MMSE适合处理平稳序列,因为MMSE是一个均匀加权的最优化问题,也就是说,每一时刻的误差信号对目标函数的贡献权重是相同的,如果对于非平稳的语音信号效果就不太好了。
RLS重新定义了目标函数:

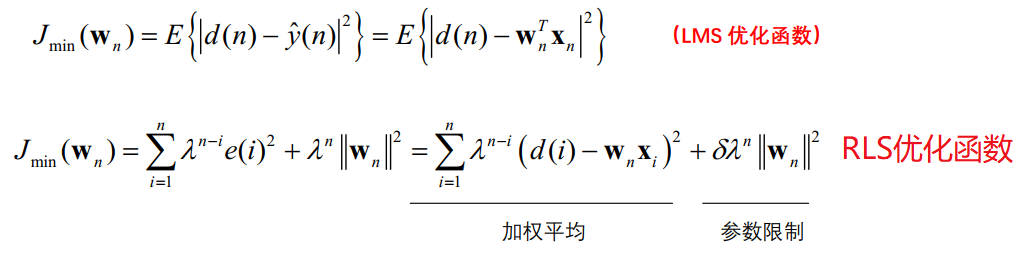
其中,滤波器系数选用的是,而不是
。因为在自适应更新过程中,滤波器总是变得越来越好,这意味着对于任何的i<n,|d(i)−wT(n)x(i)|总是比|d(i)−wT(i)x(i)|小 。
λ称为遗忘因子(0<λ≤1)。对离n时刻越近的误差加比较大的权重,遗忘越少,而对离n时刻越远的误差加比较小的权重,遗忘越多
- λ=1:无任何遗忘功能,此时 RLS 退化为 LMS 方法
- λ−>0:只对当前时刻的误差起作用,而过去时刻的误差完全被遗忘
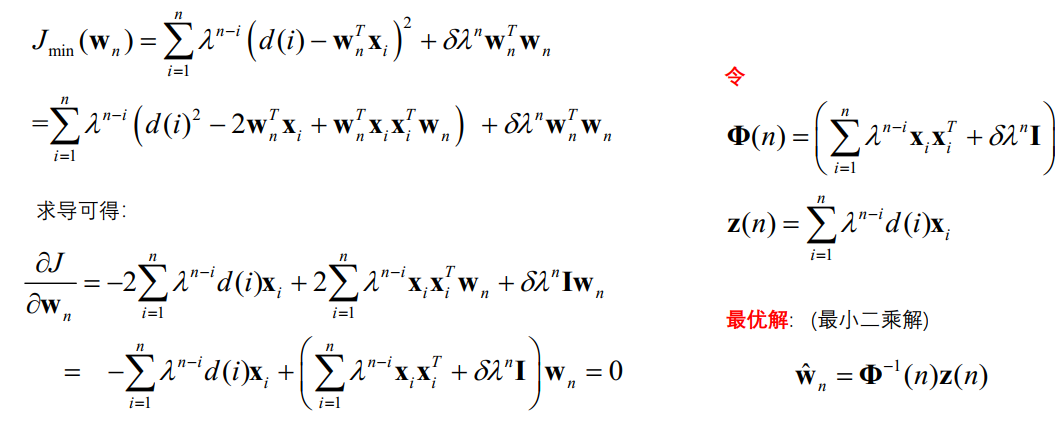
我们让目标函数Jn(w)对w求导,令梯度等于0,得到w的公式为:
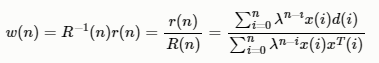
根据R(n)和r(n)的等式,得其时间递推公式:
扫描二维码关注公众号,回复:
15457265 查看本文章

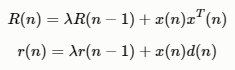
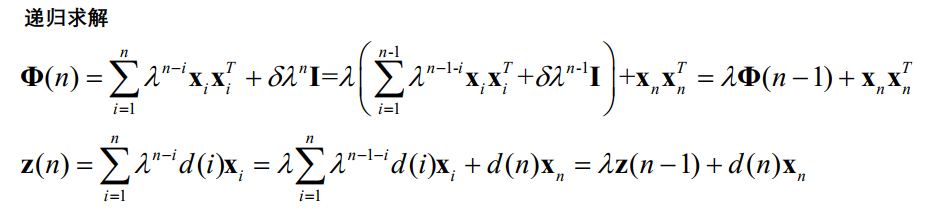
弊端:需要计算R(n)每个点的逆矩阵,很不划算。更优的方法?
令P(n)=R−1(n),P(n)的时间递推公式为:
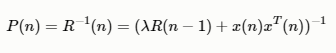
根据矩阵求逆引理:
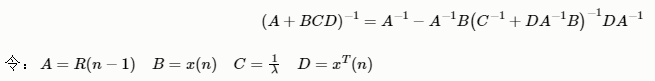
可以得到:
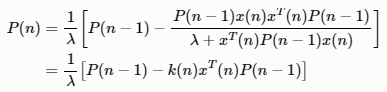
其中,增益向量:
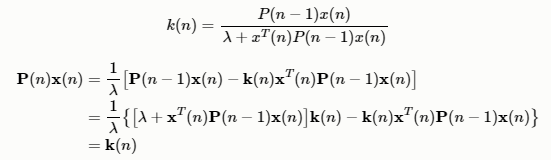
探索w(n)的时间递推公式
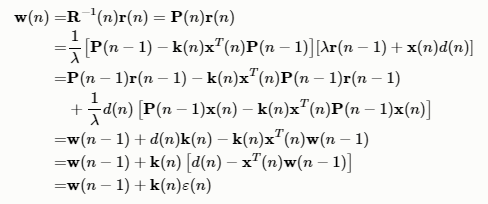
这就是标准RLS算法的更新公式,这里的ε(n)为先验估计误差。

一个广泛的共识是RLS 算法的收敛速度和跟踪性能都优于 LMS 算法,所付出的代价是需要更复杂的计算 。
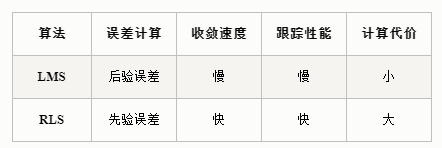
- 优点:RLS自适应滤波器提供更快的收敛速度和跟踪性能。
- 缺点:由于RLS 使用了自相关矩阵的逆矩阵的递推,所以,一旦输入信号的自相关矩阵接近奇异时RLS 的收敛速度和跟踪性能会严重恶化 。
MATLAB代码如下:
function [e, y, w] = myRLS(d, x, lamda, M)
% Inputs:
% d - 麦克风语音
% x - 远端语音
% lamda - the weight parameter, 权重
% M - the number of taps. 滤波器阶数
%
% Outputs:
% e - 大小为Ns的输出误差向量
% y - 输出的近端语音
% w - 滤波器参数
Ns = length(d);
if (Ns <= M)
print('error: 信号长度小于滤波器阶数!');
return;
end
if (Ns ~= length(x))
print('error: 输入信号和参考信号长度不同!');
return;
end
I = eye(M);
a = 0.01;
p = a * I;
xx = zeros(M,1);
w1 = zeros(M,1); % 滤波器权重
y = zeros(Ns, 1); % 近端语音
e = zeros(Ns, 1); % 误差
for n = 1:Ns
%在输入信号x后补上M-1个0,使输出y与输入具有相同长度
xx = [x(n); xx(1:M-1)];
k = (p * xx) ./ (lamda + xx' * p * xx);
y(n) = xx'*w1;
e(n) = d(n) - y(n);
w1 = w1 + k * e(n);
p = (p - k * xx' * p) ./ lamda;
w(:,n) = w1;
end
end
参考链接: