目标属于那个类别
如下图,假设对每个网格都预测2个边界框
我们对红色的网格进行预测

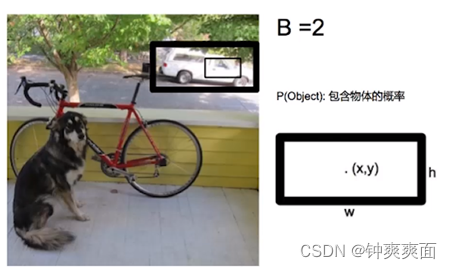
通过这两个边界框预测出物体的概率,用边界框线的粗细来代表,得出 粗的边界框内包含物体的概率比较高
为每一个网格进行边界框预测,最终我们得到图像如下

为每一个网格预测类别概率,预测每一个网格属于类别的概率:
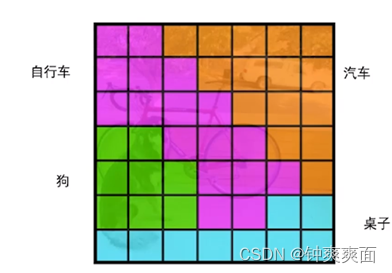
将边界框和类别预测结合起来

设置一个阈值(筛选目标概率低的边界框),通过NonMaxSuppression进行筛选,清理掉不好的边框。

NonMaxSuppression:
非极大值抑制。
当同一个类别中有很多边界框,且边界框之间重叠的区域很大,那就会认为在检测同一个物体。这时候就会选择包含目标概率最高的边界框,其余的边界框就会进行清理。
二、 YoloV1网络结构
YOLOv1的网路结构非常明晰,是一种传统的one-stage的卷积神经网络
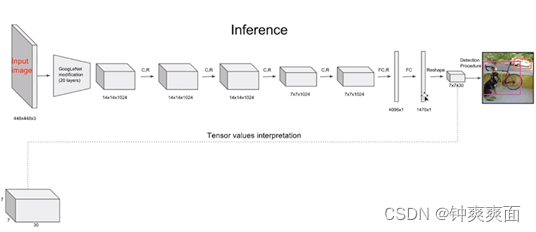
网络输入:448×448×3的彩色图片。
中间层:由若干卷积层和最大池化层组成,用于提取图片的抽象特征。
全连接层:由两个全连接层组成,用来预测目标的位置和类别概率值。
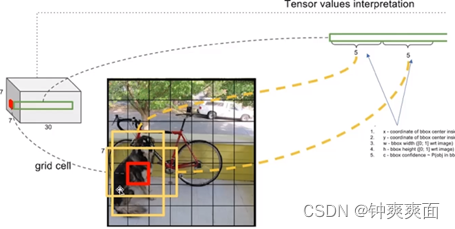
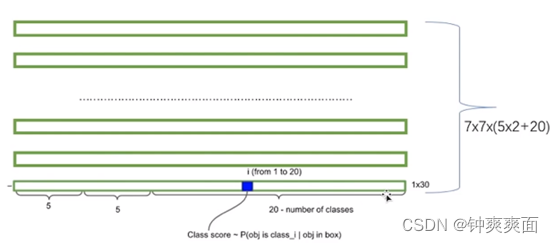
网络输出:因为我们对每个网格都预测2个边界框,所以有7×7×30的预测结果。刚好对应我们之前7x7的网格,相当于对我们的每个网格进行预测。
YoLo预测层:

每个网格预测2个边界框,每个边界框会预测输出5个值,分别是包含目标的概率,物体的中心坐标X,Y,物体的高度和宽度。在对每个网格进行类别预测,这里我们有20个类别,所以每个网格会进行类别预测20次。所以维度是(5*2)(2个边界框输出的值)+20(类别预测)

预测类别:
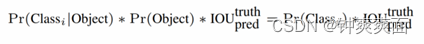
表达式含义:等式左边第一项就是每个网格预测的类别信息,第二三项就是每个边界框的包含物体的概率。取出每个网格对应的边界框含物体的概率,与预测的类型进行乘积,这样既预测了边框属于那个一个类别,也计算了边框的物体概率。
虽然每个格子可以预测B个bounding box,但是最终只选择IOU最高的bounding box作为物体检测输出,即每个格子最多只预测出一个物体。当物体占画面比例较小,如图像中包含畜群或鸟群时,每个格子包含多个物体,但却只能检测出其中一个。
三、 YoloV1的损失函数

四、 Yolo的缺点

五、 YoloV2
YoloV2与Yolo的区别:


改进如下:
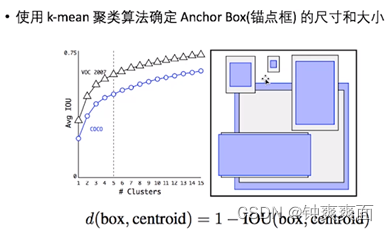
(1) Dimension Clusters:
之前Anchor Box的尺寸是手动选择的,所以尺寸还有优化的余地。YOLOv2尝试统计出更符合样本中对象尺寸的先验框,这样就可以减少网络微调先验框到实际位置的难度。YOLOv2的做法是对训练集中标注的边框进行K-means聚类分析,以寻找尽可能匹配样本的边框尺寸
(2) Fine-Grained Features:

提高预测精度。
让图像上较大的尺寸的特征图与最终的输出进行融合,保留特征图更细节的信息,这样能预测检测出一些比较小的对象。
(3) Multi-Scale Training

(4) Batch Normalization

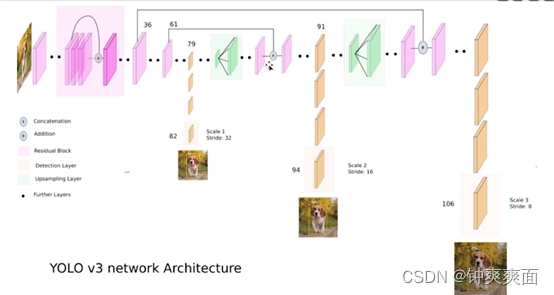
六、 Yolo3
Yolo3对于Yolo2的改进
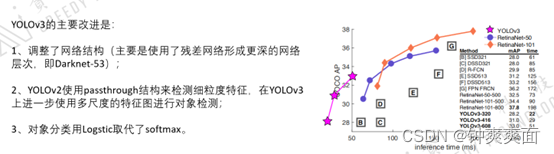
加入了ResNet(残差层),使得网络能更深,能预测更小的物体


网络结构如下: