hello,我是毛豆。本系列用最精简的代码和案例带你快速入门量化,只讲最干的干货,想要学习量化又不知道该如何上手的小伙伴赶紧看过来!
前期回顾:
本期内容将介绍如何用python做推断统计。推断统计是指在样本数据有限的情况下,推断总体统计特征的统计方法。推断统计包括2类,分别是参数估计和假设检验,下文详细介绍。毛豆在每周末都会更新这个系列,建议大家收藏起来方便学习。
一、绘制收益率直方图
我们以上证指数收益率为例,计算样本均值与标准差,并绘制直方图。
首先导入相关的包,并认证Tushare Pro账号。
import tushare as ts
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
pro = ts.pro_api('your token')获取今年以来的上证指数数据:
df1=ts.get_k_data('sh',start='2023-01-01',end='2023-05-26')#上证指数
df1.tail()返回如下:

用之前学到的方法计算上证指数的日收益率:
df1['lagclose']=df1.close.shift(1)
df1['SHRet']=(df1['close']-df1['lagclose'])/df1['lagclose']
df1.tail()返回如下:

计算收益率均值与标准差:
SHRet=df1.SHRet.dropna()
mu=SHRet.mean()#均值
sigma=SHRet.std()#标准差
print('均值:{}'.format(mu))
print('标准差:{}'.format(sigma))打印如下:

用一行代码绘制上证指数收益率直方图:
SHRet.hist()返回如下:
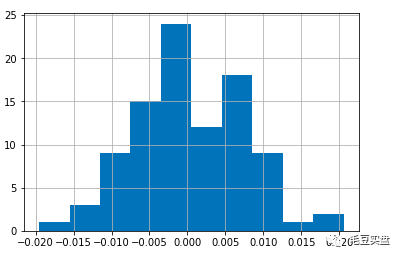
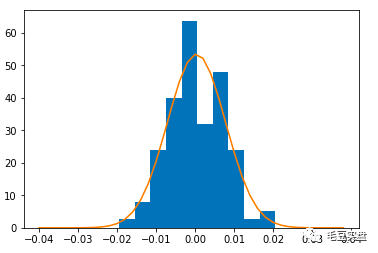
也可以在直方图上添加正态分布曲线:
plt.hist(SHRet,density=True)
plt.plot(np.arange(-0.04,0.04,0.002),stats.norm.pdf(np.arange(-0.04,0.04,0.002),mu,sigma))返回如下:
二、参数估计
参数估计有点估计和区间估计两种形式。
点估计也称定值估计,是指在参数估计中不考虑估计的误差,直接用样本估计量估计总体参数的一种参数估计方法。如直接用样本均值估计总体均值,用样本方差估计总体方差等。
区间估计则考虑到了估计存在到误差,是在点估计的基础上估计总体参数所在的区间范围,该区间范围是以一定的概率保证所得到的,区间的下限/上限由样本统计量减去/加上估计误差得到。其中,被推断的总体参数的区间范围即置信区间,估计的可靠程度为置信度。
当样本容量一定时,若增大置信度,则置信区间宽度增大,此时会降低估计的精准度;若要提高精准度,则置信度必然减小。因此,对置信度和精准度的要求往往是矛盾的,如果想要同时满足量方面的要求,则必然要增加样本容量。
1.区间估计的python函数
如果满足正态分布或者近似正态分布,那么我们采用stats模块的norm类的interval()函数。如果是t分布,采取stats模块的t类的interval()函数。
stats.norm.interval(alpha, loc, scale)
stats.t.interval(alpha, df, loc, scale)其中alpha为置信度,df是自由度,对于t分布的区间估计,自由度为n-1,loc为样本均值,scale为标准误差,通过stats.sem()计算。
2.上证指数收益率区间估计
对上证指数收益率进行区间估计,在置信度95%时,自由度为93的t分布,均值置信区间:
stats.t.interval(0.95,len(SHRet)-1,mu,stats.sem(SHRet))返回如下:
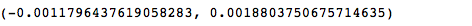
也就是说,总体均值有95%的概率在此区间内,5%的概率不在这个区间内。
三、假设检验
参数估计的任务是猜测参数的取值,而假设检验的在于检验参数的取值是否等于某个目标值。
假设检验的核心思想是基于小概率事件(如p<0.01或p<0.05)在一次试验中基本不会发生。如果在我们的假设下,小概率事件发生了,那么可以认为假设不成立。
t检验所使用的统计量服从t分布,或者标准差未知,服从正态分布的总体的均值。常见的t检验有单样本检验、独立双样本检验、相关配对检验。
1. 单样本检验
例如我们使用今年以来的上证指数收益率数据,对其收益率均值是否为0进行t检验。原假设H0:上证指数收益率均值为0,备择假设:上证指数收益率均值不为0。
#只需输入我们要检验的变量以及要比较的数值即可
stats.ttest_1samp(SHRet,0)返回如下:
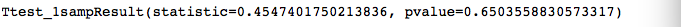
p>0.05,代表在5%的显著性水平下,我们无法拒绝原假设。
2.独立双样本检验
例如检验上证指数和深圳成指的收益率均值是否相等。
首先计算深圳成指的收益率:
df2=ts.get_k_data('sz',start='2023-01-01',end='2023-05-26')#深圳成指
df2['lagclose']=df2.close.shift(1)
df2['SHRet']=(df2['close']-df2['lagclose'])/df2['lagclose']
SZRet=df2.SHRet.dropna()检验上证指数和深圳成指的收益率均值是否相等:
#输入两个变量即可
stats.ttest_ind(SHRet,SZRet)3.配对样本t检验
#输入两个变量即可
stats.ttest_rel(SHRet,SZRet)以上是今天的全部干货内容,毛豆会在每周末更新这个系列,也会在每个交易日继续和大家分享旋风冲锋量化策略的实盘情况,欢迎大家点赞关注。
回测:旋风冲锋策略说明