Flink在管理状态方面,使用Checkpoint和Savepoint实现状态容错。Flink的状态在计算规模发生变化的时候,可以自动在并行实例间实现状态的重新分发,底层使用State Backend策略存储计算状态,State Backend决定了状态存储的方式和位置。
Flink在状态管理中将所有能操作的状态分为Keyed State和Operator State。
Keyed State类型的状态同key一一绑定,并且只能在KeyedStream中使用。所有non-KeyedStream状态操作都叫做Operator State。Flink在底层做状态管理时,将Keyed State和<parallel-operator-instance, key>关联,由于某一个key仅仅落入其中一个operator-instance中,因此可以简单的理解Keyed State是和<operator,key>进行绑定的,采用Key Group机制对Keyed State进行管理或者分类,所有的keyed-operator在做状态操作的时候可能需要和1~n个Key Group进行交互。
Flink在分发Keyed State状态的时候,不是以key为单位,而是以Key Group为最小单元分发
Operator State (也称为 non-keyed state),每一个operator state 会和一个parallel operator instance进行绑定。
Keyed State 和 Operator State 以两种形式存在( managed(管理)和 raw(原生)),所有Flink已知的操作符都支持Managed State,但是Raw State仅仅在用户自定义Operator时使用,并且不支持在并行度发生变化的时候重新分发状态,因此,虽然Flink支持Raw State,但是在绝大多数的应用场景下,一般使用的都是Managed State。
关于flink的六大keyedState如何使用,博主在之前的博文已经用java和scala两种语言分享过,可点击 链接:https://blog.csdn.net/qq_44962429/article/details/104428236查看。
本文主要介绍flink的TTL,State backend,Clear Sate,样例采用scala语言描述。
1、flink TTL(Time To Live)
flink可以将state存活时间(TTL)分配给任何类型的keyed-state,如果配置了TTL且状态值已过期,则Flink将尽力清除存储的历史状态值。
配置简介:
import org.apache.flink.api.common.state.StateTtlConfig
import org.apache.flink.api.common.state.ValueStateDescriptor
import org.apache.flink.api.common.time.Time
val ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(5))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build
val stateDescriptor = new ValueStateDescriptor[String]("text state", classOf[String])
stateDescriptor.enableTimeToLive(ttlConfig)
① newBuilder(Time.seconds(5)) :设置state的过期时间为1s过期。
② setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite):设置state过期时间的修改策略,样例采用创建和读取的时候修改过期时间,如10:00:00创建了state,在10:00:02的时候查询或者修改了state,那么state的过期时间重10:00:02的时间点重新计时,10:00:07的时候state的才过期。
③ setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired) :设置过期state的可见性,永不反悔过期数据。
注意:开启TTL之后,系统会额外消耗内存存储时间戳(Processing Time),如果用户以前没有开启TTL配置,在启动之前修改代码开启了TTL,在做状态恢复的时候系统启动不起来,会抛出兼容性失败以及StateMigrationException的异常。
2、Expired State
在默认情况下,仅当明确读出过期状态时,通过调用ValueState.value()方法才会清除过期的数据,这意味着,如果系统一直未读取过期的状态,则不会将其删除,可能会导致存储状态数据的文件持续增长。
接下来具体介绍flink支持的几种清除state策略。
(1)Cleanup in full snapshot
系统会从上一次状态恢复的时间点,加载所有的State快照,在加载过程中会剔除那些过期的数据,这并不会影响磁盘已存储的状态数据,该状态数据只会在Checkpoint的时候被覆盖,但是依然解决不了在运行时自动清除过期且没有用过的数据。
import org.apache.flink.api.common.state.StateTtlConfig
import org.apache.flink.api.common.time.Time
val ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.cleanupFullSnapshot
.build
注意:因为此种清除方式只会在状态恢复的时候触发,而且只能用于memory或者snapshot状态的后端实现,不支持RocksDB State Backend,所以在实际生产环境中,不推荐使用。
(2)Cleanup in background
可以开启后台清除策略,根据State Backend采取默认的清除策略(不同状态的后端存储,清除策略不同)
import org.apache.flink.api.common.state.StateTtlConfig
val ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.cleanupInBackground
.build
基于stateBackend又分为两种,一种是基于memory backend,一种基于RocksDB
- memory backend
import org.apache.flink.api.common.state.StateTtlConfig
val ttlConfig = StateTtlConfig.newBuilder(Time.seconds(5))
.setUpdateType(UpdateType.OnCreateAndWrite)
.setStateVisibility(StateVisibility.NeverReturnExpired)
.cleanupIncrementally(100,true) // 默认值 5 | false
.build()
第一个参数表示每一次触发cleanup的时候,系统会一次处理100个元素。第二个参数是false,表示只要用户对任意一个state进行操作,系统都会触发cleanup策略;第二个参数是true,表示只要系统接收到记录数(即使用户没有操作状态)就会触发cleanup策略。
- RocksDB
RocksDB是一个嵌入式的key-value存储,其中key和value是任意的字节流,底层进行异步压缩,会将key相同的数据进行compact(压缩),以减少state文件大小,但是并不对过期的state进行清理,因此可以通过配置compactFilter,让RocksDB在compact的时候对过期的state进行排除,RocksDB数据库的这种过滤特性,默认关闭,如果想要开启,可以在flink-conf.yaml中配置 state.backend.rocksdb.ttl.compaction.filter.enabled:true 或者在应用程序的API里设置RocksDBStateBackend::enableTtlCompactionFilter。
以下图片描述了compact的过程和compactFilter的过程。
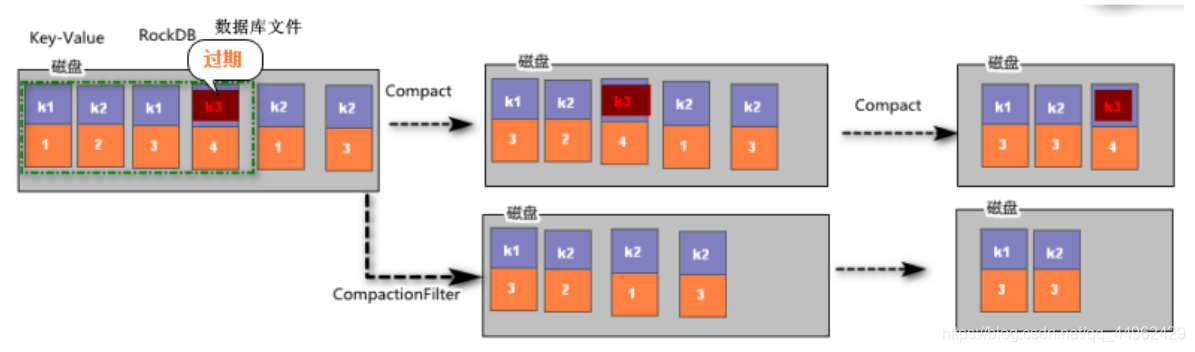
import org.apache.flink.api.common.state.StateTtlConfig
val ttlConfig = StateTtlConfig.newBuilder(Time.seconds(5))
.setUpdateType(UpdateType.OnCreateAndWrite)
.setStateVisibility(StateVisibility.NeverReturnExpired)
.cleanupInRocksdbCompactFilter(1000) //默认配置1000
.build()
这里的1000表示,系统在做Compact的时候,会检查1000个元素是否失效,如果失效,则清除该过期数据。
3、state backend
State Backend决定Flink如何存储系统状态信息(Checkpoint形式),目前Flink提供了三种State Backend实现。
- Memory (JobManagwer):这是Flink的默认实现,通常用于测试,系统会将计算状态存储在JobManagwer的内存中,但是在实际的生产环境中,由于计算的状态比较多,使用Memory 很容易导致OOM(out of memory)。
- FileSystem:系统会将计算状态存储在TaskManager的内存中,因此一般用作生产环境,系统会根据CheckPoin机制,将TaskManager状态数据在文件系统上进行备份。如果是超大规模集群,TaskManager内存也可能发生溢出。
- RocksDB:系统会将计算状态存储在TaskManager的内存中,如果TaskManager内存不够,系统可以使用RocksDB配置本地磁盘完成状态的管理,同时支持将本地的状态数据备份到远程文件系统,因此,RocksDB Backend 是推荐的选择。
每一个Job都可以配置自己状态存储的后端实现
var env=StreamExecutionEnvironment.getExecutionEnvironment
val fsStateBackend:StateBackend = new FsStateBackend("hdfs:///xxx") //MemoryStateBackend、FsStateBackend、RocksDBStateBackend
env.setStateBackend(fsStateBackend)
考虑到生产环境状态state可能比较大,建议使用RocksDBStateBackend。
好了,博主在文章开头已经提过了,flink state分为keyedstate和operator state,keyedstate已经在之前的博文中我分享过,有需要的伙伴可以点击 https://blog.csdn.net/qq_44962429/article/details/104428236查看,在接下来的分享中,博主介绍一下operator state。