忆如完整项目/代码详见github:https://github.com/yiru1225(转载标明出处 勿白嫖 star for projects thanks)
目录

3.PCA与LDA分别结合SVM在各维度、各数据集的人脸识别率及其与KNN的对比
3.1 ORL下比较SVM与KNN对于PCA和LDA的人脸识别率随维度的改变
4.1 ORL下比较OVO与OVR实现SVM + PCA的人脸识别率随维度的改变
4.2 OVO与OVR实现SVM + PCA在不同数据集下的平均人脸识别率
系列文章目录
本系列博客重点在机器学习的概念原理与代码实践,不包含繁琐的数学推导(有问题欢迎在评论区讨论指出,或直接私信联系我)。
代码可以全抄 大家搞懂原理与流程去复现才是有意义的!!!
第一章 机器学习——PCA(主成分分析)与人脸识别_@李忆如的博客-CSDN博客
第二章 机器学习——LDA (线性判别分析) 与人脸识别_@李忆如的博客-CSDN博客
第三章 机器学习——LR(线性回归)、LRC(线性回归分类)与人脸识别_@李忆如的博客
第四章 机器学习——SVM(支持向量机)与人脸识别
梗概
本篇博客主要介绍SVM(支持向量机)算法,利用经典SVM实现图像识别二分类,并将SVM(OVO与OVR均实现)+ 降维方法(PCA与LDA)用于人脸识别,并将SVM与KNN进行比较,OVO与OVR进行比较(内附数据集与matlab、python代码)
一、SVM的概念与原理
1.SVM简介
支持向量机(SVM)是在分类与回归中分析数据的有监督学习模型与相关的学习算法。本质上是一种二分类模型,它的经典模型是定义在特征空间的间隔最大的线性分类器,学习策略是间隔最大化。
2.SVM基本流程
SVM模型将实例表示为空间(超平面、超空间)中的点,这样映射就使得单独类别的实例被尽可能宽的明显的间隔分开。然后,将新的实例映射到同一空间,并基于它们落在间隔的哪一侧来预测所属类别。
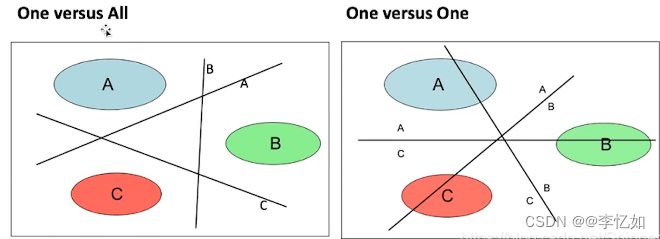
3.SVM在多分类中的推广
由于SVM是一种二分类器,即用一条线或一个平面分开两类不同数据,一般用如下两个方法使其推广到多分类。
① OVR:对于K个类别的情况,训练K个SVM,第j个SVM用于判断任意条数据是属于类别j还是类别非j。预测的时候,具有距超空间i最大值的表示给定的数据x属于类别i。
② OVO:对于K个类别的情况,训练K*(K-1)/2个SVM,每一个SVM只用于判断任意条数据是属于K中的特定两个类别。预测的时候,使用K*(K-1)/2个SVM做K*(K-1)/2次预测,使用计票的方式决定数据被分类为哪个类别的次数最多,就认为数据x属于此类别。
Tips:SVM详细推导可见:svm原理详细推导_weixin_42001089的博客-CSDN博客_svm推导
二、经典SVM运用于图像识别分类
① 问题描述:识别图片属于森林还是房间
② 算法实现核心:使用mapminmax实现划分后的数据集归一化,利用函数fitcsvm训练归一化后训练集,通过求解二次规划与准备参数,得到a并找到支持向量,predict用刚刚训练出的模型预测,求b得到f(x)与预测类别。
③ 代码如下:
clear;
% dataset是将bedroom和forest合并;dataset = [bedroom;forset];这行代码可以实现合并
load forest.mat %导入要分类的数据集
load bedroom.mat
dataset = [bedroom;MITforest];
load labelset.mat %导入分类集标签集
% 选定训练集和测试集
% 将第一类的1-5,第二类的11-15做为训练集
train_set = [dataset(1:5,:);dataset(11:15,:)];
% 相应的训练集的标签也要分离出来
train_set_labels = [lableset(1:5);lableset(11:15)];
% 将第一类的6-10,第二类的16-20,做为测试集
test_set = [dataset(6:10,:);dataset(16:20,:)];
% 相应的测试集的标签也要分离出来
test_set_labels = [lableset(6:10);lableset(16:20)];
% 数据预处理,将训练集和测试集归一化到[0,1]区间
[mtrain,ntrain] = size(train_set);
[mtest,ntest] = size(test_set);
test_dataset = [train_set;test_set];
% mapminmax为MATLAB自带的归一化函数
[dataset_scale,ps] = mapminmax(test_dataset',0,1);
dataset_scale = dataset_scale';
train_set = dataset_scale(1:mtrain,:);
test_set = dataset_scale( (mtrain+1):(mtrain+mtest),: );
% SVM网络训练
model = fitcsvm(train_set,train_set_labels);
% SVM网络预测
[predict_label] = predict(model,test_set);
%[predict_label] = model.IsSupportVector;
% 结果分析
% 测试集的实际分类和预测分类图
% 通过图可以看出只有一个测试样本是被错分的
figure;
hold on;
plot(test_set_labels,'o');
plot(predict_label,'r*');
xlabel('测试集样本','FontSize',12);
ylabel('类别标签','FontSize',12);
legend('实际测试集分类','预测测试集分类');
title('测试集的实际分类和预测分类图','FontSize',12);
grid on;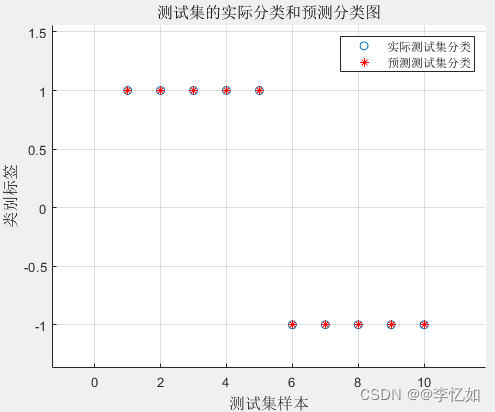
分析:分析上图可知,预测分类与实际分类均相等,预测效果很好。
三、SVM运用于人脸识别
1.预处理
1.1 数据导入与处理
利用imread批量导入人脸数据库,或直接load相应mat文件,并在导入时不断将人脸拉成一个个列向量组成reshaped_faces,并取出n%作为测试数据,剩下100-n%作为训练数据,重复此步骤,将导入数据抽象成框架,可以匹配不同数据集的导入(本实验框架适配ORL、AR、FERET数据集)。
Tips:代码可见本系列第二篇文章(LDA与人脸识别),基本一致。
1.2 数据降维
使用LDA或PCA对数据降维(具体原理与详细代码见本系列一二篇文章)
% LDA
% 算每个类的平均
k = 1;
class_mean = zeros(dimension, people_num);
for i=1:people_num
% 求一列(即一个人)的均值
temp = class_mean(:,i);
% 遍历每个人的train_pic_num_of_each张用于训练的脸,相加算平均
for j=1:train_pic_num_of_each
temp = temp + train_data(:,k);
k = k + 1;
end
class_mean(:,i) = temp / train_pic_num_of_each;
end
% 算类类间散度矩阵Sb
Sb = zeros(dimension, dimension);
all_mean = mean(train_data, 2); % 全部的平均
for i=1:people_num
% 以每个人的平均脸进行计算,这里减去所有平均,中心化
centered_data = class_mean(:,i) - all_mean;
Sb = Sb + centered_data * centered_data';
end
Sb = Sb / people_num;
% 算类内散度矩阵Sw
Sw = zeros(dimension, dimension);
k = 1; % p表示每一张图片
for i=1:people_num % 遍历每一个人
for j=1:train_pic_num_of_each % 遍历一个人的所有脸计算后相加
centered_data = train_data(:,k) - class_mean(:,i);
Sw = Sw + centered_data * centered_data';
k = k + 1;
end
end
Sw = Sw / (people_num * train_pic_num_of_each);
% 目标函数一:经典LDA(伪逆矩阵代替逆矩阵防止奇异值)
% target = pinv(Sw) * Sb;
% PCA
centered_face = (train_data - all_mean);
cov_matrix = centered_face * centered_face';
target = cov_matrix;
% 求特征值、特征向量
[eigen_vectors, dianogol_matrix] = eig(target);
eigen_values = diag(dianogol_matrix);
% 对特征值、特征向量进行排序
[sorted_eigen_values, index] = sort(eigen_values, 'descend');
eigen_vectors = eigen_vectors(:, index);
eigen_vectors = real(eigen_vectors); % 处理复数,会导致一定误差(LDA用)2.人脸识别
实现核心流程:使用PCA/LDA先对数据进行预处理与降维,SVM使用OVO/OVR对划分好的数据集进行模型训练与测试集预测,最终记录识别率并与比较。
2.1 OVO实现SVM
%使用SVM人脸识别
% SVM(OVO)
rate = []; %用于记录人脸识别率
for i=10:10:160
right_num = 0;
% 降维得到投影矩阵
project_matrix = eigen_vectors(:,1:i);
projected_train_data = project_matrix' * (train_data - all_mean);
projected_test_data = project_matrix' * (test_data - all_mean);
% SVM训练过程
model_num = 1;
for j = 0:1:people_num - 2
train_img1 = projected_train_data(:,j * train_pic_num_of_each + 1 : j * train_pic_num_of_each + train_pic_num_of_each); % 取出每次SVM需要的训练集
train_label1 = ones(1,train_pic_num_of_each)*(j + 1); % 给定训练标签
test_img1 = projected_test_data(:,j * test_pic_num_of_each + 1 : j * test_pic_num_of_each + test_pic_num_of_each); % 取出每次SVM需要的测试集
for z = j + 1:1:people_num - 1
train_img2 = projected_train_data(:,z * train_pic_num_of_each + 1 : z * train_pic_num_of_each + train_pic_num_of_each); % 取出每次SVM需要的训练集
train_label2 = ones(1,train_pic_num_of_each)*(z + 1); % 给定训练标签
train_imgs = [train_img1,train_img2];
train_label = [train_label1,train_label2];
test_img2 = projected_test_data(:,z * test_pic_num_of_each + 1 : z * test_pic_num_of_each + test_pic_num_of_each); % 取出每次SVM需要的测试集
test_imgs = [test_img1,test_img2];
% 数据预处理,将训练集和测试集归一化到[0,1]区间
[mtrain,ntrain] = size(train_imgs); %m为行数,n为列数
[mtest,ntest] = size(test_imgs);
test_dataset = [train_imgs,test_imgs];
% mapminmax为MATLAB自带的归一化函数
[dataset_scale,ps] = mapminmax(test_dataset,0,1);
train_imgs = dataset_scale(:,1:ntrain);
test_imgs = dataset_scale( :,(ntrain+1):(ntrain+ntest) );
% SVM网络训练
train_imgs = train_imgs';
train_label = train_label';
expr = ['model_' num2str(model_num) ' = fitcsvm(train_imgs,train_label);']; % fitcsvm默认读取数据为按行,一张一脸为一列,需要转置
eval(expr);
model_num = model_num + 1;
end
end
model_num = model_num - 1;
% 人脸识别
test = []; % 测试用
for k = 1:1:test_pic_num_of_each * people_num
test_img = projected_test_data(:,k); % 取出待识别图像
test_real_label = fix((k - 1) / test_pic_num_of_each) + 1; % 给定待测试真实标签
predict_labels = zeros(1,people_num); %用于OVO后续投票
% SVM网络预测
for t = 1:1:model_num
predict_label = predict(eval(['model_' num2str(t)]),test_img');
% test = [test,predict_label]; % 测试用
predict_labels(1,predict_label) = predict_labels(1,predict_label) + 1;
end
[max_value,index] = max(predict_labels);
if(index == test_real_label)
right_num = right_num + 1;
end
end
recognition_rate = right_num / (test_pic_num_of_each * people_num);
rate = [rate,recognition_rate];
end 2.2 OVR实现SVM
% SVM(OVR)
rate = []; %用于记录人脸识别率
for i = 10:10:160
right_num = 0;
% 降维得到投影矩阵
project_matrix = eigen_vectors(:,1:i);
projected_train_data = project_matrix' * (train_data - all_mean);
projected_test_data = project_matrix' * (test_data - all_mean);
model_num = 1;
% SVM训练过程(每次训练都要使用整个数据集)
for j = 0:1:people_num - 1
train_imgs = circshift(projected_train_data,-j * train_pic_num_of_each ,2); %使训练集始终在前几行
train_label1 = ones(1,train_pic_num_of_each) * (j + 1);
train_label2 = zeros(1,train_pic_num_of_each * (people_num - 1));
train_label = [train_label1,train_label2];
test_imgs = circshift(projected_test_data,-j * test_pic_num_of_each ,2); %使测试集始终在前几行
% 数据预处理,将训练集和测试集归一化到[0,1]区间
[mtrain,ntrain] = size(train_imgs); %m为行数,n为列数
[mtest,ntest] = size(test_imgs);
test_dataset = [train_imgs,test_imgs];
% mapminmax为MATLAB自带的归一化函数
[dataset_scale,ps] = mapminmax(test_dataset,0,1);
train_imgs = dataset_scale(:,1:ntrain);
test_imgs = dataset_scale( :,(ntrain+1):(ntrain+ntest) );
% SVM网络训练
train_imgs = train_imgs';
train_label = train_label';
expr = ['model_' num2str(model_num) ' = fitcsvm(train_imgs,train_label);']; % fitcsvm默认读取数据为按行,一张一脸为一列,需要转置
eval(expr);
model_num = model_num + 1;
end
model_num = model_num - 1;
% 人脸识别
for k = 1:1:test_pic_num_of_each * people_num
test_img = projected_test_data(:,k); % 取出待识别图像
test_real_label = fix((k - 1) / test_pic_num_of_each) + 1; % 给定待测试真实标签
predict_labels = zeros(1,people_num); %用于OVR预测
% SVM网络预测
for t = 1:1:model_num
[predict_label,possibility] = predict(eval(['model_' num2str(t)]),test_img');
if predict_label ~= 0
predict_labels(1,predict_label) = predict_labels(1,predict_label) + possibility(1,1);
end
end
[min_value,index] = min(predict_labels); % 若一张图片被预测为多类,选择离超平面最远的作为最终预测类
if(index == test_real_label)
right_num = right_num + 1;
end
end
recognition_rate = right_num / (test_pic_num_of_each * people_num);
rate = [rate,recognition_rate];
end
3.PCA与LDA分别结合SVM在各维度、各数据集的人脸识别率及其与KNN的对比
运行SVM.m,比较在ORL(或其他数据集下)SVM(OVO实现为例)+降维方法与KNN+降维方法的人脸识别率随维度的变化,并在多个数据集下比较不同方法的人脸识别率,结果与分析如下:
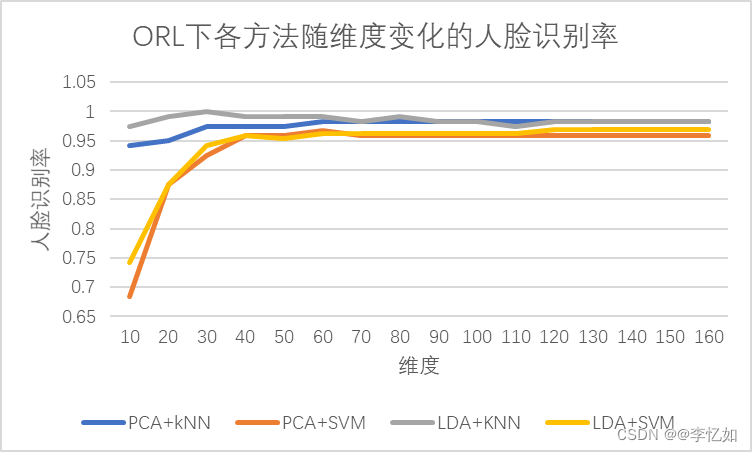
3.1 ORL下比较SVM与KNN对于PCA和LDA的人脸识别率随维度的改变
3.2 各种方法在不同数据集下的平均人脸识别率
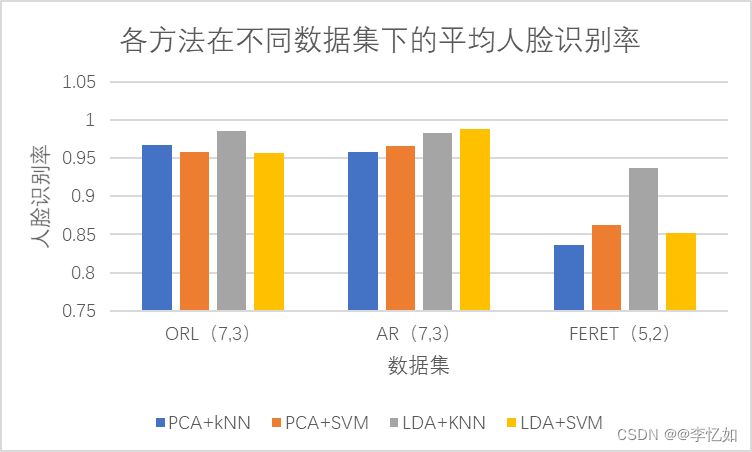
Tips:数据集后为训练集与测试集的划分比
分析:分析以上两组图可知,各方法的人脸识别率与维度、数据集、参数选择均存在巨大关系,并没有某种方法组合在所有维度所有数据集下均具有优越性。
4.OVO与OVR实现SVM的人脸识别率比较
分别用OVO与OVR的思想训练SVM不同分类器并应用于人脸识别,在不同维度、不同数据集下的人脸识别率如下:
4.1 ORL下比较OVO与OVR实现SVM + PCA的人脸识别率随维度的改变

4.2 OVO与OVR实现SVM + PCA在不同数据集下的平均人脸识别率
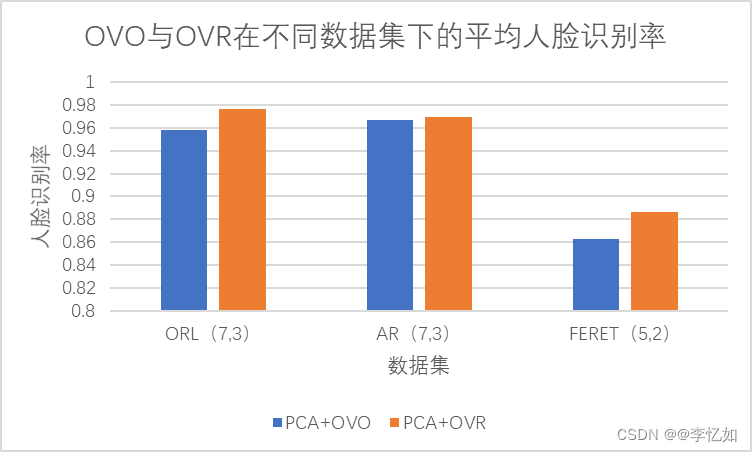
分析:分析以上两组图可知,OVR实现SVM时在低维度时识别率低于OVO实现SVM,随着维度增加,OVR的识别率逐渐稳定地优于OVO,且在实验的三个数据集中,OVR的平均识别率均高于OVO。另外,OVR训练的分类器数量少,在小数据集下效率更高,但随着数据规模增大,OVR每次训练数据过大,效率会逐渐低于OVO。
5.方法与函数的补充
对于多分类SVM,matlab可以使用fitcecoc函数,python可以使用svm.SVC搭配fit与predict直接实现多分类SVM,而不需要多次训练二分类SVM。
四、创新SVM算法设计
① 经典SVM不足:无法处理非线性数据,对大规模训练样本难以实施。
② 已有改进:软间隔SVM/核SVM/ CSVM等
③ 创新SVM算法简述:
(1)SMO后通过对核函数的缓存可以大大增加算法效率。因为在经典SVM中,空间消耗主要在模型的训练,时间消耗主要在各种核函数与其他模型、函数的调用。
(2)对于最优化问题中f(x)的计算需要不断循环,代价很高,在此定义并缓存一个g(x)如下,让我们可以随时计算误差:

(3)优化数据集划分,实现冷热数据分离。热数据在前(大于0小于C的alpha值),冷数据在后(小于等于0 或者大于等于 C 的alpha)在后。随着迭代加深,大部分时候只需要在热数据里求解,并且热数据的大小会逐步不停的收缩,所以区分了冷热以后SVM 大部分都在针对有限的热数据迭代。
(4)传入外部分类“权重”修正结果,提高识别率。用原始的 C 乘以各自分类的权重,得到 Cp 和 Cn,然后迭代时,不同的样本根据它的 y 值符号,用不同的 C 值带入计算。
(5)同时支持稀疏和非稀疏,针对不同数据,选择合适的方式求解。
五、其他
1. 数据集及资源
本实验所用数据集:ORL5646、AR5040、FERET_80,代码框架可适用多个数据集。
常用人脸数据集如下(不要白嫖哈哈哈)
链接:https://pan.baidu.com/s/12Le0mKEquGMgh5fhNagZGw
提取码:yrnb
SVM完整代码与二分类所需数据集:李忆如/忆如的机器学习 - Gitee.com
2. 参考资料
1.支持向量机(SVM)的推导(线性SVM、软间隔SVM、Kernel Trick) - liuyang0 - 博客园
2.手撕SVM公式——硬间隔、软间隔、核技巧_Dominic_S的博客-CSDN博客_硬间隔
3.手写SVM算法(Matlab实现) - 知乎 (zhihu.com)
4.SVM支持向量机+实例展示_Snippers的博客-CSDN博客_svm支持向量机
5.周志华《机器学习》
总结
SVM作为经典的线性二分类器,通过”最大化间隔“为目标导向对数据进行超空间(平面)投影并划分。如今仍然在机器学习许多领域(数据分类、语言图像处理、推荐系统)有优异表现。且作为一种有监督学习方法(利用了数据的原有信息),SVM能得到较好的保留数据信息。但SVM仍存在处理高维数据大计算代价问题、不好刻画非线性问题等等,另外,SVM假设的数据属性在现实世界的问题中往往难以达到,从而影响实验结果,后续博客会分析其他算法优化或解决上述问题。