前言
通过flink源码讲解,一起来进入flink的世界。以下是本篇文章正文内容,下面案例可供参考
系列文章目录:看flink源码学习flink
- 看flink源码学习flink----flink state
文章目录
flink之state
flink
Apache Flink® — Stateful Computations over Data Streams
数据流上的有状态计算
https://flink.apache.org/
为什么需要state?
● 容错
批计算:无,那么成功,那么重新计算。
流计算:failover机制
○ 大多数场景下是增量计算,数据逐条处理,每次计算依赖上次计算结果
○ 程序错误(机器,网络,脏数据)导致的重启job时从checkpoint进行state的恢复
● 容错机制,flink精准一次的容错机制。持续创建分布式数据流快照,快照轻量,对性能影响小,状态保存在一个可配置的环境中,master节点或者HDFS上。遇到程序故障(机器,网络,软件等),系统重启所有operator,重置到最近成功的checkpoint。输入重置到相应的状态快照位置,来保证被重启的并行数据流中处理的任何一个record都不是checkpoint状态之前的一部分。
为使容错机制生效,数据源(消息队列或者broker)需要能重放数据流。如flink-kafka-connector
论文:Lightweight Asynchronous Snapshots for Distributed Dataflows https://arxiv.org/abs/1506.08603 描述了flink创建快照的机制。
该论文基于 分布式快照算法 而来
checkpoint&savepoints
从概念上讲:Savepoint传统数据库中的备份,Checkpoint恢复日志的方法
● Flink 负责跨并行实例重新分配状态
● watermark
● barriers
barrier,被插入到数据流中,随数据一起流动,并将数据流分割成两部分,一部分进入当前快照,另一部分进入下一个快照,同时barrier携带快照ID。多个不同的快照的多个barrier会同时出现,即多个快照可能同时创建。
● element存储…
什么是state?
● 简单理解:
流式计算数据转瞬即逝,真实场景,往往需要之前的“数据”,故这些需要的“数据”被称之为state。也叫状态。
原始数据进入用户代码之后在输出到下游,如果中间涉及到state的读写,这些状态会存储在本地的state backend当中。
● 详细解释:
state是指流计算过程中计算节点的中间计算结果或元数据属性。
例如:
○ aggregation过程中中间的聚合结果。
○ 消费kafka中数据过程中读取记录的offset。
○ operator包含任何形式的形态,这些状态都必须包含在快照中,状态有很多种形式:
■ 用户自定义—由 transformation 函数例如( map() 或者 filter())直接创建或者修改的状态。用户自定义状态可以是:转换函数中的 Java 对象的一个简单变量或者函数关联的 key/value 状态。
■ 系统状态:这种状态是指作为 operator 计算中一部分缓存数据。典型例子就是: 窗口缓存(window buffers),系统收集窗口对应数据到其中,直到窗口计算和发射。
总结:flink任务的内部数据(计算数据和元数据属性)的快照。
● State一般指一个具体的task/operator的状态。
而Checkpoint则表示了一个Flink Job,在一个特定时刻的一份全局状态快照,即包含了所有task/operator的状态。
保存机制 StateBackend(状态后端) ,默认情况下,State 会保存在 TaskManager 的内存中,CheckPoint 会存储在 JobManager 的内存中。
State 和 CheckPoint 的存储位置取决于 StateBackend 的配置。基于内存的 MemoryStateBackend、基于文件系统的 FsStateBackend、基于RockDB存储介质的 RocksDBState-Backend
state定义:
根据state描述符定义
通过StateTtlConfiguration对象,传递给状态描述符,来实现状态的清理。
● 定义ttl(Time to Live)
● 状态生存时间
● 状态生存时间…
state分类:
● 是否属于某个key
○ key state:keyedStream保存状态
○ operator state:普通非key保存状态
● 是否受flink管理
○ raw state:应用程序自己管理
○ manage state:flink管理
● KeyedState
这里面的key是我们在SQL语句中对应的GroupBy/PartitioneBy里面的字段,key的值就是groupby/PartitionBy字段组成的Row的字节数组,每一个key都有一个属于自己的State,key与key之间的State是不可见的;
● OperatorState
Flink内部的Source Connector的实现中就会用OperatorState来记录source数据读取的offset。
| KeyedState | OperatorState | |
|---|---|---|
| 是否存在当前处理的key(current key) | 无 | 存在current key |
| 存储对象是否on heap | 仅有一种on-heap实现 | 有on-heap和off-heap(RocksDB)的多种实现 |
| 是否需要手动声明snapshot(快照)和restore(恢复) | 手动实现 | 由backend自行实现,对用户透明 |
| 数据大小 | 一般规模小 | 一般规模大 |
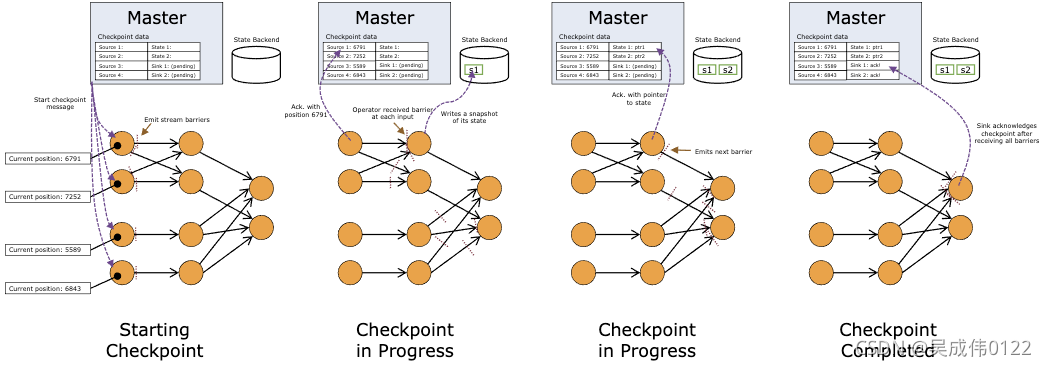
operator 在收到所有输入数据流中的 barrier 之后,在发射 barrier 到其输出流之前对其状态进行快照。此时,在 barrier 之前的数据对状态的更新已经完成,不会再依赖 barrier 之前数据。由于快照可能非常大,所以后端存储系统可配置。默认是存储到 JobManager 的内存中,但是对于生产系统,需要配置成一个可靠的分布式存储系统(例如 HDFS)。状态存储完成后,operator 会确认其 checkpoint 完成,发射出 barrier 到后续输出流。
快照现在包含了:
1、对于并行输入数据源:快照创建时数据流中的位置偏移
2、对于 operator:存储在快照中的状态指针
state创建(写入):
● flink将代码操作–>一个个task(放在taskmanager)—>每个task包含一个抽象类AbstractInvokable—>task的主要作用就是调用AbstractInvokable.invoke()–>该抽象方法有5种实现

● 流式处理中对应的实现均继承自StreamTask—>StreamTask抽象类中包含invoke()方法(大概150行代码)—>调用run()中
Runnable接口–>processInput(actionContext)–>inputProcessor.processInput():该方法完成用户输入数据的处理(用户数据、watermark、checkpoint数据)---->streamOperator.processElement(record) :streamOperator处理数据

StreamOneInputProcessor—>streamOperator.processElement(record);
● StreamTask:
定义完整生命周期,
protected abstract void init() throws Exception;
private void run() throws Exception {
};
protected void cleanup() throws Exception {
};
protected void cancelTask() throws Exception {
};
示例:OneInputStreamTask(处理一个输入情况)
TaskManage---->起task----> Task—>实现Runnable接口run()---->dorun():320行代码,创造invokable对象(反射–>得到类–>得到构造方法–>实例化对象)
private static AbstractInvokable loadAndInstantiateInvokable(
ClassLoader classLoader, String className, Environment environment) throws Throwable {
final Class<? extends AbstractInvokable> invokableClass;
try {
// 使用指定的classloader加载className对应的class,并转换为AbstractInvokable类型
invokableClass =
Class.forName(className, true, classLoader).asSubclass(AbstractInvokable.class);
} catch (Throwable t) {
throw new Exception("Could not load the task's invokable class.", t);
}
Constructor<? extends AbstractInvokable> statelessCtor;
try {
// 获取构造函数
statelessCtor = invokableClass.getConstructor(Environment.class);
} catch (NoSuchMethodException ee) {
throw new FlinkException("Task misses proper constructor", ee);
}
// instantiate the class
try {
//noinspection ConstantConditions --> cannot happen
// 传入environment变量,创建出新的对象
return statelessCtor.newInstance(environment);
} catch (InvocationTargetException e) {
// directly forward exceptions from the eager initialization
throw e.getTargetException();
} catch (Exception e) {
throw new FlinkException("Could not instantiate the task's invokable class.", e);
}
}
– invoke()
|
±—> Create basic utils (config, etc) and load the chain of operators
±—> operators.setup()
±—> task specific init()
±—> initialize-operator-states() : initializeState();
±—> open-operators()
±—> run()
±—> close-operators()
±—> dispose-operators()
±—> common cleanup
±—> task specific cleanup()
● Flink 基于 MailBox 实现的 StreamTask 线程模型
先来看下这个改造/改进最初的动机,在之前 Flink 的线程模型中,会有多个潜在的线程去并发访问其内部的状态,比如 event-processing 和 checkpoint triggering,它们都是通过一个全局锁(checkpoint lock)来保证线程安全,这种实现方案带来的问题是:
○ 锁对象会在多个类中传递,代码的可读性比较差
○ 在使用时,如果没有获取锁,可能会造成很多问题,使得问题难以定位
○ 锁对象还暴露给了面向用户的 API(见 SourceFunction#getCheckpointLock())
MailBox设计文档:

创建state
传参 抽象类StateDescriptor—>5种子类实现可以看到最终得到的state不限制state种类,operatorState & keyState
method来源于 RichFunction ,属于富函数基础接口,规定了 RuntimeContext
public interface RichFunction extends Function {
void open(Configuration parameters) throws Exception;
void close() throws Exception;
RuntimeContext getRuntimeContext();
IterationRuntimeContext getIterationRuntimeContext();
void setRuntimeContext(RuntimeContext t);
}
RuntimeContext接口—>抽象实现类AbstractRuntimeUDFContext—>实现类StreamingRuntimeContext
基于StreamingRuntimeContext(走其他实现类最终是一致的) ,getState(ValueStateDescriptor stateProperties)方法切入:
public <T> ValueState<T> getState(ValueStateDescriptor<T> stateProperties) {
// 检查工作,判断是否为null,最终还是操作 keyedStateStore 这个属性,只是局部变量又拿了一次引用地址
KeyedStateStore keyedStateStore = this.checkPreconditionsAndGetKeyedStateStore(stateProperties);
// 对序列化器进行初始化
stateProperties.initializeSerializerUnlessSet(this.getExecutionConfig());
return keyedStateStore.getState(stateProperties);
}
private KeyedStateStore checkPreconditionsAndGetKeyedStateStore(StateDescriptor<?, ?> stateDescriptor) {
// 检查这个 stateDescriptor 不能为null,该参数是由最初一直传递至此
Preconditions.checkNotNull(stateDescriptor, "The state properties must not be null");
// 该类自身的全局变量(属性、字段) keyedStateStore 不能为null
Preconditions.checkNotNull(this.keyedStateStore, "Keyed state can only be used on a 'keyed stream', i.e., after a 'keyBy()' operation.");
return this.keyedStateStore;
}
Keyed state can only be used on a ‘keyed stream’, i.e., after a ‘keyBy()’ operation.
判断为null的方法,flink内部会经常引用,StreamingRuntimeContext 静态导入了这个method,故可以直接调用,可以了解一下:
public static <T> T checkNotNull(@Nullable T reference, @Nullable String errorMessage) {
if (reference == null) {
throw new NullPointerException(String.valueOf(errorMessage));
} else {
return reference;
}
}
到这里需要注意一下,StreamingRuntimeContext 本身的属性 keyedStateStore 为null的话则要抛出空指针异常的,那么这个属性如何加载负值的,这个属性的作用见名知意,和state的存储是有关系的,接下来研究一下
这里有一个关键点,该类构造器接受了一个 AbstractStreamOperator<?> operator,keyedStateStore字段的初始化为 operator.getKeyedStateStore(),从这次大概可以得出一个结论,state的获取和算子(Operator,例如map,flatMap)有关系,
@VisibleForTesting
public StreamingRuntimeContext(AbstractStreamOperator<?> operator, Environment env, Map<String, Accumulator<?, ?>> accumulators) {
this(env, accumulators, operator.getMetricGroup(), operator.getOperatorID(), operator.getProcessingTimeService(), operator.getKeyedStateStore(), env.getExternalResourceInfoProvider());
}
public StreamingRuntimeContext(Environment env, Map<String, Accumulator<?, ?>> accumulators, MetricGroup operatorMetricGroup, OperatorID operatorID, ProcessingTimeService processingTimeService, @Nullable KeyedStateStore keyedStateStore, ExternalResourceInfoProvider externalResourceInfoProvider) {
super(((Environment)Preconditions.checkNotNull(env)).getTaskInfo(), env.getUserCodeClassLoader(), env.getExecutionConfig(), accumulators, env.getDistributedCacheEntries(), operatorMetricGroup);
this.taskEnvironment = env;
this.streamConfig = new StreamConfig(env.getTaskConfiguration());
this.operatorUniqueID = ((OperatorID)Preconditions.checkNotNull(operatorID)).toString();
this.processingTimeService = processingTimeService;
this.keyedStateStore = keyedStateStore;
this.externalResourceInfoProvider = externalResourceInfoProvider;
}
keyedStateStore 等价于 operator.getKeyedStateStore(),而operator 又是由AbstractStreamOperator<?> operator创建
AbstractStreamOperator
public final void initializeState(StreamTaskStateInitializer streamTaskStateManager) throws Exception {
TypeSerializer<?> keySerializer = this.config.getStateKeySerializer(this.getUserCodeClassloader());
StreamTask<?, ?> containingTask = (StreamTask)Preconditions.checkNotNull(this.getContainingTask());
CloseableRegistry streamTaskCloseableRegistry = (CloseableRegistry)Preconditions.checkNotNull(containingTask.getCancelables());
StreamOperatorStateContext context = streamTaskStateManager.streamOperatorStateContext(this.getOperatorID(), this.getClass().getSimpleName(), this.getProcessingTimeService(), this, keySerializer, streamTaskCloseableRegistry, this.metrics, this.config.getManagedMemoryFractionOperatorUseCaseOfSlot(ManagedMemoryUseCase.STATE_BACKEND, this.runtimeContext.getTaskManagerRuntimeInfo().getConfiguration(), this.runtimeContext.getUserCodeClassLoader()), this.isUsingCustomRawKeyedState());
this.stateHandler = new StreamOperatorStateHandler(context, this.getExecutionConfig(), streamTaskCloseableRegistry);
this.timeServiceManager = context.internalTimerServiceManager();
this.stateHandler.initializeOperatorState(this);
// 这里 setKeyedStateStore 就是给 StreamingRuntimeContext.keyedStateStore 修改值
this.runtimeContext.setKeyedStateStore((KeyedStateStore)this.stateHandler.getKeyedStateStore().orElse((Object)null));
}
keyedStateStore—>是由StreamOperatorStateHandler创建
public StreamOperatorStateHandler(StreamOperatorStateContext context, ExecutionConfig executionConfig, CloseableRegistry closeableRegistry) {
this.context = context;
this.operatorStateBackend = context.operatorStateBackend();
this.keyedStateBackend = context.keyedStateBackend();
this.closeableRegistry = closeableRegistry;
if (this.keyedStateBackend != null) {
// 创建了keyedStateStore
this.keyedStateStore = new DefaultKeyedStateStore(this.keyedStateBackend, executionConfig);
} else {
this.keyedStateStore = null;
}
}
总结:即状态后端不存在,即生成默认,初次为空。
可能会好奇 initializeState 是什么时候被谁调用的
它来自于 算子链,flink会把满足条件的多个算子合并成算子链(OperatorChain),那么在调度的时候一个task其实就是执行一个OperatorChain,多个并行度时则多个task每个都执行一份OperatorChain
抽象父类AbstractInvokable---->抽象子类StreamTask—>invoke()—>initializeState(); openAllOperators();
initializeState();
private void initializeState() throws Exception {
StreamOperator<?>[] allOperators = operatorChain.getAllOperators();
for (StreamOperator<?> operator : allOperators) {
if (null != operator) {
operator.initializeState();
}
}
}
openAllOperators();
private void openAllOperators() throws Exception {
for (StreamOperator<?> operator : operatorChain.getAllOperators()) {
if (operator != null) {
operator.open();
}
}
}
stateProperties.initializeSerializerUnlessSet(getExecutionConfig());
这个函数调用其实是来到了 StateDescriptor,之前有看到所有的状态都是其子类
方法上的注释含义: 初始化序列化器,除非它之前已经初始化
//描述值类型的类型信息。只有在序列化器是惰性创建时才使用。
private TypeInformation<T> typeInfo;
//类型的序列化器。可能在构造函数中被急切地初始化,或者被惰性地初始化一次
public boolean isSerializerInitialized() {
return serializerAtomicReference.get() != null;
}
public void initializeSerializerUnlessSet(ExecutionConfig executionConfig) {
// 先判断这个序列化器是否已经被创建,这个类代码比较简单,如下看看就好,
// 如上看到调用默认构造器,则该对象的value字段为null,第一次代码到这里必定为null
if (serializerAtomicReference.get() == null) {
// 判断 typeInfo 是否为null,下面有代码剖析构造器这块
checkState(typeInfo != null, "no serializer and no type info");
// 尝试实例化和设置序列化器,这里是使用类型来创建序列化器,可以看到该处逻辑每执行一次就会创建一个序列化器
TypeSerializer<T> serializer = typeInfo.createSerializer(executionConfig);
// use cas to assure the singleton
// 使用cas来保证单例,此处就是创建核心, compareAndSet 下面剖析
if (!serializerAtomicReference.compareAndSet(null, serializer)) {
LOG.debug("Someone else beat us at initializing the serializer.");
}
}
}
state清除
为什么需要state清除?
● state时效性:在一定时间内是有效的,一旦过了某个时间点,就没有应用价值
● 控制flink state大小:管理不断增长的state规模大小
如何定义state清除?
flink1.6引入State TTL功能,开发人员配置过期时间,并定义时间超时(Time to Live)之后进行清除,
通过StateTtlConfiguration对象,传递给状态描述符,来实现状态的清理。
对RocksDB以及堆state backend(FSStateBackend和MemoryStateBackend)的历史数据进行持续清理,从而实现过期state的连续清理
示例代码
public class StateDemo {
public static void main(String[] args) throws Exception {
LocalStreamEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
// this can be used in a streaming program like this (assuming we have a StreamExecutionEnvironment env)
env.fromElements(Tuple2.of(1L, 3L), Tuple2.of(1L, 5L), Tuple2.of(1L, 10L), Tuple2.of(1L, 4L), Tuple2.of(1L, 2L))
.keyBy(0)
.flatMap(new MyFlatMapFunction())
.print();
// the printed output will be (1,4) and (1,5)
env.execute();
}
}
class MyFlatMapFunction extends RichFlatMapFunction<Tuple2<Long, Long>, Tuple2<Long, Long>> {
private static final long serialVersionUID = 1808329479322205953L;
/**
* The ValueState handle. The first field is the count, the second field a running sum.
*/
private transient ValueState<Tuple2<Long, Long>> sum;
// 状态过期清除
// flink 的状态清理是惰性策略,也就是我们访问的状态,可能已经过期了,但是还没有删除状态数据,我们可以配置
// 是否返回过期状态的数据,不论是否返回过期数据,数据被访问后会立即清除过期状态。并且截止1.8.0 的版本
// 状态的清除针对的是process time ,还不支持event time,可能在后期的版本中会支持。
// flink的内部,状态ttl 功能是通过上次相关状态访问的附加时间戳和实际状态值来实现的,这样的方案会增加存储
// 上的开销,但是会允许flink程序在查询数据,cp的时候访问数据的过期状态
StateTtlConfig ttlConfig =
StateTtlConfig.newBuilder(Time.days(1)) //它是生存时间值
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
//状态可见性配置是否在读取访问时返回过期值
// .setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.cleanupFullSnapshot() // 在快照的时候进行删除
.build();
@Override
public void flatMap(Tuple2<Long, Long> input, Collector<Tuple2<Long, Long>> out) throws Exception {
// access the state value
Tuple2<Long, Long> currentSum = sum.value();
// update the count
currentSum.f0 += 1;
// add the second field of the input value
currentSum.f1 += input.f1;
// update the state
sum.update(currentSum);
// if the count reaches 2, emit the average and clear the state
if (currentSum.f0 >= 2) {
out.collect(new Tuple2<>(input.f0, currentSum.f1 / currentSum.f0));
sum.clear();
}
}
@Override
public void open(Configuration config) {
ValueStateDescriptor<Tuple2<Long, Long>> descriptor =
new ValueStateDescriptor<>(
"average", // the state name
TypeInformation.of(new TypeHint<Tuple2<Long, Long>>() {
}), // type information
Tuple2.of(0L, 0L)); // default value of the state, if nothing was set
//设置stage过期时间
descriptor.enableTimeToLive(ttlConfig);
sum = getRuntimeContext().getState(descriptor);
}
}
核心代码
StateTtlConfig ttlConfig =
StateTtlConfig.newBuilder(Time.days(1)) //它是生存时间值
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
//状态可见性配置是否在读取访问时返回过期值
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.setTtlTimeCharacteristic(StateTtlConfig.TtlTimeCharacteristic.ProcessingTime)
.cleanupFullSnapshot() // 在快照的时候进行删除
.build();
flink 1.9
private StateTtlConfig(
UpdateType updateType,
StateVisibility stateVisibility,
TtlTimeCharacteristic ttlTimeCharacteristic,
Time ttl,
CleanupStrategies cleanupStrategies) {
this.updateType = checkNotNull(updateType);
this.stateVisibility = checkNotNull(stateVisibility);
this.ttlTimeCharacteristic = checkNotNull(ttlTimeCharacteristic);
this.ttl = checkNotNull(ttl);
this.cleanupStrategies = cleanupStrategies;
checkArgument(ttl.toMilliseconds() > 0, "TTL is expected to be positive.");
}
● .newBuilder()
:表示state过期时间,一旦设置,上次访问时间戳+TTL超过当前时间,标记状态过期
具体实现:
https://ci.apache.org/projects/flink/flink-docs-master/api/java/org/apache/flink/runtime/state/ttl/class-use/TtlTimeProvider.html
● .setUpdateType() 可以看下源码
setUpdateType(StateTtLConfig.UpdateType.OnCreateAndWrite)
表示状态时间戳的更新的时机,是一个 Enum 对象。
○ Disabled, 则表明不更新时间戳;
○ OnCreateAndWrite,则表明当状态创建或每次写入时都会更新时间戳;
○ OnReadAndWrite, 则除了在状态创建和写入时更新时间戳外,读取也会更新状态的时间戳。
● .setStateVisibility()
表示对已过期但还未被清理掉的状态如何处理,也是 Enum对象。
○ ReturnExpiredlfNotCleanedUp, 那么即使这个状态的时间 戳表明它已经过期了,但是只要还未被真正清理掉,就会被返回给调用方;
○ NeverReturnExpired, 那么一旦这个状态过期 了,那么永远不会被返回给调用方,只会返回空状态,避免了过期状态带来的干扰。
● .setTtlTimeCharacteristic(StateTtlConfig.TtlTimeCharacteristic.ProcessingTime)
TimeCharacteristic 以及TtlTimeCharacteristic:表示 State TTL功能所适用的时间模式,仍然是 Enum 对象。
前者已经被标记为 Deprecated(废弃),推荐新代码采用新的TtlTimeCharacteristic参数。
截止到 Flink 1.8,只支持ProcessingTime 一种时间模式,对 EventTime 模式的 State TTL支持还在开发中。(看1.9同样只支持ProcessingTime)
flink时间概念
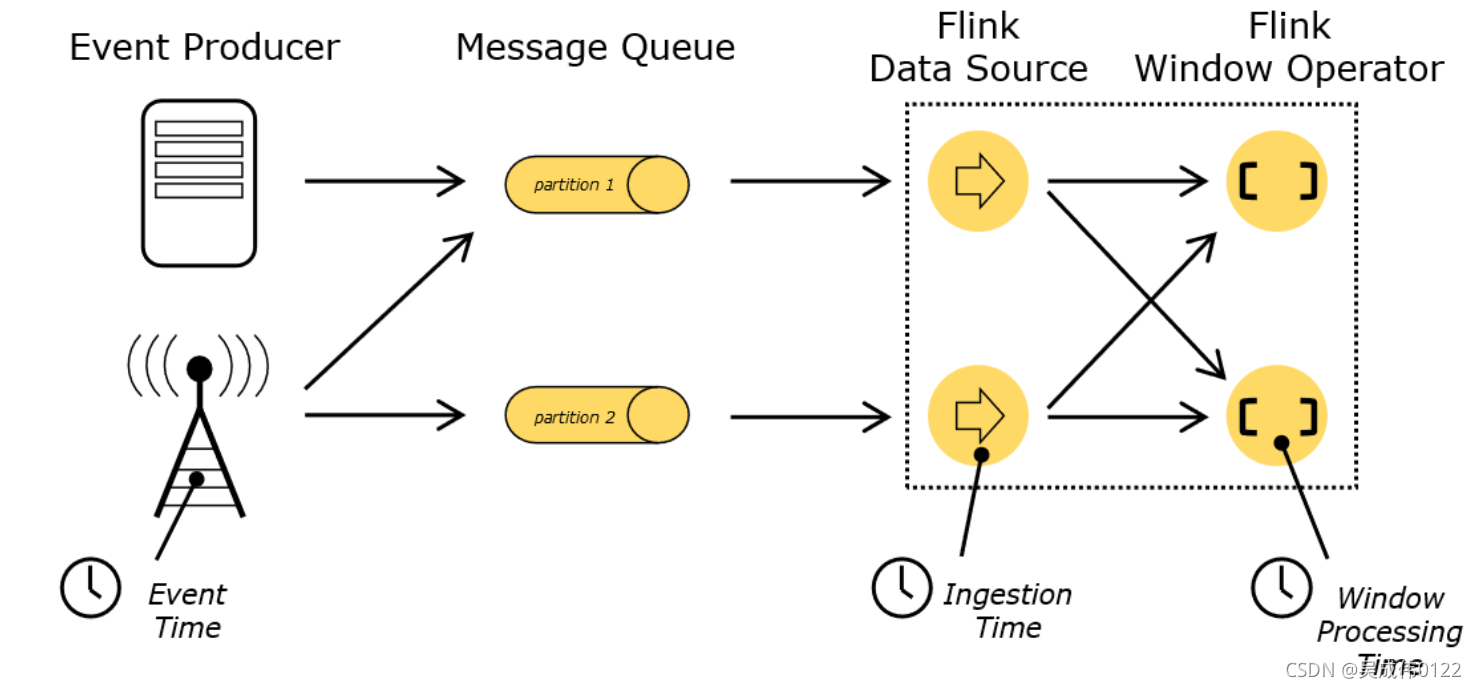
○ EventTime:事件创建时间
○ Processing Time:数据流向每一个基于时间操作算子的本地系统时间,默认
○ Ingestion Time:数据进入flink的时间
● .cleanupFullSnapshot():看源码
表示过期对象的清理策略,目前来说有三种 Enum 值。
○ FULL_STATE_SCAN_SNAPSHOT:对应的是 EmptyCleanupStrategy 类,表示对过期状态不做主动清理,当执行完整快照(Snapshot / Checkpoint) 时,会生成一个较小的状态文件,但本地状态并不会减小。唯有当作业重启并从上一个快照点恢复后,本地状态才会实际减小,因此可能仍然不能解决内存压力的问题。
为了解决内存压力问题,Flink还提供了增量清理的枚举值,Flink可以被配置为每读取若干条记录就执行一次清理操作,而且可以指定每次要清理多少条失效记录:
○ INCREMENTAL_CLEANUP:针对 Heap StateBackend
○ ROCKSDB_COMPACTION_FILTER(1.9已废弃)针对RocksDB StateBackend,对于 RocksDB 的状态清理,则是通过JNI来调用 C++语言编写的 FlinkCompactionFilter 来实现,底层是通过 RocksDB提供的后台 Compaction 操作来实现对失效状态过滤的。
常见问题:
● 过去的状态数据是否可以访问?
状态过期清除, flink 的状态清理是惰性策略,也就是我们访问的状态,可能已经过期了,但是还没有删除状态数据,我们可以配置是否返回过期状态的数据,不论是否返回过期数据,数据被访问后会立即清除过期状态。
Flink内部,状态TTL功能是通过存储上次相关状态访问的附加时间戳以及实际状态值来实现的。虽然这种方法增加了一些存储开销,但它允许Flink程序在查询数据、checkpointing,数据恢复的时候访问数据的过期状态。
值得注意:
并且截止1.8.0 的版本,状态的清除针对的是process time ,还不支持event time,用户只能根据处理时间(Processing Time)定义状态TTL。未来的Apache Flink版本中计划支持事件时间(Event Time)
● 如何避免读取过期数据?
在读取操作中访问状态对象时,Flink将检查其时间戳并清除状态是否已过期(取决于配置的状态可见性,是否返回过期状态)。由于这种延迟删除的特性,永远不会再次访问的过期状态数据将永远占用存储空间,除非被垃圾回收。
那么如何在没有应用程序逻辑明确的处理它的情况下删除过期的状态呢?通常,我们可以配置不同的策略进行后台删除。
○ 完整快照自动删除过期状态
○ 堆状态后端的增量清理
○ RocksDB后台压缩可以过滤掉过期状态
○ 使用定时器删除(Timers)
state存储实现?
Flink 如何保存状态数据,有个接口StateBackend—>抽象类AbstractStateBackend,有3个实现
● MemoryStateBackend,基于内存的HeapStateBackend
在debug模式使用,不建议在生产模式下应用
● 基于HDFS的FsStateBackend
分布式文件持久化,每次读写都操作内存,需考虑OOM问题
● 基于RocksDB的RocksDBStateBackend
本地文件+异地HDFS持久化
默认是StateBackendLoader,加载的是RocksDBStateBackend
State存储过程
两阶段
- 先本地存储到RocksDB
- 在异步同步到远程HDFS
目的:既消除了HeapStateBackend的局限(内存大小,机器坏掉丢失等),也减少了纯分布式存储的网络IO开销。
总结
以上就是今天要讲的内容。