
对话系统是经典的NLP的落地应用场景,近年来非常的火热!像ChatGPT这种NLP的经典应用也是全球范围内的流行,大家真真切切的感受到了AI的能力和魅力。那么随之而来的就是NLP迅速发展,相关岗位需求也出现了很大增长。无论如何,每一位从事NLP相关工作的算法工程师、数据工程师、程序猿们都可以了解一下对话系统这个典型应用。这样有助于你的职业发展和技术实力的提升。笔者希望通过讲解对话系统的核心理论和一个完整的订餐机器人实战项目(代码实现),来帮助大家更好地理解和掌握NLP技术的核心理论和实际应用,同时也希望对大家实践能力和技术水平的提高有所帮助。
一、场景介绍
我们先来介绍一下订餐机器人项目主要应用场景,对话流程树和具体应用界面如下图:
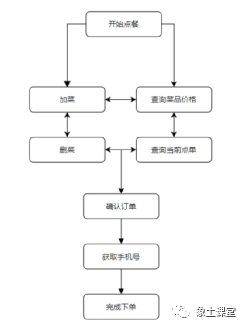
上图描述的场景主要是:用户可通过与点餐机器人对话完成点餐下单操作。比如:购买菜品、查询已经点单的菜品、删除菜品、确认订单,最后输入手机号确认点单的结果,最终完成下单。
此场景基本上涵盖了对话系统的意图识别、槽位抽取和填充、状态跟踪、对话策略、数据库操作、文本生成几大核心部分。当然这个对话系统只是用于最小化的展示,用于让大家理解核心的框架实现,后续可以依据自己的实际场景进行交互上的、产品上的重新设计和复用。
二、意图识别
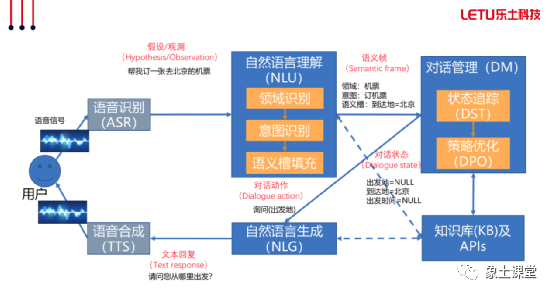
有了场景上的概念以后,我们来依次给大家讲解一下各个部分的核心理论。首先要讲到的就是自然语言理解(NLU)的意图识别部分,也就是说我们首先要知道对方说了什么,我们才能有后续的操作。请先阅读以下两张PPT。
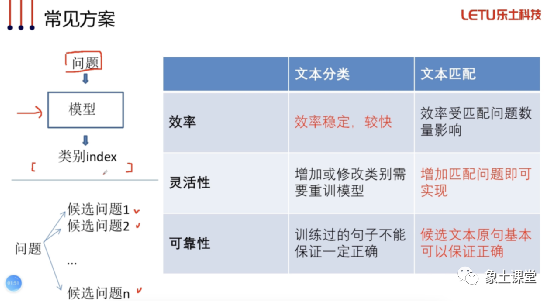
意图识别一般情况下有两种方案:一种是采用文本分类方式,另一种是采用文本匹配的方式去处理。文本分类主要采用分类模型的方式去实现,需要预先规定好类别,并且针对每一个类别去做相应的训练数据。而文本匹配主要采用预先设置一系列的候选问题,然后我们用问题通过文本匹配算法去匹配候选问题,然后打分,分值最高的则命中。
文本分类的方式优势是效率比较稳定,速度较快。文本匹配则在增加新匹配问题和回答正确性上有一定优势。文本匹配有个缺陷,就是效率受匹配问题数量的影响。一般情况下我们从成本、灵活性和正确性的角度考虑,倾向于采用文本匹配的方案。当然在意图比较固定的情况下,也有可能考虑文本分类的方案。
文本匹配的运行逻辑主要是:首先对用户问题进行预处理,比如:分词、去掉停用词,去标点、大小写转换、词性标注等。预处理完以后就要和FAQ库中的问题进行相似度计算,然后得出答案。
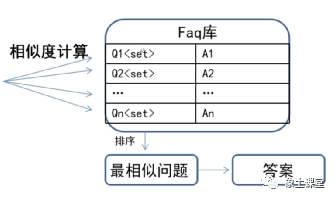
那么标准的FAQ库主要是什么呢?它主要有一系列由序号、问题、答案、相似问题组成的记录集合。

几种常见文本匹配算法:编辑距离、Jaccard、BM25、word2vec、深度学习等。
编辑距离
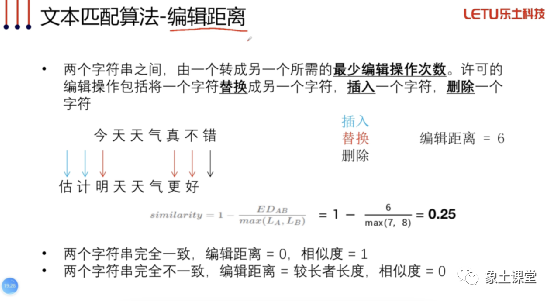
优点:可解释性强、跨语种有效、不需要训练模型。
缺点:字符之间没有语义相似度、受无关词/停用词影响大、受语序影响大、文本长度对速度影响大。
Jaccard距离

优点:语序不影响分数(词袋模型)、实现简单、速度快。可跨语种,无需训练等。
缺点:语序不影响分数(双刃剑)、字词之间没有相似度衡量、受无关词影响、非一致文本可能出现满分。
word2vec
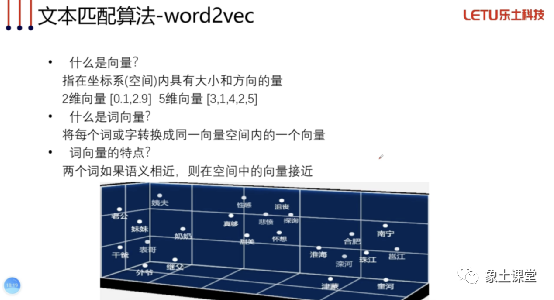
优点:
两个文本包含语义相似的词,会提高相似度;
训练需要的数据简单(纯文本预料即可);
计算速度快,可以对知识库问题预先计算向量;
将文本转化为数字,使后续复杂模型成为可能。
缺点:
词向量的效果决定句向量效果;
一词多义的情况难以处理;
受停用词和文本长度影响很大(也是词袋模型);
更换语种,甚至更换领域,都需要重新训练。
关于上述算法以及BM25和深度学习的深入解析和探讨,会在我们的课程中有详细的讲解。
三、信息抽取
要实现一个对话系统中的第一步就是自然语言理解(NLU),这就包含了意图识别和信息抽取两部分。我们上面讲完了意图识别,也就是让机器理解用户说了什么,解用户的意图。同时我们介绍了几种用于信息抽取常用方法。信息抽取是要完成对话系统中一个必要环节,下面我们来大家介绍几种信息抽取的方案。
基于规则的抽取
通常我们使用正则表达式来匹配特定的句式、词表。原则上规则能处理好的情况下,尽量不使用模型,因为这样更加可控,效率也更高。使用规则的方式同样可以计算准确率和召回率。另外需要注意的是规则的顺序有时候会影响到结果,调试的时候需要注意。
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
lre.search(pattern, string)
lre.match(pattern, string)
lre.findall(pattern, string)
lre.sub(pattern, repl, string)
lre.split(pattern, string)
基于深度学习模型
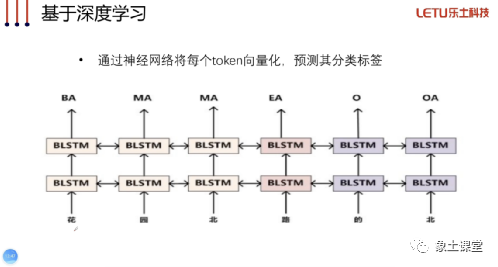
基于神经网络对每一个字预测分类标签并且结合CRF等方法进行命名实体识别,完成信息的抽取是当前常见的做法。关于序列标注模型的搭建,CRF的原理以及与神经网络的结合,维特比解码等内容都会在我们的课程中会有详细讲解。
四、对话状态控制
我们已经讲完了如何识别用户意图(意图识别)和如何抽取用户提供的关键信息(信息抽取)的方法,下面我们来讲一讲对话状态控制。这块包含两部分:一部分是对话策略与流程控制另一部就是数据库控制。
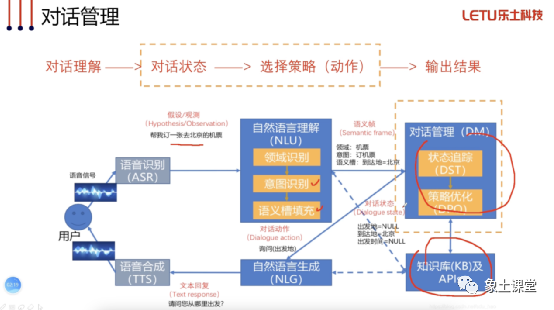
我们来一起回顾一下对话过程。首先用户输入语音或者文字,比如:用户说帮我订一张到北京的机票。那么下一步我们开始做意图识别和语义槽的填充,比如:领域是机票、意图是订机票、语义槽到达地是北京。完成这些步骤以后我们下一步就要进行对话管理,进一步填充完语义槽,达成用户目标。那我们这一节就来讲讲这块的具体实现。
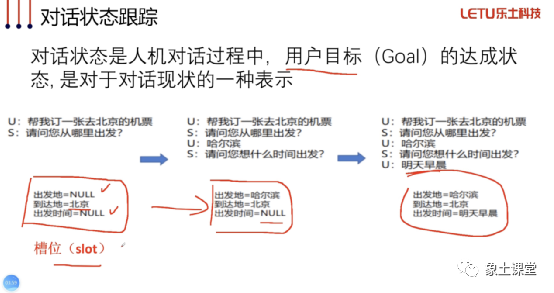
首先我们要讲一下对话状态跟踪,实际上就是我们要完成订机票这个用户目标,有些必要的信息就一定要提供,这些必要信息就是槽位(slot)。这些槽位对于对话系统十分重要,因为槽位内部的信息实际上相当于对话系统对当前对话的记忆,在多轮交互的过程中,这些槽位被不断传递下去,其实相当于在传递记忆,完成槽位的填充这个过程就是对话状态的跟踪。
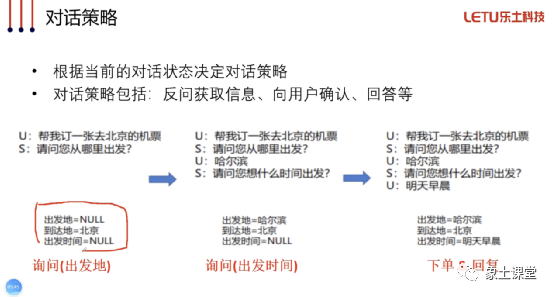
然后对话策略我们也要理解。它是什么呢?就是我们根据对话状态,依据槽位填充的进展,我们让机器人下一步干嘛?叫对话策略。比如系统应该根据情况来判断当前应该向用户提问来收集信息,还是已经可以直接回答用户的问题,又或者应该查询一下数据库。有了对话策略的概念以后,我们讲一下对话流程树。
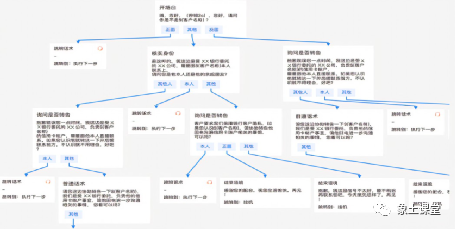
我们在实际工作场景中实现对话策略一般都会构建一个对话流程树。这个流程树体现我们对机器人的所有预期。简单来说就是根据用户表达的意图,机器人如何反馈,在流程树中体现包括如何回答、需要填充那些槽位、如何反馈澄清话术等。我们一般会用一个自定义文件(Json、XML等)记录下来,以便让程序中依据这个流程树去处理用户的各种意图,跳转各个处理节点。
数据库控制用在哪里呢?就是机器人在与人交互的过程中,经常需要同时与数据库进行交互,因为业务场景需要的很多信息(如:商品价格信息)都存储在数据库或者内存中,比如:Redis、MongoDB、MySQL等等。
五、文本生成
我们已经介绍了自然语言理解部分(NLU)和对话管理部分(DM)的知识,那么我们讲一下如何生成文本与用户进行交互。也就是自然语言文本生成(NLG)。文本生成一般采用基于模版填槽的方式。
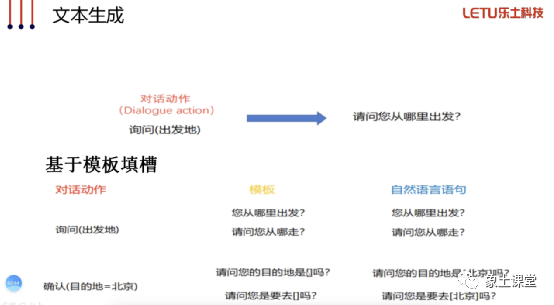
基于模版实现比较简单,也可以将槽位信息作为模版内容输出,但也有它的弊端就是比较千篇一律,好处是输出内容可控,正确性较高。还有一种方式就是基于模型生成的方式,但这种方式对于输出内容比较不可控,如果文本不连贯、输出不符合预期,那么想要快速调整模型到我们预期的效果,很难可控性比较差。关于生成式任务、语言模型及训练、文本生成实现、Encoder-Decoder结构、Attention机制会在课程中有详细的讲解和代码分享。基本的对话系统所用到的理论和基本实现已经讲解完毕。现在大家应该对于如何实现一个对话机器人系统有了一个理论上的框架了,那么下面就要看看如何实现它。
六、完整实现
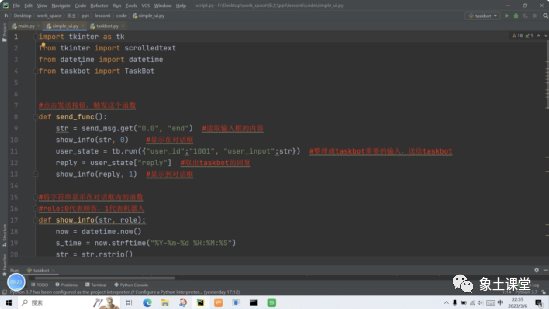
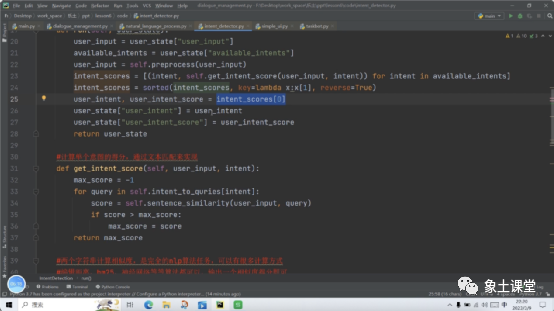
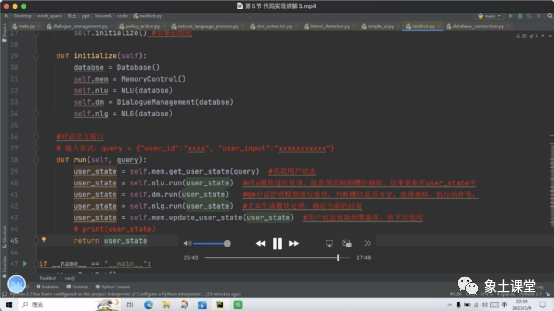
限于篇幅无法完全分享代码的内容和详细的讲解。如果大家有兴趣或者有需要可以找老师索取。订餐机器人的工程代码在很多场景都可以复用,如:订餐、订票、问询等。建议大家可以自己RUN一下工程代码,从理论到实践真正的跑一下,这样有助于你们的记忆和获得更大的收获。希望今天的分享能对大家有所帮助!最后祝大家工作顺利、学有所得。
笔者介绍
Richard , 工学博士。有15年通讯和互联网软件研发管理经验,超过10年机器学习/算法研发及管理经验。曾在腾讯、华为等大型公司担任技术管理人员。申请了10余个算法专利授权。
Arthur , 首席数据科学家。毕业于浙江大学计算机系。10年企业级软件服务与大型电信增值业务软件研发管理经验,8年机器学习/深度学习研发及管理经验。曾在某知名大型公司担任技术管理人员。出版了2本深度学习著作,申请了多个算法专利授权。
David , 普渡大学计算机硕士。有10年机器学习/算法研发经验。主要工作方向围绕自然语言理解和对话系统,接触落地项目种类丰富。申请了10余个算法专利授权,在多个算法比赛上获得前三名成绩。

进NLP群—>加入NLP交流群