U-net: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
- 语义分割面临的挑战
- 1. DeepLab v1——《Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs》(ICLR 2015,谷歌)
- 2. DeepLab v2——《DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs》(TPAMI 2017,谷歌)
- 3. DeepLab v3 ——《Rethinking Atrous Convolution for Semantic Image Segmentation》(谷歌)
- 4. DeepLab v3+ ——《Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation》(ECCV 2018, 谷歌)
- 5. 论文总结
语义分割面临的挑战
- 分辨率
- 问题:连续的池化或下采样操作会导致图像的分辨率大幅度下降,从而损失了原始信息,且在上采样过程中难以恢复
- 减少分辨率的损失的方法:
- 空洞卷积
- 用步长为2的卷积操作代替池化
- 多尺度特征
- 将不同尺度的特征图送入网络做融合,对于整个网络性能的提升很大
- 但是由于图像金字塔的多尺度输入,造成计算时保存了大量的梯度,从而导致对硬件的要求很高
- 将网络进行多尺度训练,在测试阶段进行多尺度融合。如果网络遇到了瓶颈,可以考虑引入多尺度信息,有助于提高网络性能。
1. DeepLab v1——《Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs》(ICLR 2015,谷歌)
-
标题:基于深度卷积网络和全连接CRF的语义图像分割
-
代码: https://bitbucket.org/deeplab/deeplab-public/src/master/(office)
-
研究成果及意义:
- 1.参数同比减少,所以占比内存减小,速度快
- 2.ResNet的引入,越深层的网络准确率越高
- 3.连续卷积和池化不可避免的会带来分辨率降低, 然而空洞卷积却可以在尽可能保证分辨率的情况下扩大视野
- 4.ASPP的创举
-
摘要:
- 背景概述:DCNNs的最后一层不足以进行精确分割目标
- 主要贡献:本文将深度卷积神经网络和CRF相结合,克服了深度网络的局部化特性
- 网络效果:DeepLab v1超过了以往方法的精度水平,可以更好地定位分割边界
- 实验结果:在PASCAL VOC 2012数据集中取得了71.6%的IOU;在正常GPU上可达到每秒8帧的处理速度
-
引言
- DeepLab v1 是结合了深度卷积神经网络(DCNNs)和概率图模型(DenseCRFs)的方法
深度卷积神经网络(DCNNs)- 1.采用FCN思想,修改VGG16网络,得到 coarse score map并插值到原图像大小
- 2.使用Atrous convolution得到更dense且感受野不变的feature map概率图模型(DenseCRFs)
- 3.借用fully connected CRF对从DCNNs得到的分割结果进行细节上的refine。
- DeepLab v1 是结合了深度卷积神经网络(DCNNs)和概率图模型(DenseCRFs)的方法
-
算法&实验
- 1.把全连接层(fc6、fc7、fc8)改成卷积层(端到端训练)
- 2.把最后两个池化层(pool4、pool5)的步长2改成1(保证feature的分辨率)
- 3.把最后三个卷积层(conv5_1、conv5_2、conv5_3)的dilate rate设置为2,且第一个全连接层的dilate rate设置为4(保持感受野)
- 4.把最后一个全连接层fc8的通道数从1000改为21(分类数为21)
- 5.第一个全连接层fc6,通道数从4096变为1024,卷积核大小从7x7变为3x3,后续实验中发现此处的dilate rate为12时(LargeFOV),效果最好

图

图
-
实验设置:
- DeepLab-MSc:类似FCN,加入特征融合
- DeepLab-7×7:替换全连接的卷积核大小为7×7
- DeepLab-4×4:替换全连接的卷积核大小为4×4
- DeepLab-LargeFOV:替换全连接的卷积核大小为3×3,空洞率为12

2. DeepLab v2——《DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs》(TPAMI 2017,谷歌)
- 标题:学习反卷积网络的语义分割
- 论文:https://arxiv.org/pdf/1606.00915v2.pdf(https://arxiv.org/ftp/arxiv/papers/1612/1612.05360.pdf)
- 代码:https://github.com/tensorflow/models/tree/master/research/deeplab
- 摘要:
- 主要贡献:充分利用空洞卷积,可实现在不增加参数量的情况下有效扩大感受域,合并
更多的上下文信息;DCNNs与CRF相结合,进一步优化网络效果;提出了ASPP模块 - 网络效果:ASPP增强了网络在多尺度下多类别分割时的鲁棒性,使用不同的采样比例与感受野提取输入特征,能在多个尺度上捕获目标与上下文信息
- 实验结果:在PASCAL VOC 2012数据集中取得了79.7%的MIOU;在其他数据集中也进行了充分实验
- 主要贡献:充分利用空洞卷积,可实现在不增加参数量的情况下有效扩大感受域,合并
- 引言
- 1.针对分辨率过低的特征图。文章通过修改最后的几个池化操作,避免特征图分辨率损失过大,通过引入空洞卷积,在没有增加参数与计算量的情况下增大了感受野(基本同理于v1)
- 2.需要分割的目标具有多样的尺度大小。针对这个问题,文章参考了空间金字塔池化的思想,这里使用不同比例的膨胀卷积构造“空间金字塔结构”(Atrous Spatial PyramidPooling,ASPP)
- 3.DCNN网络对目标边界的分割准确度不高。文章引入全连接条件随机场(fully-connected Conditional Random Field,CRF)使得分割边界的定位更加准确,从而解决该问题
- 先验知识
- 空洞卷积:

- 感受域计算: R F 1 + 1 = R F 1 + ( k e r n e l s i z e − 1 ) × s t r i d e RF_{1+1} = RF_1 + (kernel_size - 1) \times stride RF1+1=RF1+(kernelsize−1)×stride
- 空洞率对应卷积核尺寸: k n e w = k o r i + ( k o r i − 1 ) ( r a t e − 1 ) k_{new} = k_{ori} + (k_{ori} -1)(rate - 1) knew=kori+(kori−1)(rate−1)
- SPPNet(《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》)
- SPPNet提出的初衷是为了解决CNN对输入图片尺寸的限制。由于全连接层的存在,与之相连的最后一个卷积层的输出特征需要固定尺寸,从而要求输入图片尺寸也要固定。SPPNet之前的做法是将图片裁剪或变形(crop/warp)。但是crop/warp的一个问题是导致图片的信息缺失或变形,影响识别精度。


- SPPNet提出的初衷是为了解决CNN对输入图片尺寸的限制。由于全连接层的存在,与之相连的最后一个卷积层的输出特征需要固定尺寸,从而要求输入图片尺寸也要固定。SPPNet之前的做法是将图片裁剪或变形(crop/warp)。但是crop/warp的一个问题是导致图片的信息缺失或变形,影响识别精度。
- bottom-up&top-down
- top-down:在模式识别的过程中使用了上下文信息(举例:当你看到了一张字迹潦草难以辨认的手写文本时,你可以利用整个文本来辅助你理解其中含义,而不是每个字单独辨认。正因为有了周围字体的上下文信息,大脑可以去感知和理解文本里的意思。)
- bottom-up:以数据为主要驱动(举例:一个人在花园看到一朵花,有关于花朵的所有视觉信息都从视网膜上通过视神经传递到大脑,大脑分析后得到图像从而判断出这是一朵花。这些信息的传递都是单方向的) - ResNet
- 变化率:残差的引入去掉了主体部分,从而突出了微小的变化
- 主要思想:用一个神经网络去拟合y=x这样的恒等映射,比用一个神经网络去拟合y=0这样的0映射要难。因为拟合y=0的时候,只需要将权重和偏置都逼近0就可以了
- 空洞卷积:
- 算法&实验
- Network&ASPP


- Network&ASPP
- 实验设置
- 损失函数:交叉熵+softmax
- 优化器:SGD + momentum 0.9
- batchsize:20
- 学习率:10-3(每2000次,学习率 * 0.1)

- 实验分析
- LargeFOV:3×3卷积 + rate=12(DeepLab v1最好结果)
- ASPP-S:r = 2, 4, 8, 12
- ASPP-L:r = 6, 12, 18, 24





3. DeepLab v3 ——《Rethinking Atrous Convolution for Semantic Image Segmentation》(谷歌)
- 标题:学习反卷积网络的语义分割
- 论文:https://arxiv.org/pdf/1706.05587v3.pdf
- 代码:https://github.com/tensorflow/models/tree/master/research/deeplab
- 摘要:
- 主要贡献:为了解决多尺度下的分割问题,本文设计了级联或并行的空洞卷积模
块;扩充了ASPP模块 - 网络效果:网络没有经过DenseCRF后处理,也可得到不错的结果
- 实验结果:在PASCAL VOC 2012数据集中获得了与其他最新模型相当的性能
- 主要贡献:为了解决多尺度下的分割问题,本文设计了级联或并行的空洞卷积模
- 本文贡献
- 1.本文重新讨论了空洞卷积的使用,这让我们在串行模块和空间金字塔池化的框架下,能够获取更大的感受野从而获取多尺度信息
- 2.改进了ASPP模块:由不同采样率的空洞卷积和BN层组成,我们尝试以串行或并行的方式布局模块
- 3.讨论了一个重要问题:使用大采样率的3×3的空洞卷积,因为图像边界响应无法捕捉远距离信息(小目标),会退化为1×1的卷积, 我们建议将图像级特征融合到ASPP模块中
- 先验知识
- 语义分割常用特征提取框架

- 语义分割常用特征提取框架
- 算法&实验

- 实验设置
- 深度学习框架:TensorFlow
- 裁剪尺寸:裁剪图片至513*513
- 学习率策略:采用poly策略,原理同v2
- BN层策略:
- 当output_stride=16时,batchsize=16,同时BN层做参数衰减0.9997
- 在增强的数据集上,以初始学习率0.007训练30K后,冻结BN层参数
- 当output_stride=8时,batchsize=8,使用初始学习率0.001训练30K
4. DeepLab v3+ ——《Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation》(ECCV 2018, 谷歌)
- 标题:学习反卷积网络的语义分割
- 论文:https://arxiv.org/pdf/1802.02611v3.pdf
- 代码:
- https://github.com/tensorflow/models(office,Tensorflow)
- https://github.com/open-mmlab/mmsegmentation(PyTorch)
- 摘要:
- 背景概述:深度神经网络通常采用ASPP模块或编解码结构进行语义分割
- 主要贡献:通过添加一个简单而有效的解码器模块开扩展DeepLab v3以优化分割结果
- 网络效果:该网络超过了以往方法的精度水平,可以更好地定位分割边界
- 实验结果:在PASCAL VOC 2012数据集和Cityscapes数据集中分别取得了89%和82.1%的MIOU
- 本文贡献:
- 1.提出了一种编码器-解码器结构,采用DeepLab v3作为encoder,添加decoder得到新的模型(DeepLabv3+)
- 2.将Xception模型应用于分割任务,模型中广泛使用深度可分离卷积
- 先验知识
- 深度可分离卷积(Depthwise separable convolution)(CSDN:深度可分离卷积)
- 输入图片尺寸为12×12×3,用1个5×5×3的卷积核进行卷积操作,会得到8×8×1的输出;用256个5×5×3的卷积核进行卷积操作,会得到8×8×256的输出
- 参数计算:256×5×5×3 = 19200


- 深度可分离卷积 = 深度卷积 + 逐点卷积
- 深度卷积:每个5×5×1的卷积核对应输入图像中的一个通道,得到三个8×8×1的输出,拼接后得到8×8×3的结果
- 逐点卷积:设置256个1×1×3的卷积核,对深度卷积的输出再进行卷积操作,最终得到8×8×256的输出
- 参数计算:
- 深度卷积参数 = 5×5×3 = 75
- 逐点卷积参数 = 256×1×1×3 = 768
- 总参数 = 75 + 768 = 843 << 19200


- 深度可分离卷积(Depthwise separable convolution)(CSDN:深度可分离卷积)
- 算法&实验
- 编码器:
- 1.使用DeepLab v3作为编码器结构,输出与输入尺寸之比为16(output_stride = 16)
- 2.A S P P:一个1×1卷积 + 三个3×3卷积(rate = {6, 12, 18}) + 全局平均池化
- 解码器:
- 1.先把encoder的结果上采样4倍,然后与编码器中相对应尺寸的特征图进行拼接融合,再进行3x3的卷积,最后上采样4倍得到最终结果
- 2.融合低层次信息前,先进行1x1的卷积,目的是降低通道数

- DeepLab v3+对Xception进行了微调:
- 1.更深的Xception结构,原始middle flow迭代8次,微调后迭代16次
- 2.所有max pooling结构被stride=2的深度可分离卷积替代
- 3.每个3x3的depthwise convolution后都跟BN和Relu

- 编码器:
- 实验设置
- 深度学习框架:TensorFlow
- 裁剪尺寸:裁剪图片至513*513
- 学习率策略:采用poly策略,原理同v2 v3
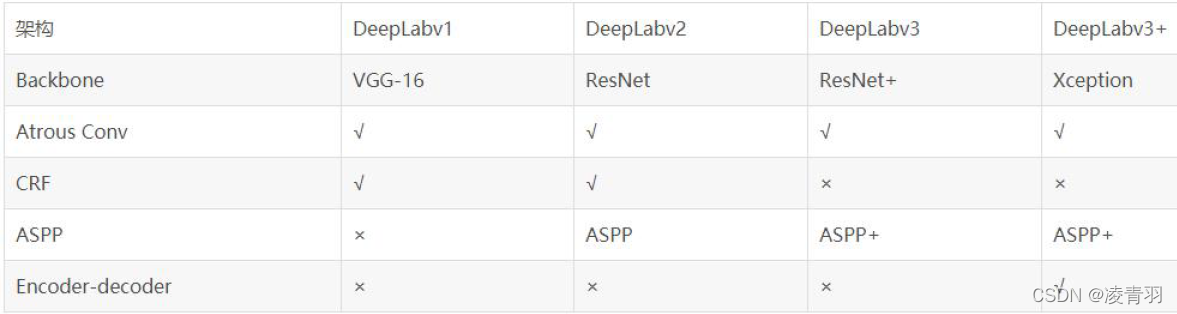
5. 论文总结
- DeepLab系列发展历程:
- v1:修改经典分类网络(VGG16),将空洞卷积应用于模型中,试图解决分辨率过低及提取多尺度特征问题,用CRF做后处理
- v2:设计ASPP模块,将空洞卷积的性能发挥到最大,沿用VGG16作为主网络,尝试使用ResNet-101进行对比实验,用CRF做后处理
- v3:以ResNet为主网络,设计了一种串行和一种并行的DCNN网络,微调ASPP模块,取消CRF做后处理
- v3+:以ResNet或Xception为主网络,结合编解码结构设计了一种新的算法模型,以v3作为编码器结构,另行设计了解码器结构,取消CRF做后处理