hello,我是毛豆。本系列用最精简的代码和案例带你快速入门量化,只讲最干的干货,想要学习量化又不知道该如何上手的小伙伴赶紧看过来!
前期回顾:
本期内容将介绍如何用python做回归分析。回归分析(regression analysis)指的是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。回归分析按照涉及的变量的多少,分为一元回归和多元回归;按照因变量的多少,可分为简单回归分析和多重回归分析;按照自变量和因变量之间的关系类型,可分为线性回归分析和非线性回归分析。
下面我们来看看具体如何用python进行回归分析。毛豆在每周末都会更新这个系列,建议大家收藏起来方便学习。
指数收益率回归模型
首先导入相关的包,并认证Tushare Pro账号。
import tushare as ts
import numpy as np
import matplotlib.pyplot as plt
import statsmodels.api as sm
import scipy.stats as stats
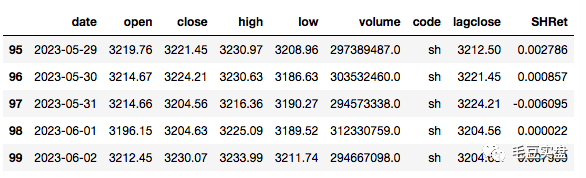
pro = ts.pro_api('your token')获取今年以来的上证指数数据,并计算收益率:
df1=ts.get_k_data('sh',start='2023-01-01',end='2023-06-02')#上证指数
df1['lagclose']=df1.close.shift(1)
df1['SHRet']=(df1['close']-df1['lagclose'])/df1['lagclose']
df1.tail()返回如下:
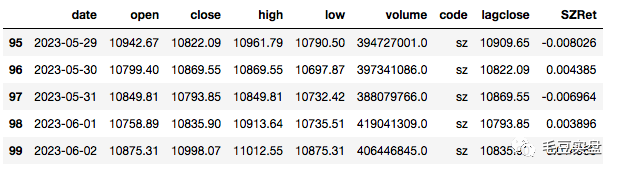
获取今年以来的深圳成指数据,并计算收益率:
df2=ts.get_k_data('sz',start='2023-01-01',end='2023-06-02')#深证成指
df2['lagclose']=df2.close.shift(1)
df2['SZRet']=(df2['close']-df2['lagclose'])/df2['lagclose']
df2.tail()返回如下:
核查两个变量是否存在缺失值、长度是否相等:
SHRet=df1.SHRet.dropna()
SZRet=df2.SZRet.dropna()
print(len(SHRet),len(SZRet))我们使用python中的统计分析包statsmodels中的OLS类来完成回归模型的构建。
使用fit()方法来拟合模型:
model=sm.OLS(SHRet,sm.add_constant(SZRet)).fit()使用summary()方法来查看模型结果:
#查看回归模型结果
print(model.summary())打印如下:
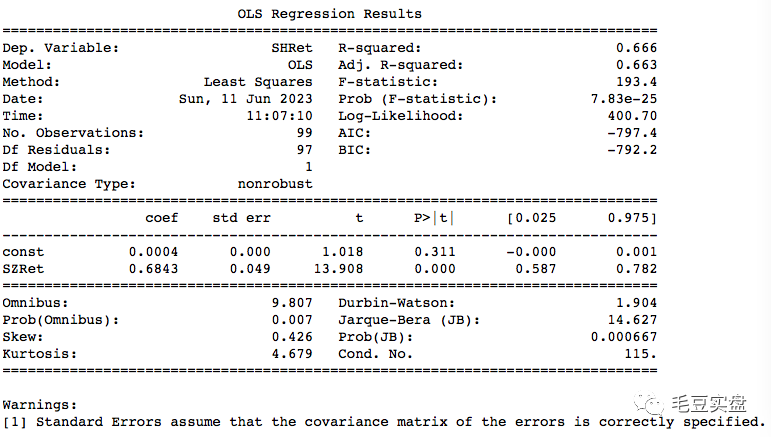
截距项0.0004,斜率项0.6843,因此我们可以得到模型为:
SHRet=0.0004+0.6843*SZRet+ε
拟合度为66.6%,表明模型可以解释上证指数66.6%的方差。
下面对表中度各项指标做一个说明。先来看第一个表:
Dep.Variable:因变量,在本模型中为上证指数收益率
Model:模型拟合方法,OLS为普通最小二乘法
Method:最优化方法,最小二乘法
No.Observations:观测样本量,本例中有99个(99天的数据)
DF Residuals:残差自由度(97)=观测样本量(99)-变量数(2)
DF Model:参数数量
R-squared:拟合度
Adj.R-squared:调整后的R-squared
F-statistic:F统计量
Prob (F-statistic):F统计量p值
Log-likelihood:对数似然
AIC:赤池系数
BIC:贝叶斯系数
再看第二个表:
coef:系数,包括截距和斜率
std err:标准差
t:t检验值,不清楚的参考前面的帖子
P > |t|:t检验p值
[0.025, 0.975]:97.5%的置信区间
绘制拟合值与残差的散点图:
#解决中文乱码
plt.rcParams['font.sans-serif']=['Arial Unicode MS']#用于mac
#plt.rcParams['font.sans-serif']=['SimHei']#用于windows
plt.rcParams['axes.unicode_minus'] = False
# 绘制拟合值和残差的散点图
plt.scatter(model.fittedvalues,model.resid)
plt.xlabel('拟合值')
plt.ylabel('残差')
plt.gca().set_aspect(1)
plt.savefig('fig1.png',dpi=400,bbox_inches='tight')返回如下:
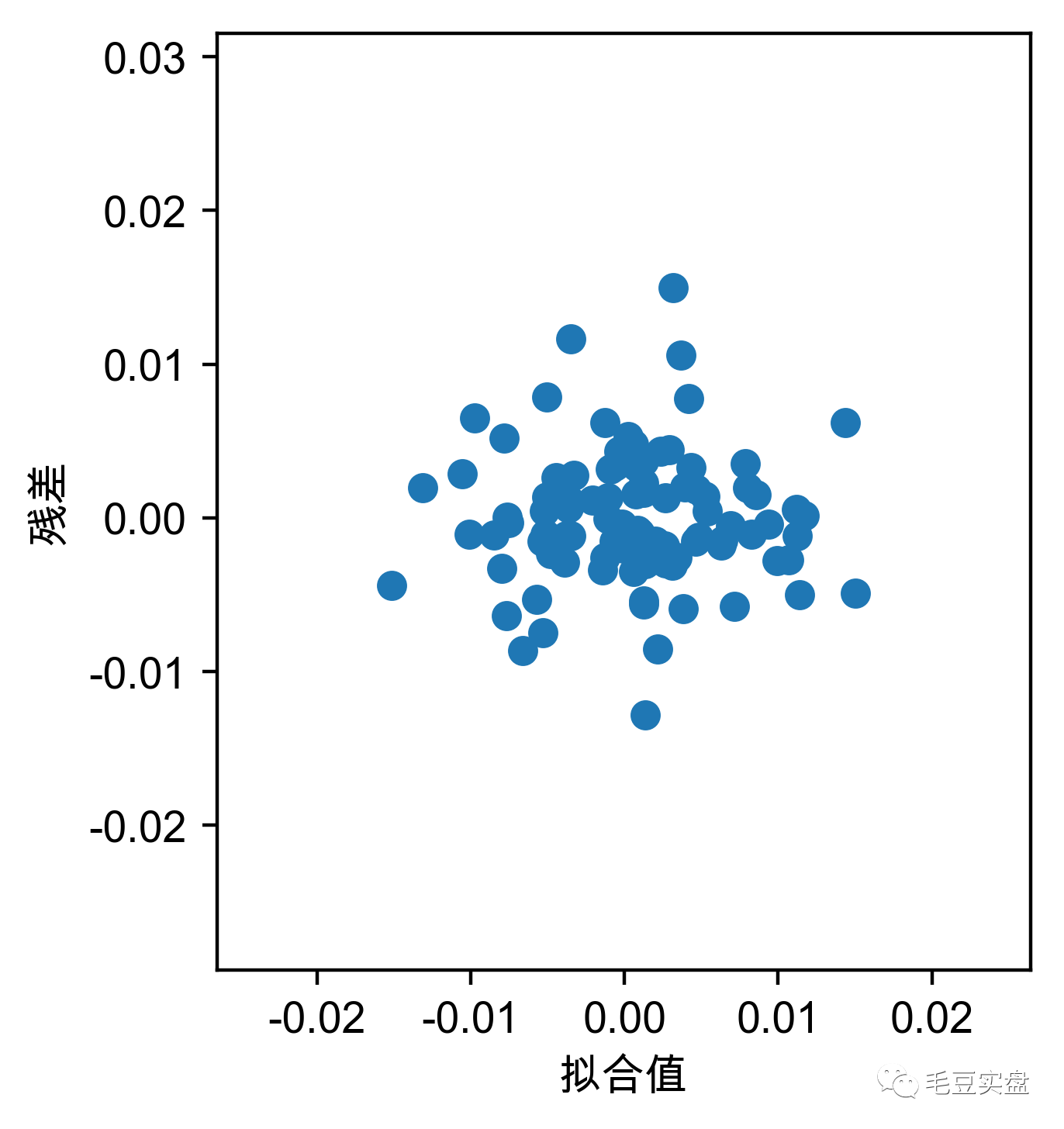
残差是因变量未被自变量解释的部分,若满足线性假设,残差和拟合值直接应该不存在任何趋势性的关系,散点沿y=0两侧分布。
绘制正态Q-Q图:
sm.qqplot(model.resid_pearson,stats.norm,line='45')
plt.gca().set_aspect(1)
plt.savefig('fig2.png',dpi=400,bbox_inches='tight')返回如下:
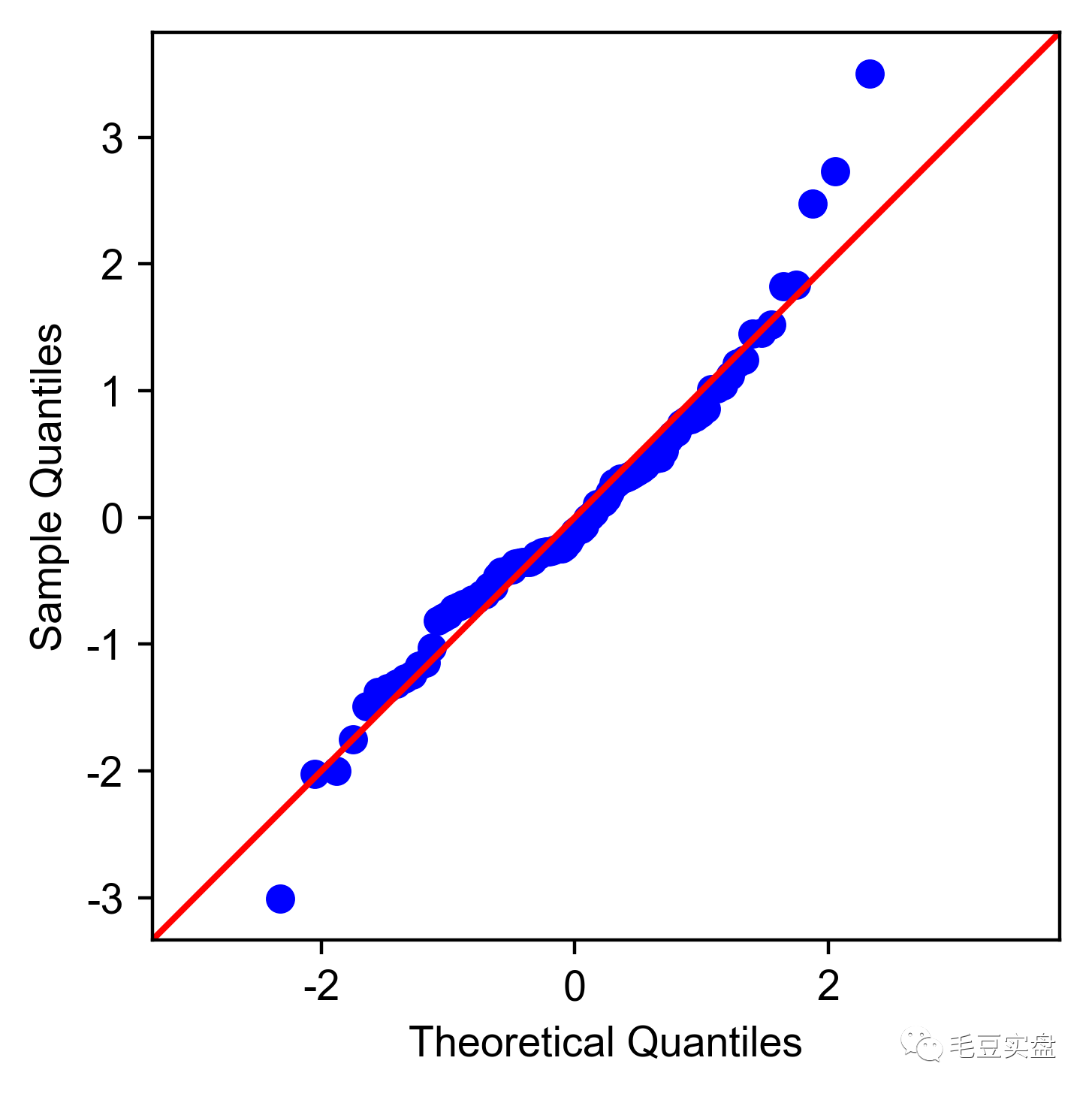
Q-Q图可以检验数据序列是否满足某种概率分布,它将对应分布的概率分位数作为横坐标,数据序列的分位数作为纵坐标作成散点图,若该数据序列满足该概率分布,则散点的趋势应该与某条直线基本重合。正态Q-Q图检验的是标准化残差是否服从N(0,1)。
以上是今天的全部干货内容,毛豆会在每周末更新这个系列,也会在每个交易日继续和大家分享旋风冲锋量化策略的实盘情况,欢迎大家点赞关注。