前言
上一篇博文讲的Fast R-CNN、Faster R-CNN等都是基于旧形态CNN的结构(VGG、AlexNet)为基础,网络中存在全连接层。随着CNN全卷积化的趋势(ResNet、GoogleNet,只剩下一个全连接层 2048 -> 1000),那么能简单的应用ResNet、GoogleNet作为基础网络吗?事实证明,如果简单的丢弃全连接层,检测的效果反而会变差。
这主要是来源于下面的一对矛盾:
(1)图像分类:要求图像具有平移不变性
(2)目标检测:要求图像具有位置敏感性(平移变换性)。
首先先理解什么是平移不变性和位置敏感性。
平移不变性: 比如在用基础网络(ResNet、GoogleNet)在给一只狗做分类时,无论狗怎么扭曲、旋转灯,最终识别出来的都是狗,这就是平移不变性。网络越深(Resnet、Google net 网络很深)、特征越明显,识别越准确。识别结果不会因输入的位置、形状发生变换而改变。
平移变换性: 针对目标位置检测,假如输入狗的坐标发生了变化,检测出狗的坐标也发生了变化,这就是平移变换性。但是当网络加深(Resnet、Google Net 网络很深)时,最后一层卷积层输出的feature map变得很小,当输入发生位置改变时,经过N多层pooling后会感知不到物体输入的位置改变。网络越深,平移变换性越差。
由上述可知,要使目标检测好(分类 + 定位),就要保证平移不变性和平移变换性好,但是平移不变性和平移变换性是矛盾的,如果要应用Resnet、Google Net 这种深层次的网络那该怎么解决呢?
R-FCN即是为解决上述两个矛盾而来。
R-FCN
- 引入变换敏感性
1、位置敏感分值图(Position-sensitive score maps)
特殊设计的卷积层
Grid位置信息 + 类别分值
2、位置敏感池化(Position-sensitive RoI pooling)
无训练参数
无全连接网络的类别推断
position-sensitive score map
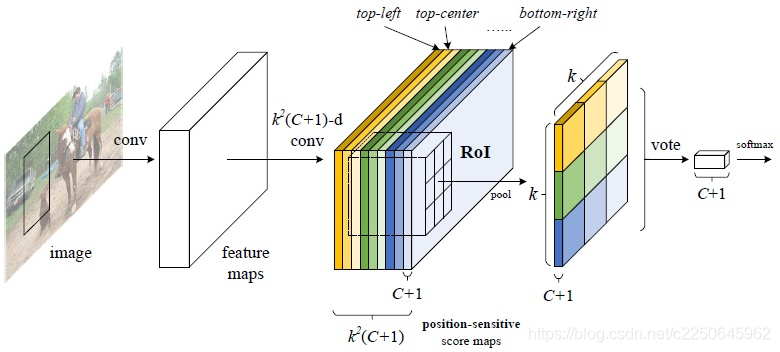
使用k * k(C+1)个通道对位置、类别组合进行编码,其中
- 类别:C个物体类和+1个背景类
- 相对位置:k * k个Grid(k = 3)
- 位置敏感分值图(Position-sensitive score maps)
1、每个分类k * k个score map
2、score map尺寸 = 图片尺寸
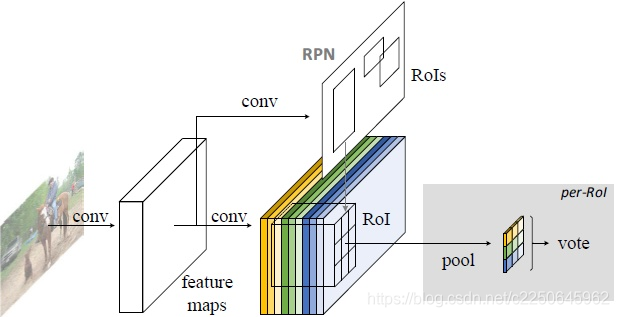
解释: R-FCN会在共享卷积层的最后加上一层卷积层,该层的height和width与共享卷积层是一样,所不同的是该层通道数是k * k(C+1)个。每个类别都有k * k个score map。
我们对某一类别进行讨论,score map都是只属于“一个类别的一个部位”的(共有k * k个部位,可以理解为每个score map关注的是某类别的不同部位信息),所以RoI的第 i 个子区域一定要到第 i 张score map上去找对应区域的响应值,因为RoI的第 i 的子区域需要的部位和第 i 张score map关注的部位是一样的,将左右的score map分别对应计算组合,就得到了一个类别完整的分值图(C+1个分值)。
如上图,第一张score map关注的是top-left的区域,那么top-left区域的分值就要从该张图上去计算求池化,k * k个区域刚好对应了k * k张score map图。
那是怎么做到不同score map的映射呢?即怎么根据score map计算得到后面对应的RoI区域的分值??这里就需要引入位置敏感池化
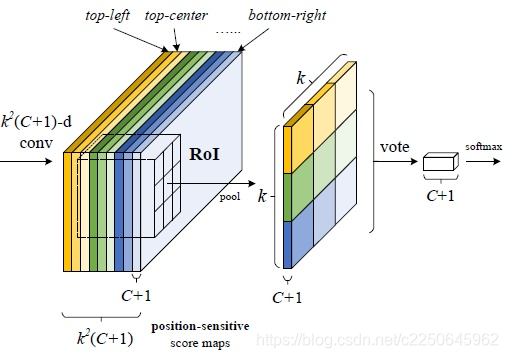
Position-sensitive RoI pooling
位置敏感池化,顾名思义就是根据位置的不同做池化,这样才能达到所谓的‘位置敏感’。
- 将w * h尺寸的RoI拆分成k * k个bin,其中bin大小是w/k * h/k。
- 不同颜色bin对应的是不同颜色的通道层,也可以理解为类别的不同区域,因为不同颜色的通道层关注的是类别的不同区域,共有k * k个区域
- bin内做均值池化
- 输出尺寸是k * k * (C+1)
解释: 由图看到,经过RPN网络提取得到的RoI区域,其实是包含了位置信息的,可以对应到score map的对应位置。一个RoI会分成 k * k 个bins(也就是子区域。每个子区域bin的长宽分别是 w/k 和 h/k),每个bin都对应到score map上的某一个区域(颜色对应)。那么池化操作就是在该bin对应的score map上的子区域执行,且执行的是平均池化。我们在上一部分已经讲了,第 i 个bin应对在第 i 个score map上找响应值,那么也就是在第 i 个score map上的“该第 i 个bin对应的位置”上进行池化操作,且池化是取“bin这个范围内的所有值的平均值”。并且由于有(C+1)个类别,所以每个类别都要进行相同方式的池化。
以person为例,下图是position-sensitive score map的结果图。

position-sensitive regression
上面的 position-sensitive score map + Position-sensitive RoI pooling是用来分类的,得到的是类别的分值,那么怎么得到该类别的位置信息呢?即怎么做回归,从而达到4个数值(x、y、h、w)??
类似的,仿照分类的思想,在ResNet 的共享卷积层的最后一层接上一个与position-sensitive score map同级的score map,该score map的通道数应该是 4 k * k,经过
Position-sensitive RoI pooling之后,每一个RoI应该得到4个数作为‘该RoI坐标的长度和偏移量’
R-FCN的多任务损失函数

参考:
https://www.jianshu.com/p/409fd61db9db
https://zhuanlan.zhihu.com/p/30867916
Yolo
前面讲的都是基于Region Proposal的R-CNN系算法(R-CNN,Fast R-CNN, Faster R-CNN),它们是two-stage的,需要先使用启发式方法(selective search)或者CNN网络(RPN)产生Region Proposal,然后再在Region Proposal上做分类与回归。Yolo算法是one-stage算法,他们仅仅使用一个CNN网络就可以直接预测不同目标的类别和位置。
Yolo算法全称是其全称是You Only Look Once: Unified, Real-Time Object Detection:You Only Look Once说的是只需要一次CNN运算,Unified指的是这是一个统一的框架,提供end-to-end的预测,而Real-Time体现是Yolo算法速度快。
本文总结的主要是Yolo系列中的Yolo-v1版本。
Yolo将物体检测任务当成一个regression问题来处理(后面给出Yolo的损失函数可以看出),通过Yolo,只需要看每张图像一眼就能得到图像中有哪些物体和物体的位置。
其主要预测流程如下:
- 将图像resize到448 * 448 作为神经网络的输入
- 使用一个神经网络,直接从整张图像中预测出bbox的坐标、box中包含物体的置信度和物体的可能性
- 进行非极大值抑制,筛选Boxs
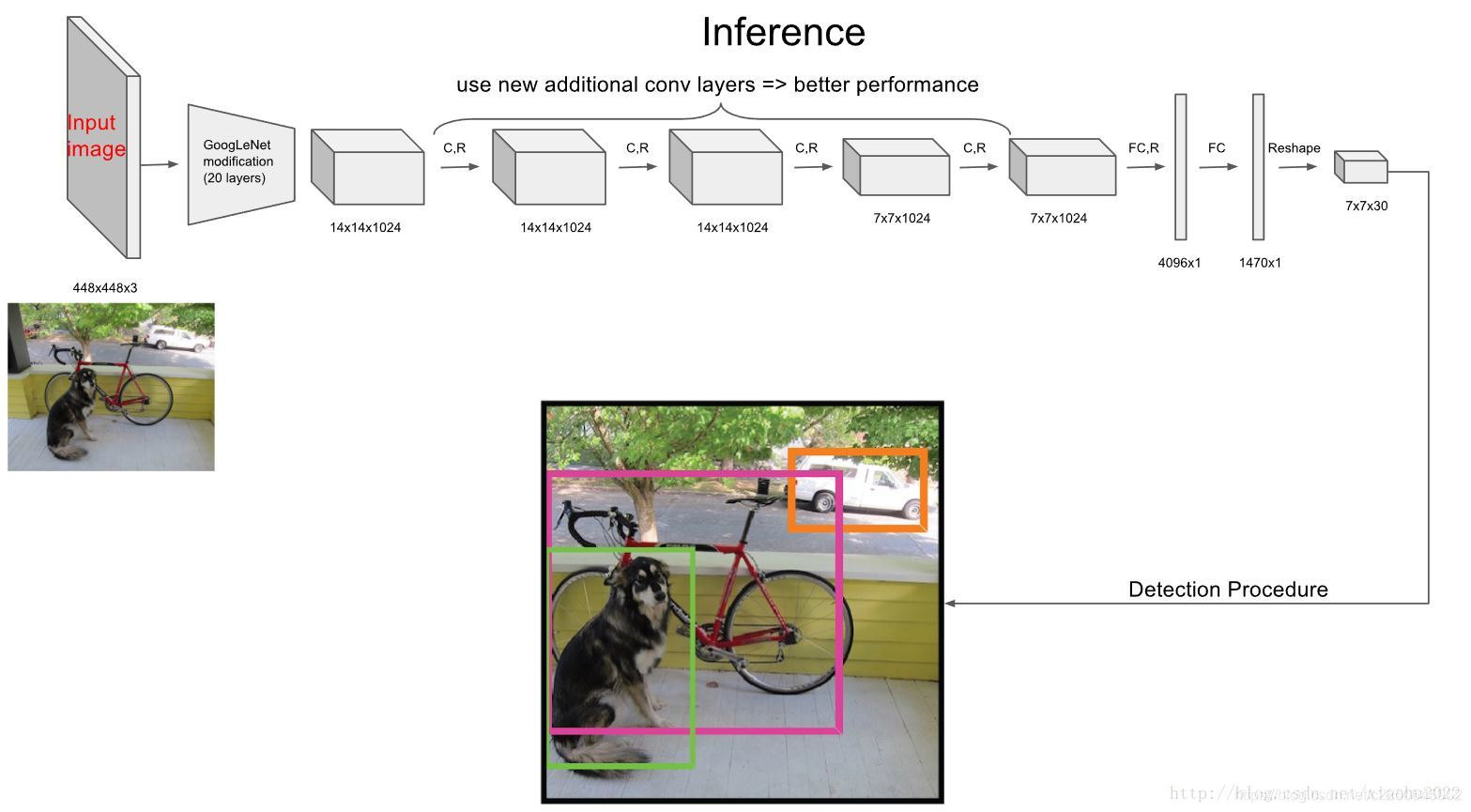
Yolo网络由24个卷积层和2个全连接层构成, 即Google Net作为基础网络结构。
图中网络输出是7 * 7 *30的张量,为什么输出是这个?各个数字分别代表什么意思?
Yolo把模型的输出划分成网格形状,每个网格中的cell(格子)都可以输出物体的类别和bounding box的坐标。
常见的是Yolo将图像分成S * S个格子(S = 7),然后每个格子负责检测落入该格子的物体。如图所示:

狗的中心落入了红色圆点在的格子,那么该格子就负责预测图像中的狗。每个格子预测B个bounding box(包含物体的矩形框)以及这些bboxes的confidence scores。常用的是B = 2,一个矩形框的信息包含(x,y,w,h,confidence)。
也就是说,每个bbox(注意是bbox而不是格子)有5个预测值,加起来共有10个预测值,作为预测的结果中每一行的前10个元素。
confidence反映当前bounding box是否包含物体以及物体位置的准确性,计算方式如下:
confidence = P(object) * IOU, 其中,若bounding box包含物体,则P(object) = 1;
否则,P(object) = 0.。IOU(intersection over union)为预测bounding
box与物体真实区域的交集面积(以像素为单位,用真实区域的像素面积归一化到[0,1]区间)
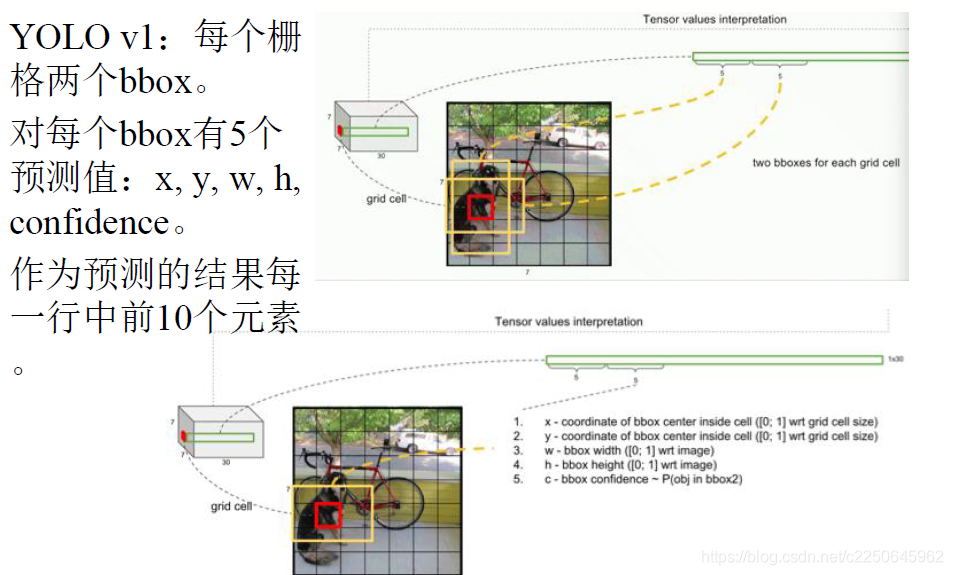
那为什么是7 * 7 * 30呢
因为每一个格子(注意是格子而不是bbox)还要预测C个条件类别概率:Pr(Class|Object),即在一个格子包含有一个object的前提下,它属于某个类的概率,预测20种物体,C = 20。

所以输出是7 * 7 * 30。
注意:条件概率类别是针对每个格子的,confidence是针对每个bbox的!!
在预测阶段,是将每个格子的条件类别概率与每个bbox的confidence相乘,如下:
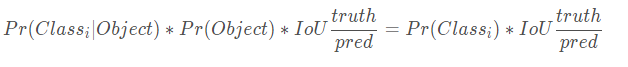
那我们怎么知道哪个格子该预测哪个物体呢??
这就涉及到我们是怎么去训练的,在训练阶段,如果物体中心落在这个cell,那么就给这个cell打上这个物体的label(包括xywh和类别)。也就是说我们是通过这种方式来设置训练的label的。换言之,我们在训练阶段,就教会cell要预测图像中的哪个物体。
这里要注意:虽然每个格子可以预测B个bounding box,但是最终只选择只选择IOU最高的bounding box作为物体检测输出,即每个格子最多只预测出一个物体。当物体占画面比例较小,如图像中包含畜群或鸟群时,每个格子包含多个物体,但却只能检测出其中一个。这是YOLO方法的一个缺陷。
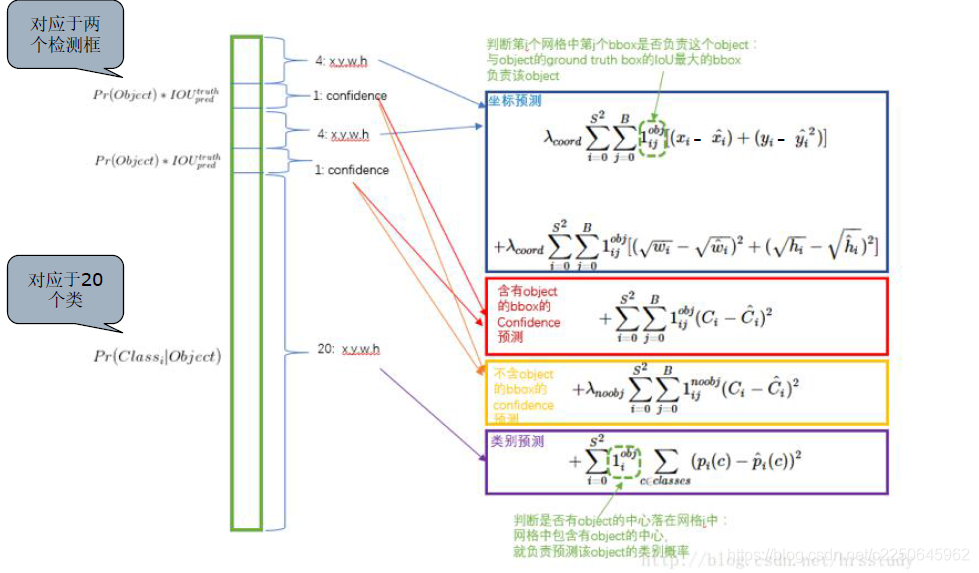
Yolo损失函数
Yolo损失函数如下,包含了坐标预测损失、含有object的bbox的confidence损失、不含有object的bbox的confidence损失和类别预测损失四个部分,每个部分都采用平方误差损失,这也说明了Yolo将目标检测看成是一个regression 问题。
结束
Yolo v1的优点:
- 检测速度很快,毕竟‘只需要看一眼’、、、
- 假阳性率低(YOLO网络将整个图像的全部信息作为上下文,在训练的过程中使用到了全图信息,能够更好的区分目标个背景区域)
- 能学到更加抽象的物体特征(网络层次深)
Yolo v1的不足:
- 检测精度低于其它的state - of - the - art物体检测系统
- 容易定位错误
- 对小物体的检测不好,尤其是密集的小物体,因为一个格子只能预测一个物体
参考:
https://zhuanlan.zhihu.com/p/37850811
https://blog.csdn.net/anqian123321/article/details/82118995
https://zhuanlan.zhihu.com/p/25236464
https://blog.csdn.net/qq_38232598/article/details/88695454
