近期开发了一套基于自然语言处理的问答机器人,之前没有做过python,主要做asp.net,写这篇目的是给想要开发这类智能客服系统的朋友提供一个思路,项目已经上线,但在开发和设计过程中仍然有很多问题没有得到解决,也期望和大家一同讨论学习。
最终的上线效果:
开发过程大概3阶段,第一阶段 完成基础一问一答功能;第二阶段 加入意图识别,可以进一步区分用户问题,特定意图比如工资查询,将会调用第三方接口;第三阶段 上下文处理,引导用户进行多轮问答;
插一句微软认知服务是云端的较好解决方案, BOT Framework平台集成了多种对接方式,无需自己开发。LUIS的配置和发布也非常方便,特别的如果使用场景真的非常简单(一问一答),可以仅用QnAMaker。

but... 基于业务数据暴露和其他安全性考虑,有时需要将服务部署在本地(内网),我主要想说的就是本地开发搭建的问答服务。
1 基础问答实现
1.1选型
能够做基础问答的开源项目非常多chatterbot,rasa_core等等。我选用的是chatterbot(0.7.6)
1.2开发
在搭建完开发环境后chatterbot可以直接使用,默认算法是编辑距离,所以理论上支持任何语言,包括中文。
我主要修改了chatterbot算法模块,适配器模块和输入输出模块,最终输出格式如下

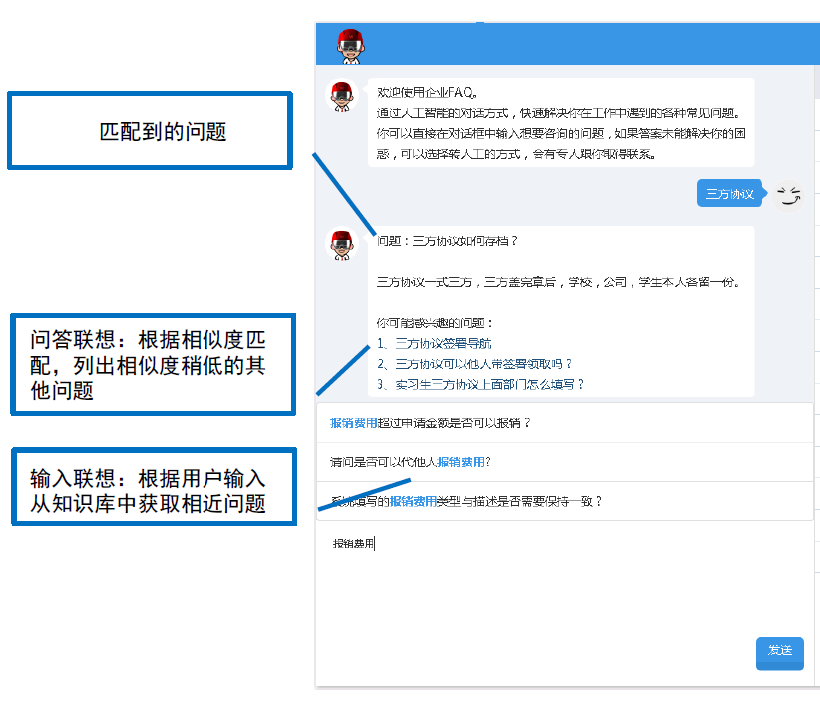
{ "text": "三方协议一式三方,三方盖完章后,学校,公司,学生本人各留一份。", "in_response_to": [{ "text": "三方协议如何存档?", "created_at": "2017-11-24T15:11:06.500966", "occurrence": 4 }], "created_at": "2017-11-24T15:11:06.500", "extra_data": { "userid": "1000058" }, "question": "三方协议如何存档?", "oriquestion": "三方协议", "channel": "2", "suggestions": [ ["三方协议如何存档?", 0.62], ["三方协议可以他人带签署领取吗?", 0.42], ["实习生三方协议上面部门怎么填写?", 0.4] ] }
text答案,in_response_to上下文,extra_data附加信息(可以放用户身份标识等),question匹配到的问题,oriquestion用户输入问题,channel词库编号(支持多词库每个词库可能有不同的处理),感兴趣问题列表(匹配度稍低的问题)
chatterbot的adapter本来设计是可以放多个,每个适配器完成自己的功能(解耦),但实际使用时(5000条问答),多适配器是非常缓慢的,由于每个适配器都会循环处理或比对问题,所以建议只放一个adapter实现所有功能
'logic_adapters':['mybot.MyLogicAdapter']
算法
位于comparisons.py中默认的编辑距离算法或杰拉德相似系数算法,都是基于简单的文本比对,无法处理同义词近义词。这里我们引入的word2vec算法
训练数据来自中文维基百科,加入了特定业务文档数据(仅73M,维基百科1.11G...)
使用jieba分词,gensim word2vec训练模型,特征向量400维,大概需要14小时(参考我的吃鸡电脑I7 7700 GTX1080)。
# 装载之前训练好的模型
custom_model = Word2Vec.load('data/custom.model')
用户输入先通过jieba分词,得到词和词频的数组,例如:查询我的薪资
查询 2 我 5 的 1 薪资 3
# 查询key在模型中向量 vec =custom_model['查询'] # 加权(模型中向量*jieba分词中权重)
sentvec = sentvec + vec * 2
把句子中词向量相加得到整个句子的向量。
再利用夹角余弦,与业务词库中的问题比较,得到最相似的问题匹配。
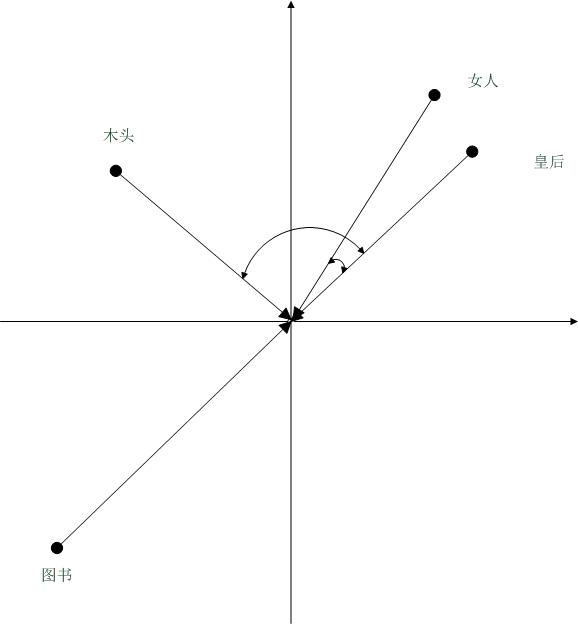
此方法,可以处理诸如,皇后->女人 这类的近义问题。从图上可以看到女人与皇后余弦夹角小于皇后与木头余弦夹角,结论为女人与皇后更相似。
所以最终的算法:编辑距离+word2vec。
2 意图识别
意图识别属于自然语言理解范围,主流机器学习算法支持向量机、决策树等分类方法。我们使用意图识别主要用来分离出用户的查询意图,再调用对应的第三方接口将数据返回给用户,例如 北京今天天气?识别为天气意图,实体为北京。
2.1选型
我们这里选用开源项目rasa_nlu(11.0.3),这是一个集意图识别,实体提取功能于一体的项目。可以生成如下的数据
{ "intent": { "name": "weather", "confidence": 0.44477984330690684 }, "entities": [ { "entity": "city", "value": "大连", "start": 0, "end": 2, "extractor": "ner_mitie" }, { "entity": "date", "value": "后天", "start": 2, "end": 4, "extractor": "ner_mitie" } ], "intent_ranking": [ { "name": "weather", "confidence": 0.44477984330690684 }, { "name": "bookhotel", "confidence": 0.37330751883981904 }, { "name": "map", "confidence": 0.18191263785327412 } ], "text": "大连后天天气怎么样" }
2.2开发
在实际使用中,有时可能仅需要提取实体,所以我额外做了一个流程,仅提取实体。
{ "entities": [ { "entity": "city", "value": "大连", "start": 0, "end": 2, "extractor": "ner_mitie" } ], "text": "大连天气怎么样" }
2.3命名实体提取替换
项目最终使用"pipeline": ["tokenizer_jieba","ner_synonyms","intent_entity_featurizer_regex","intent_featurizer_mitie","intent_classifier_sklearn","ner_corenlp"] 之前使用MITIE作为命名实体提取,但MITIE需要自己训练,实际使用时训练语句过少,正确率偏低,改用corenlp,默认支持中文 我截取目标默认可以识别的实体类型
# DATE: type:日期 eg:明天 # LOCATION: type:地点 eg:齐齐哈尔 # MISC: type:其他 eg:怎么样 # MONEY: type:金额 # ORGANIZATION: type:组织 # PERCENT: type:百分比 # PERSON: type:人 eg:特朗普 # TIME: type:时间 eg:下午 # O: type:动词或其他 eg:查询 # COUNTRY: type:国家 eg:中国 # STATE_OR_PROVINCE: type:城市/省会 eg:北京 # CITY: type:城市 eg:西安
2.0补充
系统缺陷修复,使用rasa_nlu意图分类,基于sklearn-svmcv算法,但是分类后,各意图结果相加始终等于1,我之前的设想(后面有详细说明):设定一个阈值比如0.7,判断最高匹配度的意图是否大于阈值,如果大于则认为明确意图。但这基于问题是意图的前提,
我训练意图用了三个分类weather,bookhotel,map,但我无法将问答的5000个问题训练为other意图,由于5000个问答中涉及多领域,非常多的特征向量会对意图分类造成很大影响,使分类不准确。
目前的解决方案为在意图识别前,加入一个二分类器,也基于sklearn的分类器,用于区分问题还是意图,训练使用18000条生产环境用户问题和6000*3加权的意图问题(等量的训练数据)训练并比较准确率。
| 用户问题 | 标识(1意图0普通问题) |
| 今天天气如何 | 1 |
| 我想预订北京的酒店 | 1 |
| 机器人的内部处理流程是怎样的 | 0 |
| 公司发展历程 | 0 |
生成pkl文件。将pkl文件放入指定位置,替换最准确算法。
当前最高为随机森林算法
******************* NB ********************
accuracy: 90.06%
******************* KNN ********************
accuracy: 87.50%
******************* LR ********************
accuracy: 90.91%
******************* RF ********************
accuracy: 96.31%
******************* DT ********************
accuracy: 95.17%
******************* SVM ********************
accuracy: 25.28%
******************* SVMCV ********************
accuracy: 93.75%
******************* GBDT ********************
accuracy: 87.78%
3 上下文
看了很多大神基于深度学习算法的帖子还有论文,感觉实在力不从心... 这里使用模板配置的方式,引导用户完成上下文。
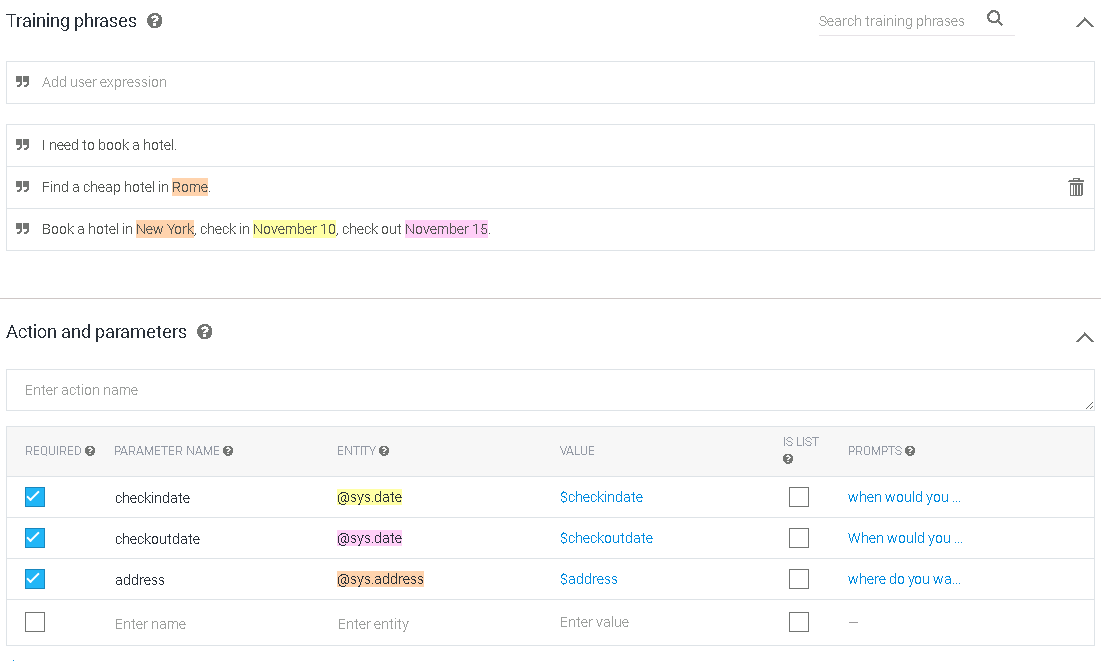
JSON数据格式
{
"rule": [{
"intent": "weather",
"entities": [
{"name":"city","type":"city","required":"true","prompts":["请问查询哪里的天气","想查询哪个城市的天气"]},
{"name":"date","type":"date","required":"false","prompts":[]}
]
},
{
"intent": "bookhotel",
"entities": [
{"name":"city","type":"city","required":"true","prompts":["请问预订哪里","想预订哪个城市"]},
{"name":"checkindata","type":"date","required":"true","prompts":["请问何时入住","预订酒店的时间"]},
{"name":"checkoutdata","type":"date","required":"false","prompts":[]}
]
},
{
"intent": "bookticket",
"entities": [
{"name":"fromcity","type":"city","required":"true","prompts":["请提供出发城市","从哪起飞"]},
{"name":"tocity","type":"city","required":"true","prompts":["请提供到达城市","到哪落地"]},
{"name":"date","type":"date","required":"true","prompts":["请问预订机票的时间","想预订哪天的机票"]}
]
}
]
}
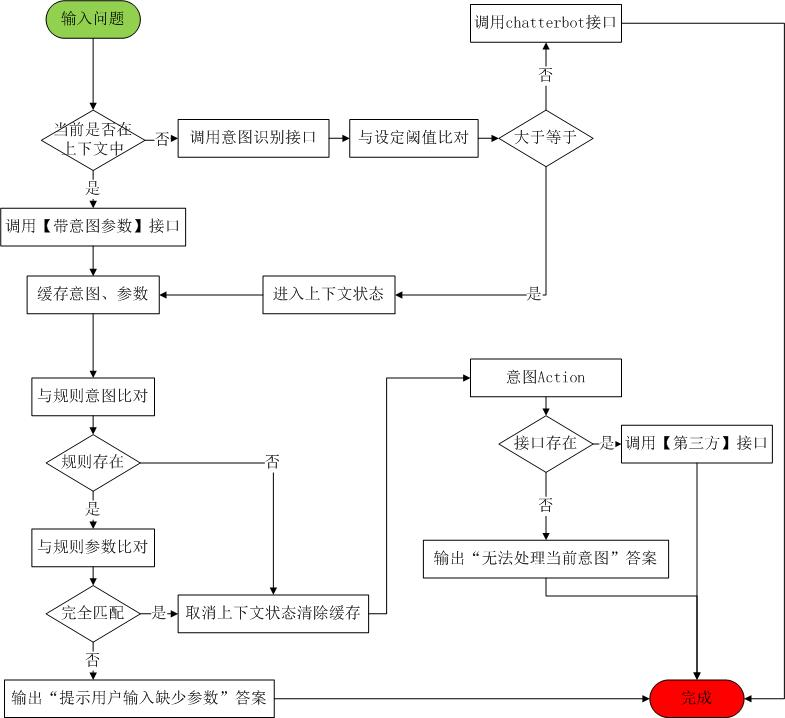
这就是上下文的控制流程,主要代码逻辑控制,没有使用机器学习算法。
特别的,这里阈值非常的重要,阈值范围0~1,越小越容易被理解为意图,当为1时,等同于关键字匹配。
举个栗子,如果阈值设定非常小,用户的普通提问都会被理解为意图,不会进入chatterbot问答中,如果非常大,则难以进入意图识别,训练data 查询工资,如果用户输入“查询我的工资”可能也不会进入意图查询
阈值我使用梯度下降算法,拟合成二维曲线,找到最高点,0.74
后记
项目开发过程大概4个月(第一周,学习python基础语法,主要了解函数,变量赋值逻辑,web api实现,之后开始学习深度学习算法,主要从帖子、论文和视频,MIT、台大、Stanford的教学视频都非常好,可以在B站上看,选型时几乎试用了所有开源的QA项目,一般QA项目都需要训练,准备语料所以耗费了大量时间),独立开发,实际编码时间一个月,最后用asp.net mvc封装了这些接口,做了问答页面和简单的后台语料管理系统(我也想用python...来不及)
我们业务问答5000多条,一共有3个实习生,配合我标注语料,编写测试集和验证集(真正的工作量在这)
最终正确率:68.4%(微软验证集正确率:81.7%)
chatterbot 项目主框架
https://github.com/gunthercox/ChatterBot
sklearn 意图问题分类
https://github.com/automl/auto-sklearn
rasa_nlu 意图识别模块
https://github.com/RasaHQ/rasa_nlu
gensim word2vec算法实现
https://github.com/RaRe-Technologies/gensim
word2vec,中文处理
https://github.com/zake7749/word2vec-tutorial
相似度比较-向量余弦夹角
https://github.com/kris2692/Vector-semantics
主要问题:
1.正确率太低:如果单用word2vec算法,正确率只有36.2%,单用编辑距离算法正确率59.8%,不知道为何我写word2vec算法正确率如此低,一直没有找到原因。
2.数据分散,用多种语言编写:整个项目一共三部分:chatterbot,rasa_nlu,mvc web,在修改意图时非常麻烦,在管理系统修改意图后,生成json文件,需要手工拷贝到rasa_nlu项目中,再使用cmd命令train,start server。
原文地址:https://www.cnblogs.com/yilanyang/p/8629948.html