摘要:本文整理自 bilibili 资深开发工程师张杨,在 Flink Forward Asia 2022 核心技术专场的分享。本篇内容主要分为四个部分:
- 相关背景
- state 压缩优化
- Remote state 探索
- 未来规划
一、相关背景
1.1 业务概况

- 从业务规模来讲,B 站目前大约是 4000+的 Flink 任务,其中 95%是 SQL 类型。
- 从部署模式来讲,B 站有 80%的部署是 on yarn application 部署,我们的 yarn 集群和离线的 yarn 是分开的,是实时专用的 yarn 集群。剩下的 20%作业,为了响应公司降本增效的号召,目前是在线集群混部。这个方案的采用主要是从成本考虑,目前在使用 yarn on docker。
从 state 使用情况来讲,平台默认开启的全部是 rocksdb statebackend,大概有 50%的任务都是带状态的,其中有上百个任务的状态超过了 500GB,这种任务我们称之为超大状态的 state 任务。
1.2 statebackend 痛点

主要痛点有 3 个:
-
cpu 抖动大。rocksdb 的原理决定了它一定会有一个 compaction 的操作。目前,在小状态下这种操作对任务本身没什么影响,但是在大状态下,尤其是超过 500GB 左右,compaction 会造成 cpu 抖动大,峰值资源要求高。尤其是在 5、10、15 分钟这种 checkpoint 的整数被间隔的情况下,整个 cpu 的起伏会比较高。对于一个任务来说,它的峰值资源要求会比较高。如果我们的资源满足不了峰值资源的需求,任务就会触发一阵阵的堆积和消积的情况。
-
恢复时间长。因为 rocksdb 是一个嵌入式的 DB 存储,每次重启或者任务的 rescale 状态恢复时间长。因为它要把很大的文件下载下来,然后再在本地进行一些重新的 reload,这就需要一些大量的扫描工作,所以会导致整个任务的状态恢复时间比较长。观察下来,正常来说大任务基本需要 5 分钟左右才能恢复平稳的状态。
-
rocksdb 非常依赖本地磁盘。rocksdb 是嵌入式的 DB,所以会非常依赖本地 io 的能力。由于今年公司有降本增效的策略,我们也会在线推荐一些混部,因为 Flink 的带状态任务有对本地 io 依赖的特点,对于混部来讲是没法用的,这就导致我们使用混部的资源是非常有限的。

主要通过两个方面解决这些痛点:
- 第一个是 state 压缩。出于对如何降低 compaction 开销的思考,对任务进行了一些 cpu 火焰图的分析。通过分析发现,整个 cpu 的消耗主要在 2 个方面,一个是 compaction,一个是压缩数据的换进换出,这就会带来大量的压缩和解压缩的工作。所以我们在压缩层做了一些工作。
- 第二个是基于云原生的部署。由于本地没有 io 能力,我们参考了一些云原生的方案,把整个本地的 rocksdb backend 进行了 Remote state 的升级。这相当于上面的一个存算分离,然后远程进行了服务化的操作。这样就可以实现即连即用,不需要进行 reload 的操作,整个 state 是基于远程化进行的。
二、state 压缩优化
2.1 业务场景
从业务场景角度来看,大 state 分析下来,它主要集中于模型训练和样本拼接。我们的商业化和 AI 推荐部门就是这种典型的应用场景。它的特点就是 key 数据量庞大,分布稀疏,很难命中 cache。且数据 ttl 短,基本都是小时级。
如下右图所示,整个业务的模型包含展现和点击。通过这两个动作我们进行了校验,然后完成计算,从而生成样本,再灌入模型进行训练。这个场景下它的特点是缓存失效就很快失效,它的 key 数量比较大且比较稀疏。
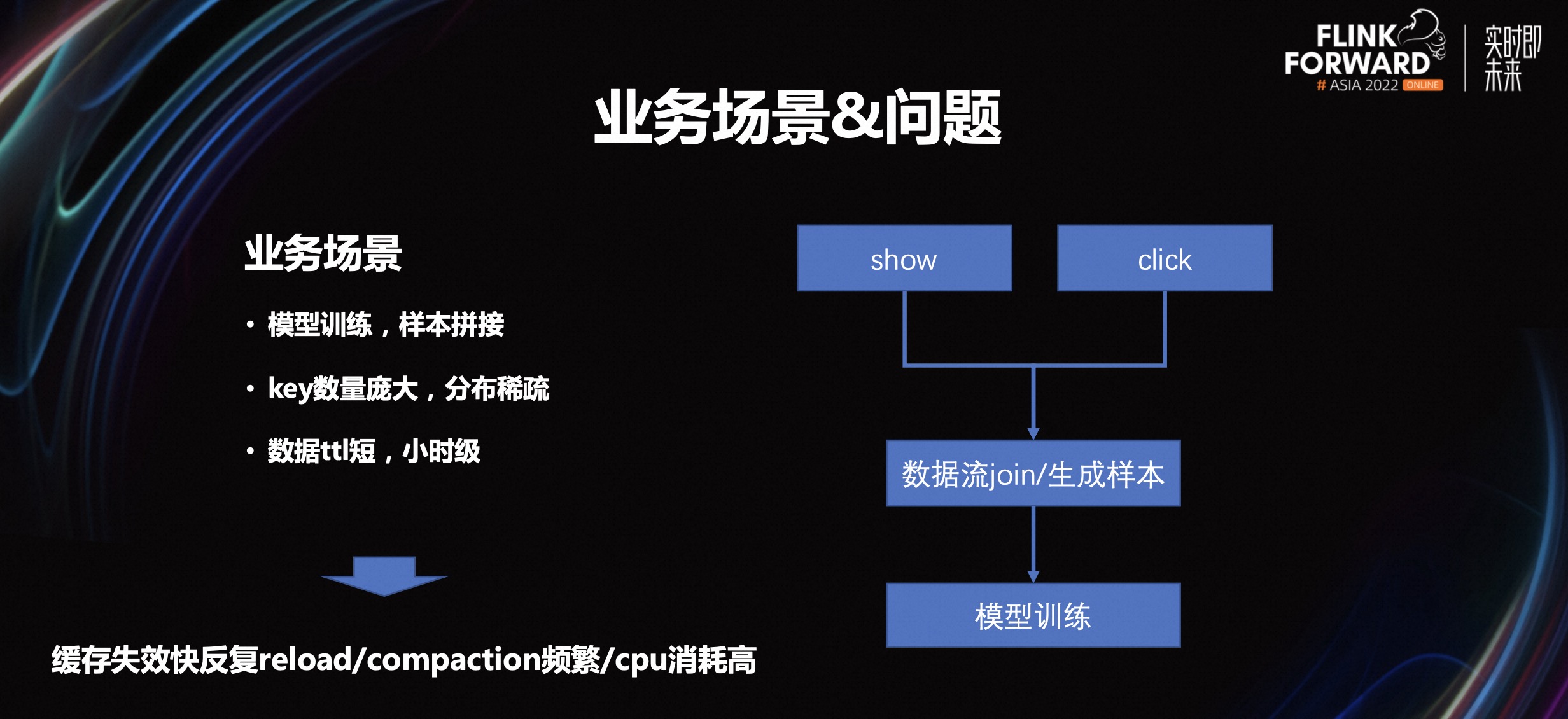
第二个点是数据的提交比较短,那么整个缓存的失效会比较快,这样就会导致 rocksdb 在使用的时候会反复从磁盘里不断地 reload 数据,然后进行压缩和解压缩,或者中间 compaction 数据不断地过期,导致 compaction 过于频繁。
2.2 优化思路

以上两个问题会导致整个 cpu 的消耗非常高,所以我们能观察到,在前面提及的整个任务的峰值 cpu 消耗会非常高。我们的优化思路是通过包括对社区的一些方案和业界其他公司分享的一些文章进行的调研,调研和优化方案主要围绕三个方面进行:
-
第一个是开启 partitoned index filter,减少缓存竞争。从火焰图中可以看到,data block 会不断地从 block cache 中被换进换出,同时产生大量的压缩和解压缩工作,大量的 cpu 其实消耗在这里。
-
第二个是关闭 rocksdb 压缩,减少缓存加载 /compaction 时候的 cpu 消耗。从火焰图中可以看到,整个 SSD 数据进行底层生成的时候,它会不断地进行整个文件的压缩和解压缩。所以我们的思路就是如何去关闭一些 rocksdb 压缩,减少整个缓存加载或者 cpu 的消耗。
-
第三个是支持接口层压缩,在数据 state 读写前后进行解压缩操作,减少 state 大小。如果关闭 rocksdb 底层的压缩,我们观察到整个磁盘的使用量非常高。这样的话,压力就是从压缩和解压缩的 cpu 消耗变成磁盘的 io 消耗,磁盘的 io 很容易就被消耗尽了。所以我们就把整个底层的压缩往上层进行了一个牵引,支持接口层的压缩。
在数据层写入读写前后进行压缩和解压缩的操作,减少底层的存储大小,我们也与内部的一些 DB 存储团队进行了一些沟通,他们一般建议在上层进行压缩,这样会比在底层做效率更高一些。因为底层整个是以 Block 维度进行压缩与解压缩的。
2.3 整体架构
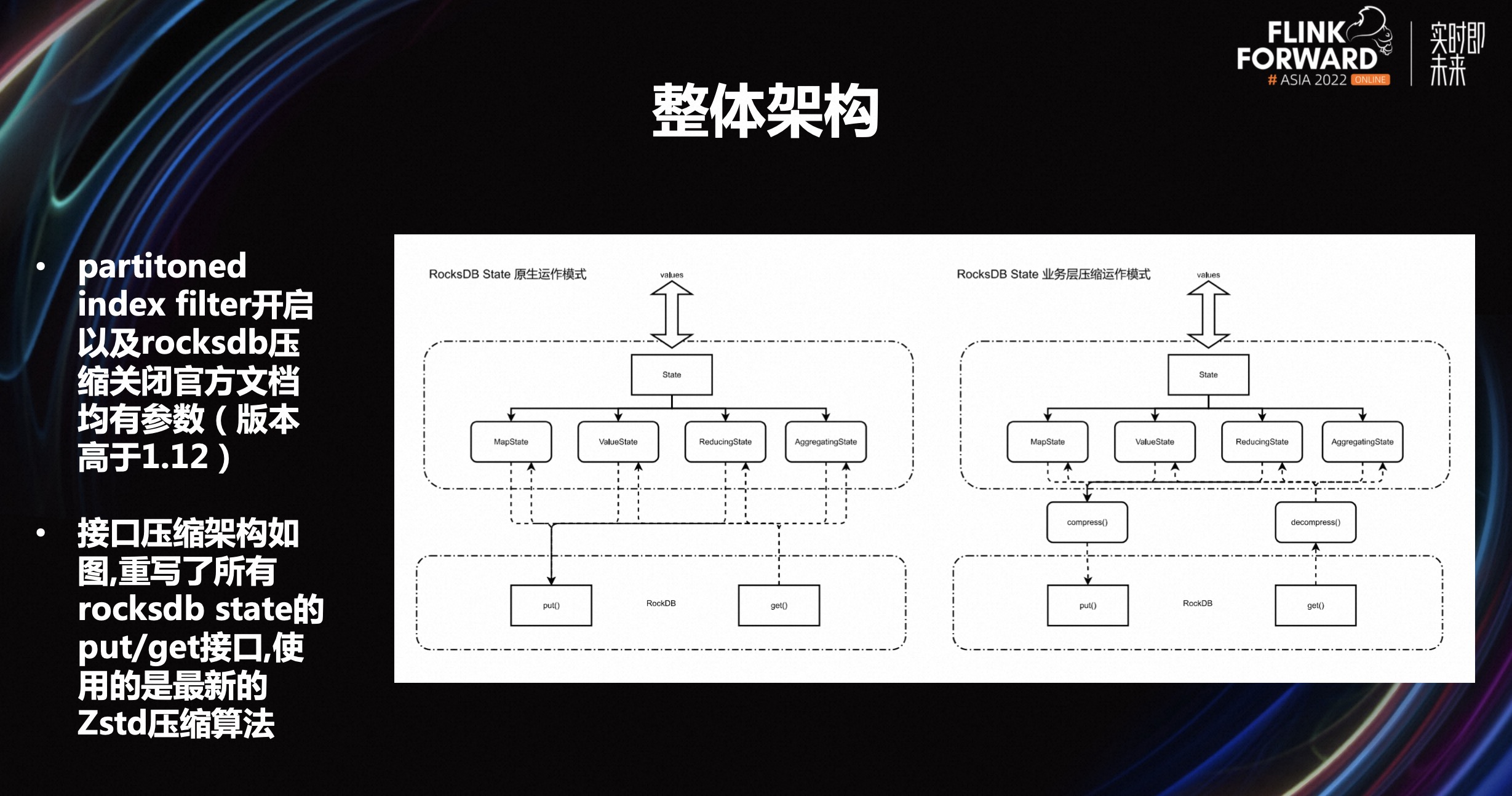
partitoned index filter 开启,B 站内部目前主要用的是 Flink 1.11 版本。当初我们大概调研到这个参数的时候,发现社区本身在 1.12 版本已经提升了这个功能,所以就直接把 1.12 版本相关的功能直接用过来了,同时 rocksdb 压缩关闭,官方文档均有参数,这个部分成本比较低。
第二个部分是支持业务的压缩。为了减少磁盘 io 的压力,在接口上做了一些压缩。接口压缩架构,如上图,重写了所有 rocksdb state 的 put/get 接口,使用的是最新的 Zstd 压缩算法。目前使用的是 LTZ 算法,比一些常用的压缩收益更高,cpu 的消耗比较小。
2.4 业务效果
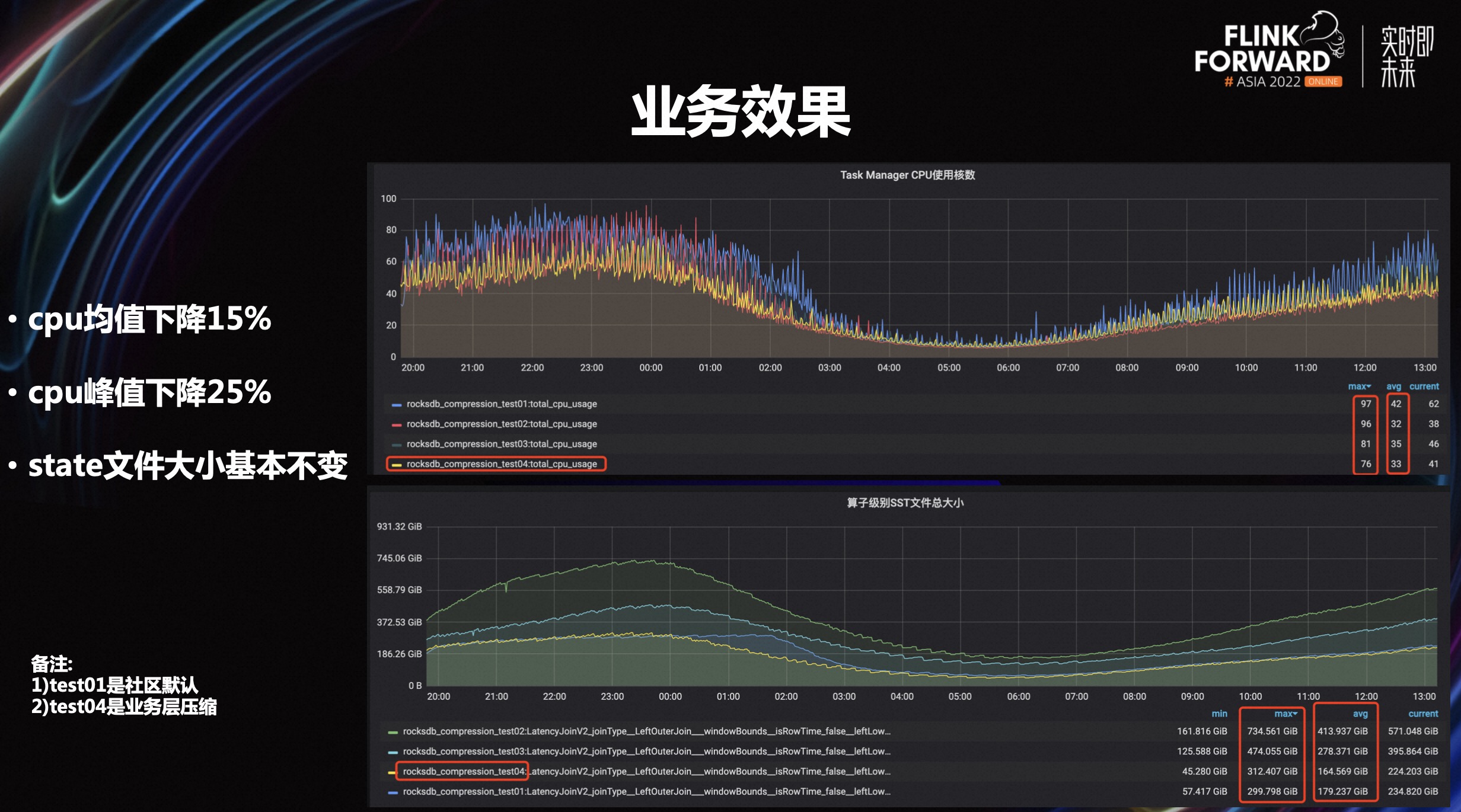
如上业务效果对比图,这里面包含 test 1、2、3、4,主要看看 test 0 和 test 4。test 0 是社区默认的方案,也就是底层用是 snappy 压缩,上层不做什么。test 4 是完全关闭了底层的压缩,无论是上层还是底层,整个压缩是全部关闭的,在业务层使用了最新的 STD 方法进行压缩。
整个观察下来,峰值和低峰期的数据都进行了查看,cpu 均值大概是下降到 15%左右,峰值大概下降到 25%,相信对毛刺的下降会更明显一些。另外,在业务层做完压缩之后,这个文件大小基本保持不变,或是只提升了一点点。这样一来,最底层的存储空间或者 io 其实完全没有增加任何压力。
目前来讲,线上所有新增的大的任务基本都已经全部开启了,老的任务也在进行一些推进。

最后补充下这个场景的适应性。因为整个方案是匹配到我们的推荐功能或是广告模型拼接场景来做的,所有的性能分析也是在这样的场景下进行的,结论是主要双流 join 的大 state 场景,小 state 场景下基本没有收益,主要原因是小 state 的模式下,cache 本身的命中率非常高,换进换出频率较低。另外,Liststate 暂时不支持业务层压缩,add 接口底层的特殊 merge 实现暂时无法做业务层压缩。
三、Remote state 探索
3.1 业务场景和问题
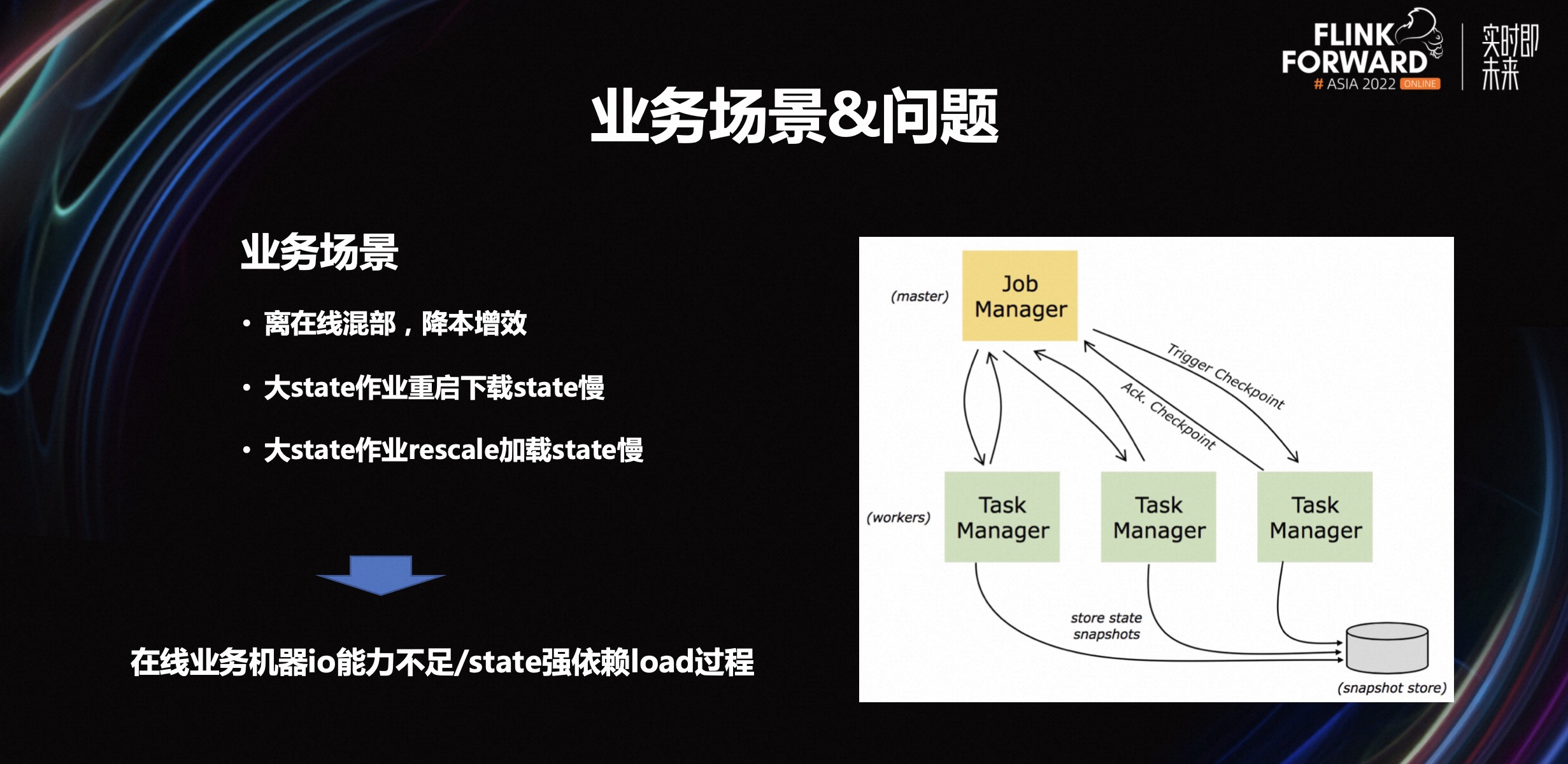
第一,降本增效。这是今年大部分互联网公司可能都在做的事情,B 站也不列外。我们在推一个离在线混部,主要是为了提升资源的使用效率。把 Flink 大数据的场景和在线服务的场景进行资源的混部。
第二,大 state 作业重启下载 state 慢。有些用户反应,对一些重启时间比较敏感的业务方,会觉得大状态下的重启对业务会有一些抖动,尤其在广告、AI 模型推荐等方面体验感不好。
第三,大 state 作业重启加载 state 慢。希望在重启或是扩容的时候,加载更快一些。这里包括两个业务场景,一个是离在线混部,第二个是用户的重启体验。这两个方面即使是用 rocksdb 来做都比较难。例如在线混部,因为在线的机器的磁盘基本是 100-200GB 的那种本地较小的磁板,同时 io 性能也不是很高,在这种情况下,将Flink大任务丢到在线混部上去,会对在线的机器负载压力比较大。这就造成在线混部上的任务是相对有限的。
其实用户很难区分到底哪些任务是可以丢到在线混部,哪些不能。这需要用户通过 state 来判断。另外, state 的慢导致用户体验比较差,主要是因为它重启的时候强依赖 load 过程,尤其是当遇到超过 500GB 的任务时候,这个体验感就会比较差。
3.2 优化思路

首先是实现 Flink state 的存算分离。如果进行混部,本地实际上没有磁盘,就很难给到在线的机器,在 Flink 上最直接的办法就是存算分离。存算分离不是陌生的概念,尤其是在云上。存储放在存储的机器上,按照存储的需求进行机型采购,计算同理。
其次是 state 远程化/服务化,重启 /rescale 直接建立连接进行读写。B 站的做法是把 Flink 的 state 进行存储的分离,这样就能解决在线的混部问题。分离之后,就可以进行远程化和服务化的部署,最终重启或是其他就能直接与远程服务进行连接。
第三是远程 state 服务需要支持 checkpoint 完整功能依赖的接口。这是正常开发流程中所依赖的,即远程服务。需要支持一个 checkpoint 的完整功能,主要对标的就是 rocksdb 的功能。
3.3 整体架构
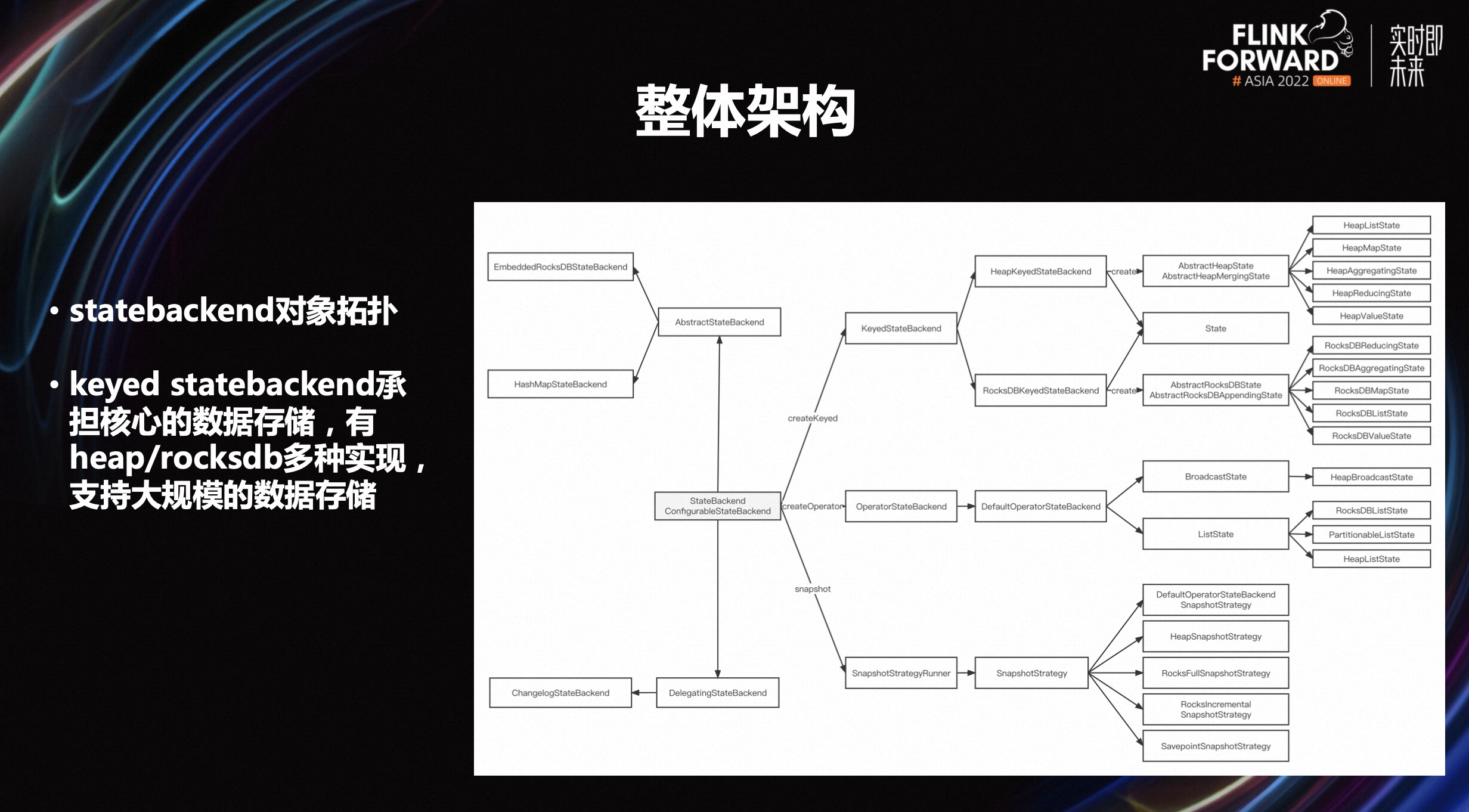
上图是 Flink state 整体的架构,也是 statebackend 对象拓扑,就是上图右侧。另外,Flink statebackend 的核心数据或是数据存储主要是由 keyed statebackend 承担,还有一部分是由 operator state 承担,这部分主要是存在内存里,并全量往远程刷,一般支持的数据不会特别大。
核心的大规模数据会存在 keyed statebackend 里。keyed statebackend 主要有 heap 和 rocksdb 两种实现,支持大规模额数据存储。
B 站主要使用的是 rocksdb 存储,主要围绕的核心是改进 keyed statebackend,因为 operator state 主要针对的是小规模数据,它不会占用本地 io,也不会在重启的时候产生大量的重复操作,速度相对来说要快很多。

上图是社区 keyed statebackend 的分配逻辑架构。如果想要把 keyed statebackend 做存算分离,需要了解:
-
Flink 的分片逻辑,它的底层有一个 keyed group 的概念。在所有状态在任务第一次启动的时候,底层分片就已经确定好了。这个分片大小就是 Flink 的最大并发度的值。这个最大并发度实际上是在任务第一次不从 checkpoint 启动时候算出来的。这中间如果一直从 checkpoint 启动,那么最大并发度永远不会变。
-
Flink checkpoint rescale 能力是有限的,本质是分片 key-group 在 subtask 之间的移动,分片无法分裂。一旦启动生成切换之后,这个分片的数量因为已经固定好了,后面不管怎么 rescale,本质是分片的移动,其实最大的变动是后面 rescale 不能超过整个分片的数量,这个数量对应的是分片最大的并发度。
-
多个 key-group 存储在相同 rocksdb 的 cf 里面,以 key-group 的 ID 作为 key 的 prefix,依赖 rocksdb 的排序特性,rescale 过程通过 prefix 进行定位遍历提取。
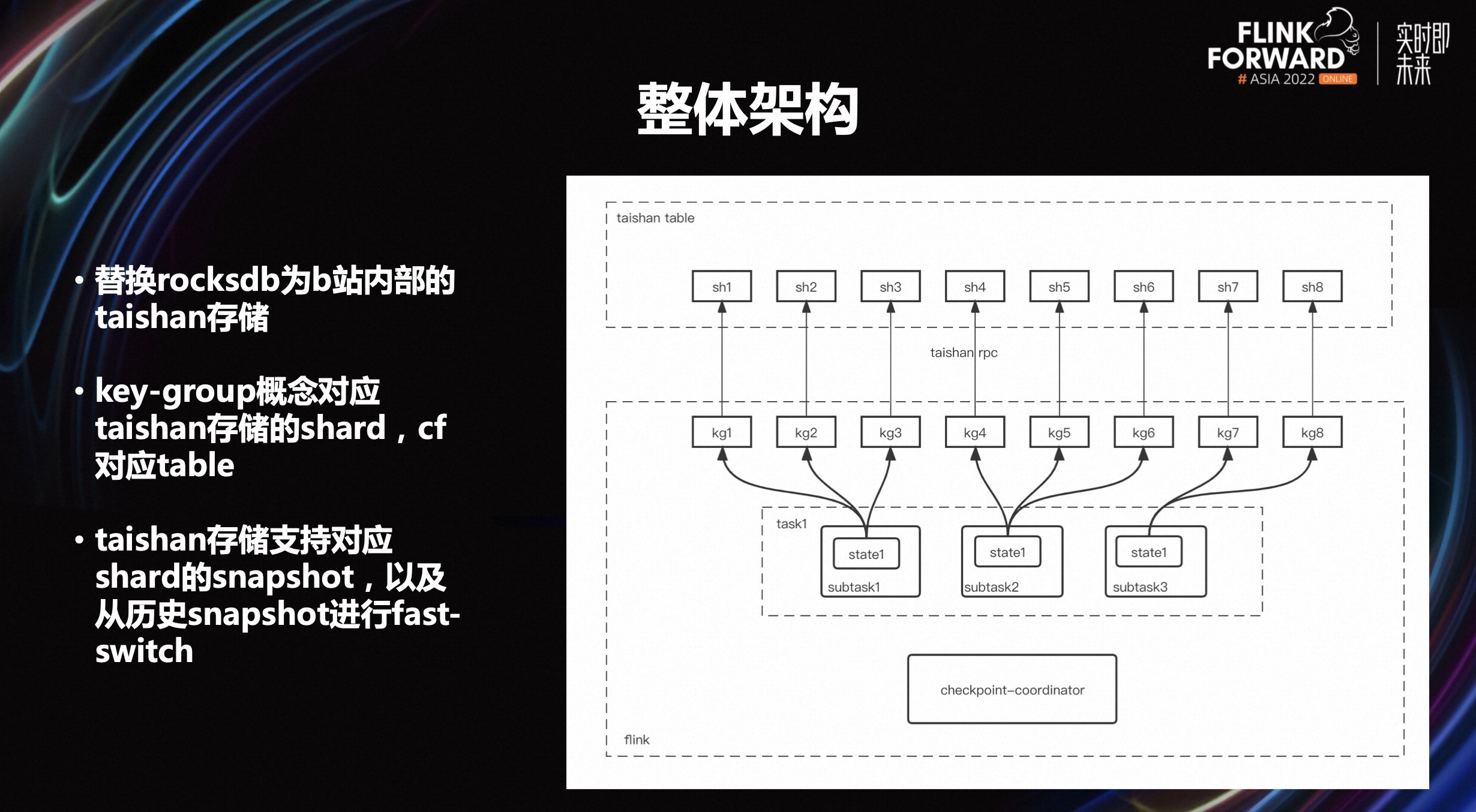
上图是 Remote state 整体架构,主要的核心工作有三点:
-
替换 rocksdb 为 B 站内部的 taishan 存储。Taishan 存储底层是分布式结构,Flink 的一些概念是可以对应到 taishan 存储上的。
-
key-group 概念对应 taishan 存储的 shard,cf 对应 table。key-group 的概念就可以对应上 taishan 存储,同时里面 cf 的概念也对应 taishan 存储中的一个 table 概念,也支持一个 table 里面可以有多个 key-group。
-
Taishan 存储支持对应 shard 的 snapshot,以及从历史的 snapshot 进行快速切换。比如重启的时候可以从老的 checkpoint 进行回复,实际上能够调用 taishan 存储这样一套接口进行快速 snapshot 切换,并可以指定对应的 snapshot 并进行加载,加载的速度非常快,基本是秒级左右。
3.4 缓存架构
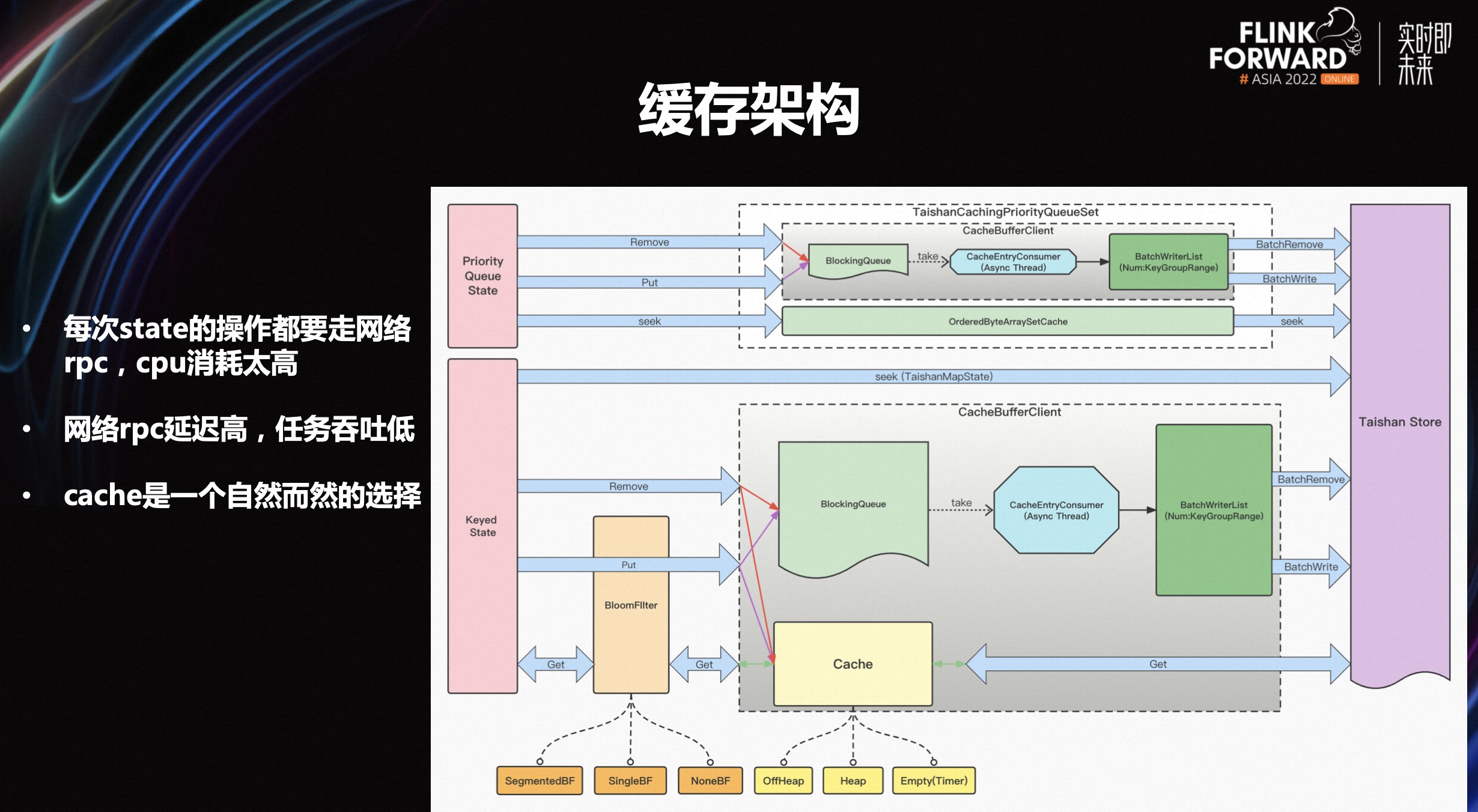
在上文介绍的基础上可以观察到,开发完之后实际上整个功能来说是完全够用的,但也发现了一些比较严重的性能问题:
-
每次 state 操作都需要走网络 rpc, cpu 的消耗太高
-
网络 rpc 的延迟高,任务吞吐低
- cache 是一个自然而然的选择
3.5 缓存难点
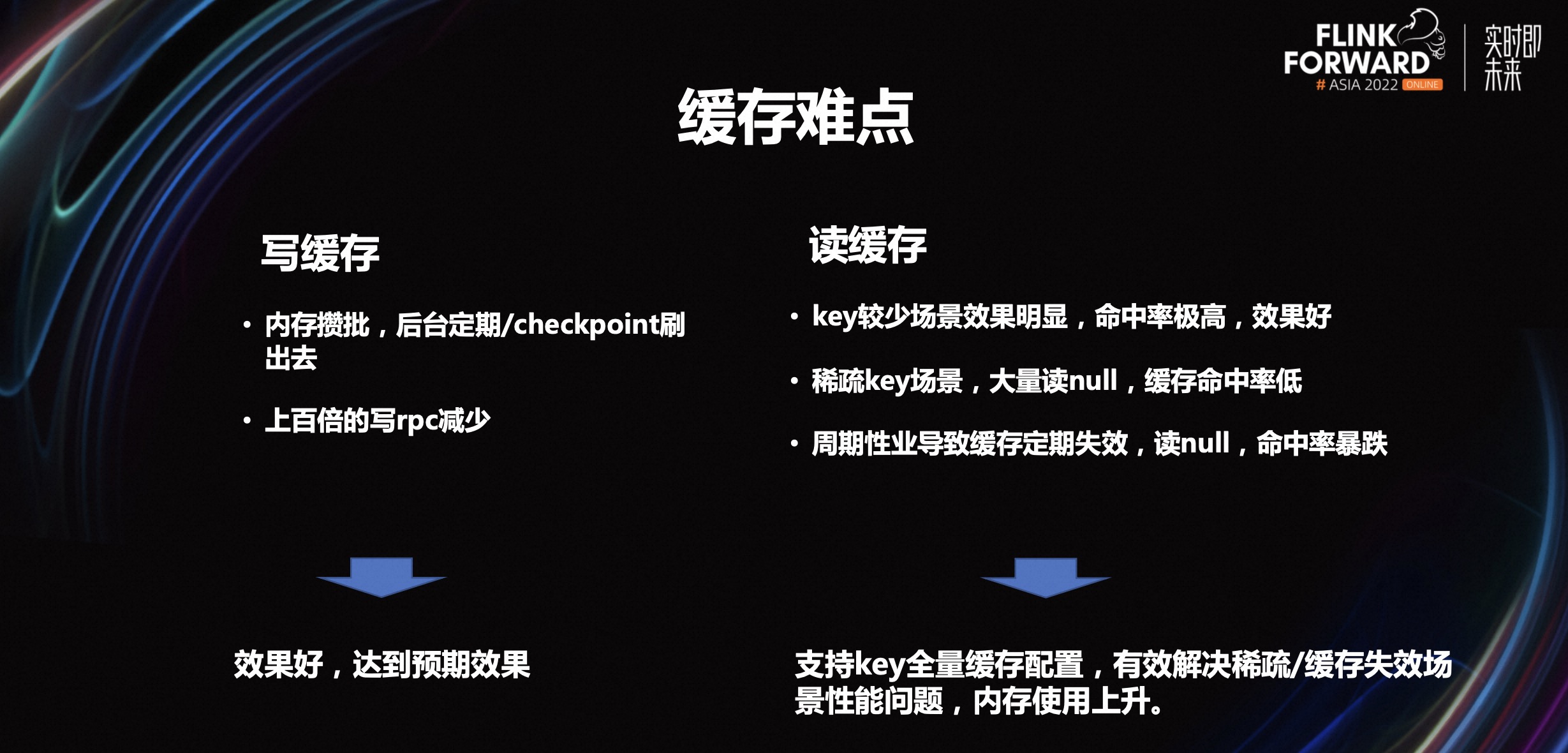
写缓存相对来讲是比较简单,内存攒批,后台定期 checkpoint 刷出去就可以上百倍的减少写的 rpc。
读缓存是比较难的。读缓存是把场景进行拆分来看:
-
key 比较少的场景效果明显,命中率极高,效果好,甚至达到几百上千倍的效果提升。
-
稀疏的 key 场景,大量读 null,缓存命中率低。这个场景是当下比较大的难点。
-
周期性业务导致缓存定期失效,读 null,命中率暴跌。周期性业务到周期末节点,就会触发一个缓存失效,一旦跨过这个节点,缓存里就会变成新的数据。如果正巧遇上读 null,命中率就会很低,甚至导致任务抖动。这也是比较大的难点。
基于以上的问题,优化方案是支持 key 全量缓存配置,有效解决稀疏/缓存失效场景性能问题,使内存使用上升。但是这个优化缺点也比较明显,即对内存的要求会高些。因为所有的 key 都要存在一个缓存里,而这个缓存就是内存。
除了以上介绍的两点难点,其实还有另外两个难点。其一是冷启动,因为缓存不会进行持久化,那么当任务重启等状态下,其实重启之后缓存内是空的,那么也就会造成重启的时候,读和写的请求量都很大,会给性能造成压力。
另外,全量 key 的缓存,启动的时候也没法立即使用,需要等一个ttl周期,这样才能可以保证后面的全量 key 缓存是真正的全量 key。
3.6 off-heap 缓存模型图
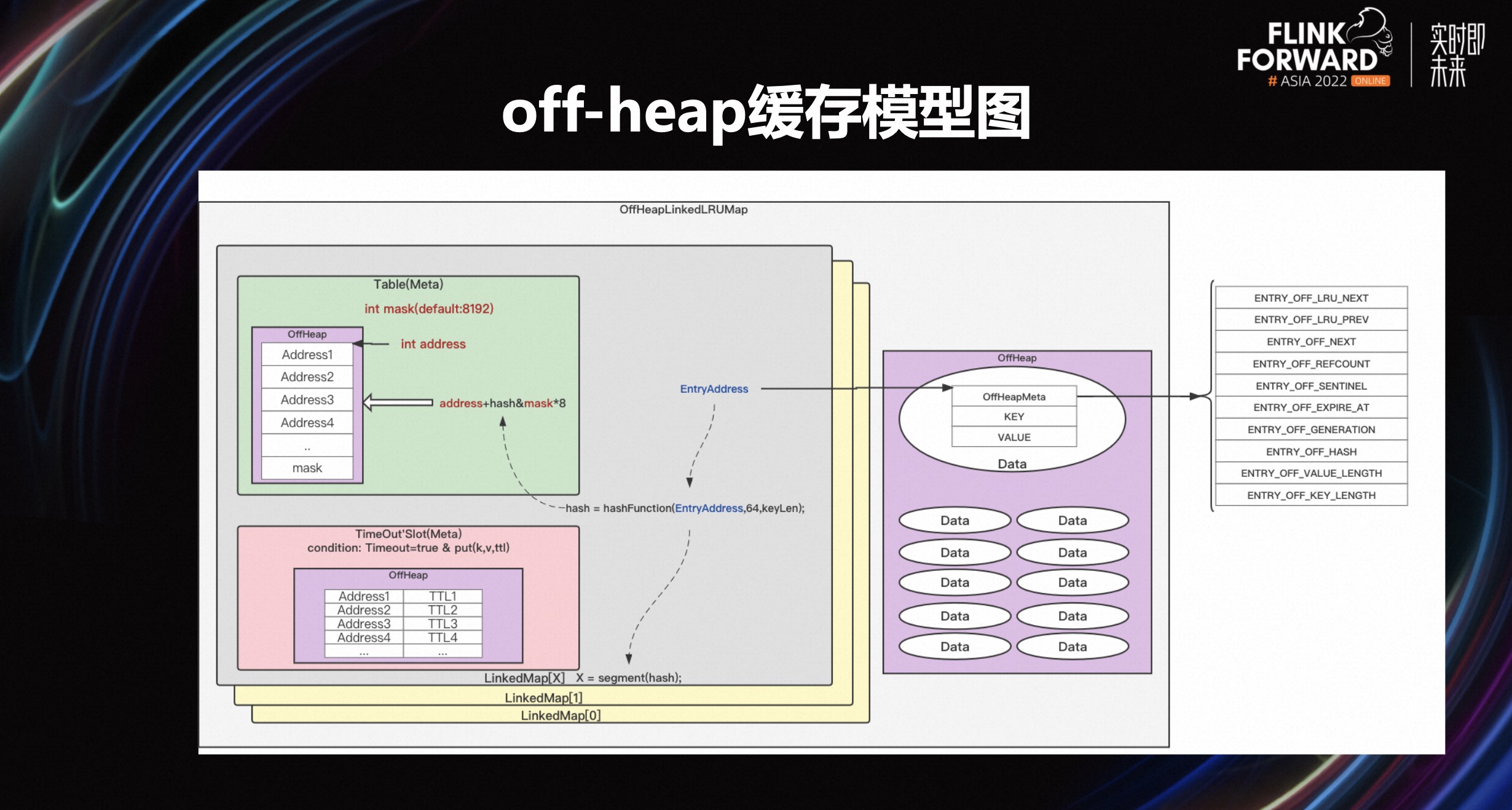
上图是 off-heap 缓存模型,我们使用的是 Facebook 的 OHC(off-heap cache)。可以观察到,基于 ttl 的主动淘汰,它带来的性能消耗相对来讲会比较大。但是如果完全关掉基于ttl的淘汰机制,在某些特殊场景,基于 io 淘汰机制,也会消耗比较大的空间。因为 io 淘汰的时候会进行判断哪个 key 可以真的被淘汰。如果完全通过 io 淘汰,在有些场景下面可能判定了很多 key,这些 key 都无法满足一个 io 的淘汰条件,那么这个淘汰流程就会很长,会导致接口卡的时间会比较久。所以在这里 B 站进行了调优,既保留了一个主动淘汰的思路,也依赖 io 这样一个淘汰机制。
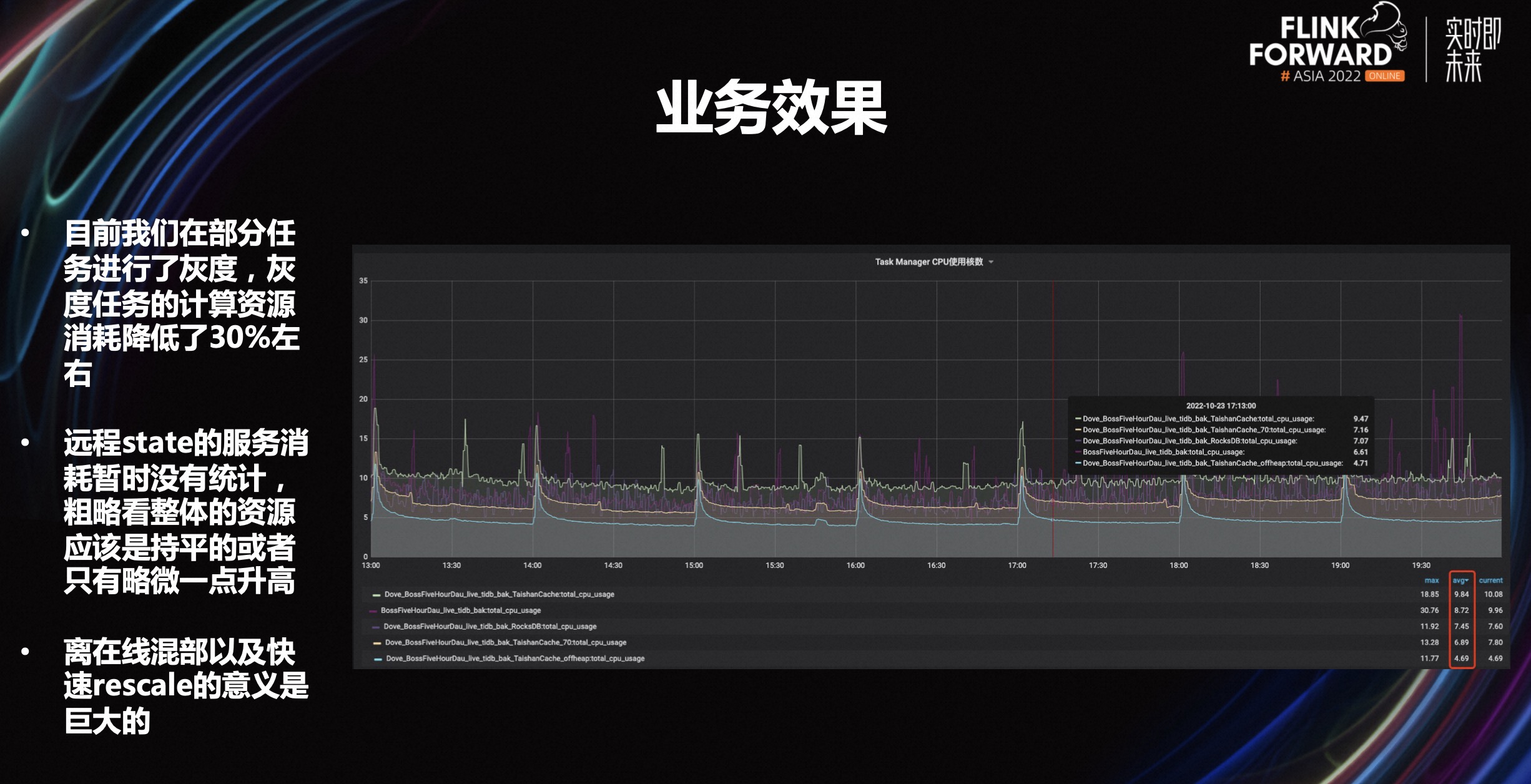
目前来讲,我们已经完成针对部分任务的灰度,灰度任务的计算资源消耗降低了 30%左右。远程 state 的服务消耗暂时没有统计,粗略看整体的资源应该是持平或是只有略微一点升高。离在线混部以及快速 rescale 的意义是巨大的。Flink 侧可以实现存算分离的效果,同时,这也能够做快速的重启而不需要进行状态的重新下载、重新加载或是 reload 的过程。
四、未来规划
