多层感知机算法(学习记录)
1,为什么要引入多层感知机算法?
在训练感知机的时候使用的伪代码为
initialize w=0 and b=0
repeat
if [yi<w,xi>+b] <=0 then
w = w+yixi and b = b+yi
end if
untill all classified correct
如果分类正确 说明yi <w,xi>+b是一个正的值,否则说明分类错误,还需要进行继续向后传播。所以训练感知机的时候的损失函数可以定义为loss=Max(0,-y<w,x>),在在一个半径r内,y(wx+b)>=rou 的时候,分类两类。
但是是由于线性模型往往会出错,比如用线性模型实现xor的数据的时候,会没有办法很好的处理,因此使用多层感知机算法来训练模型。
2,在看李沐的多层感知机的算法实现的时候,注意到几个函数
一,loss = nn.CrossEntropyLoss(reduction=‘none’)这里的corssentropyLoss代表着交叉熵损失。那么什么是交叉熵?
1.1 信息量
(本节内容参考《深度学习花书》和《模式识别与机器学习》)
信息量的基本想法是:一个不太可能发生的事件居然发生了,我们收到的信息要多于一个非常可能发生的事件发生。
用一个例子来理解一下,假设我们收到了以下两条消息:
A:今天早上太阳升起
B:今天早上有日食
我们认为消息A的信息量是如此之少,甚至于没有必要发送,而消息B的信息量就很丰富。利用这个例子,我们来细化一下信息量的基本想法:①非常可能发生的事件信息量要比较少,在极端情况下,确保能够发生的事件应该没有信息量;②不太可能发生的事件要具有更高的信息量。事件包含的信息量应与其发生的概率负相关。
假设是一个离散型随机变量,它的取值集合为,定义事件的信息量为:
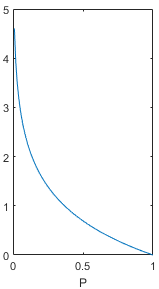
其中,log表示自然对数,底数为e(也有资料使用底数为2的对数)。公式中,为变量取值为的概率,这个概率值应该落在0到1之间,画出上面函数在P为0-1时的取值,图像如下。在概率值趋向于0时,信息量趋向于正无穷,在概率值趋向于1时,信息量趋向于0,这个函数能够满足信息量的基本想法,可以用来描述信息量。
1.2 熵
(本节内容参考《模式识别与机器学习》)
上面给出的信息量公式只能处理随机变量的取指定值时的信息量,我们可以用香农熵(简称熵)来对整个概率分布的平均信息量进行描述。具体方法为求上述信息量函数关于概率分布的期望,这个期望值(即熵)为:
让我们计算几个例题来对熵有个更深的了解。
1.3 相对熵(KL散度)
(本节内容参考《模式识别与机器学习》)
假设随机变量的真实概率分布为,而我们在处理实际问题时使用了一个近似的分布来进行建模。由于我们使用的是而不是真实的,所以我们在具体化的取值时需要一些附加的信息来抵消分布不同造成的影响。我们需要的平均附加信息量可以使用相对熵,或者叫KL散度(Kullback-Leibler Divergence)来计算,KL散度可以用来衡量两个分布的差异:
下面介绍KL散度的两个性质:
① KL散度不是一个对称量,
② KL散度的值始终0,当且仅当时等号成立****1.4 交叉熵****
1.4 交叉熵
终于到了主角交叉熵了,其实交叉熵与刚刚介绍的KL散度关系很密切,让我们把上面的KL散度公式换一种写法:
交叉熵就等于:
也就是KL散度公式的右半部分(带负号)。
细心的小伙伴可能发现了,如果把看作随机变量的真实分布的话,KL散度左半部分的其实是一个固定值,KL散度的大小变化其实是由右半部分交叉熵来决定的,因为右半部分含有近似分布,我们可以把它看作网络或模型的实时输出,把KL散度或者交叉熵看做真实标签与网络预测结果的差异,所以神经网络的目的就是通过训练使近似分布逼近真实分布。从理论上讲,优化KL散度与优化交叉熵的效果应该是一样的。所以我认为,在深度学习中选择优化交叉熵而非KL散度的原因可能是为了减少一些计算量,交叉熵毕竟比KL散度少一项。
在交叉熵这里,很感谢这位作者,原文链接放在下面http://t.csdn.cn/XPP3S
二,动手学深度学习-多层感知机中:updater = torch.optim.SGD(params, lr=lr),是干什么用的?
在这里的params里面包含着[w1,b1,w2,b2]需要不断的对这些参数进行随机下降梯度更新,而torch.optim是一个实现了各种优化算法的库。为了使用torch.optim,你需要构建一个optimizer对象。这个对象能够保持当前参数状态并基于计算得到的梯度进行参数更新。用起来比较方便。