hello,我是毛豆。本系列用最精简的代码和案例带你快速入门量化,只讲最干的干货,想要学习量化又不知道该如何上手的小伙伴赶紧看过来!
前期回顾:
本期内容将介绍如何用python做相关性分析。Pearson相关系数用于度量两个变量的线性相关性,介于-1到1之间。该值越接近于1,代表两个变量的正相关性越强;该值越接近于-1,代表两个变量的负相关性越强。其计算方式为协方差与标准差之商:

下面我们来看看具体如何用python实现指数、个股、行业之间的相关性分析。毛豆在每周末都会更新这个系列,建议大家收藏起来方便学习。
一、指数相关性分析
首先导入相关的包,并认证Tushare Pro账号。
import tushare as ts
import numpy as np
import matplotlib.pyplot as plt
pro = ts.pro_api('your token')获取今年以来的上证指数数据,并计算收益率:
df1=ts.get_k_data('sh',start='2023-01-01',end='2023-06-02')#上证指数
df1['lagclose']=df1.close.shift(1)
df1['SHRet']=(df1['close']-df1['lagclose'])/df1['lagclose']
df1.tail()返回如下:

获取今年以来的深圳成指数据,并计算收益率:
df2=ts.get_k_data('sz',start='2023-01-01',end='2023-06-02')#深证成指
df2['lagclose']=df2.close.shift(1)
df2['SZRet']=(df2['close']-df2['lagclose'])/df2['lagclose']
df2.tail()返回如下:
核查两个变量是否存在缺失值、长度是否相等:
SHRet=df1.SHRet.dropna()
SZRet=df2.SHRet.dropna()
print(len(SHRet),len(SZRet))使用corr函数计算两个变量的相关系数:
SHRet.corr(SZRet)绘制散点图:
#解决中文乱码
plt.rcParams['font.sans-serif']=['Arial Unicode MS']#用于mac
#plt.rcParams['font.sans-serif']=['SimHei']#用于windows
plt.rcParams['axes.unicode_minus'] = False
#绘制上证综指与深证综指收益率的散点图
plt.figure(figsize=(10,6))
plt.scatter(SHRet,SZRet,s=50,c="m",norm = 0.5, alpha =0.4, linewidths =0)
plt.title('上证综指与深证成指收益率相关系数:{}'.format(SHRet.corr(SZRet)))
plt.xlabel('上证综指收益率')
plt.ylabel('深证成指收益率')
plt.grid(visible=True,axis="both")
plt.savefig('fig1.png',dpi=400,bbox_inches='tight')返回如下:
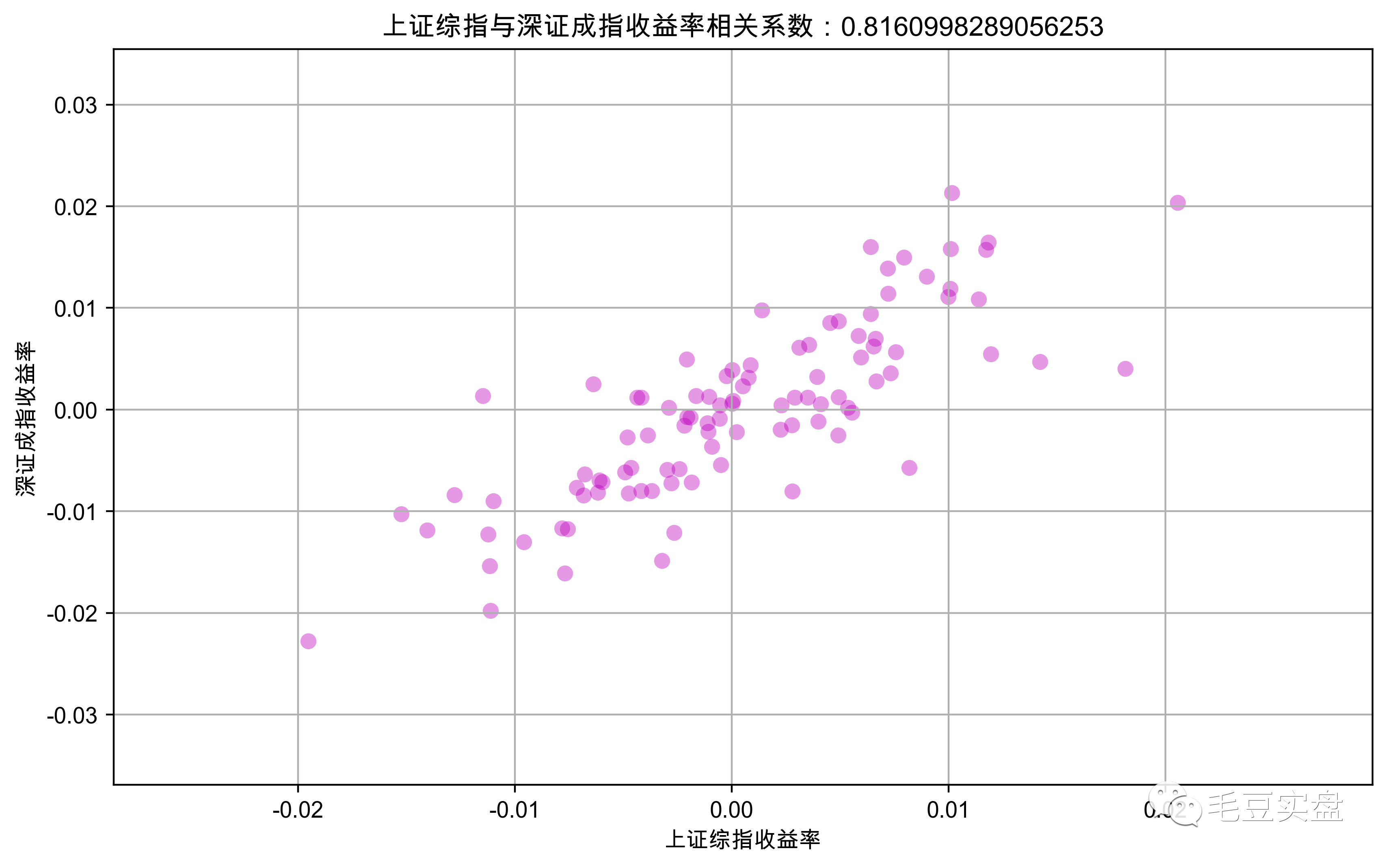
散点沿对角线分布,相关系数达到0.816,上证指数和深圳成指收益率之间呈现显著的正相关性。
二、个股相关性分析
个股相关性分析方法与指数相同。我们以宣亚国际、中文在线、世纪天鸿这3只个股为例,分析其两两之间的收益率相关性。
获取这3只个股近一个月的数据,并计算收益率:
#宣亚国际
df3 = pro.daily(ts_code='300612.SZ', start_date='20230502', end_date='20230602')
df3['lagclose']=df3['close'].shift(-1)
df3['Ret1']=(df3['close']-df3['lagclose'])/df3['lagclose']
#中文在线
df4 = pro.daily(ts_code='300364.SZ', start_date='20230502', end_date='20230602')
df4['lagclose']=df4['close'].shift(-1)
df4['Ret2']=(df4['close']-df4['lagclose'])/df4['lagclose']
#世纪天鸿
df5 = pro.daily(ts_code='300654.SZ', start_date='20230502', end_date='20230602')
df5['lagclose']=df5['close'].shift(-1)
df5['Ret3']=(df5['close']-df5['lagclose'])/df5['lagclose']核查变量是否存在缺失值、长度是否相等:
Ret1=df3.Ret1.dropna()
Ret2=df4.Ret2.dropna()
Ret3=df5.Ret3.dropna()
print(len(Ret1),len(Ret2),len(Ret3))计算两两之间的相关系数:
print('宣亚国际与中文在线收益率相关系数:{}'.format(Ret1.corr(Ret2)))
print('宣亚国际与世纪天鸿收益率相关系数:{}'.format(Ret1.corr(Ret3)))
print('中文在线与世纪天鸿收益率相关系数:{}'.format(Ret2.corr(Ret3)))打印如下:

绘制散点图:
#解决中文乱码
plt.rcParams['font.sans-serif']=['Arial Unicode MS']#用于mac
#plt.rcParams['font.sans-serif']=['SimHei']#用于windows
plt.rcParams['axes.unicode_minus'] = False
#绘制散点图
plt.figure(figsize=(6,12))
plt.subplots_adjust(hspace=0.45)
ax=plt.subplot(3,1,1)
plt.scatter(Ret1,Ret2,s=50,c="r",norm = 0.5, alpha =0.4, linewidths =0)
plt.title('宣亚国际与中文在线收益率的散点图')
plt.xlabel('宣亚国际收益率')
plt.ylabel('中文在线收益率')
plt.grid(visible=True,axis="both")
ax=plt.subplot(3,1,2)
plt.scatter(Ret1,Ret3,s=50,c="b",norm = 0.5, alpha =0.4, linewidths =0)
plt.title('宣亚国际与世纪天鸿收益率的散点图')
plt.xlabel('宣亚国际收益率')
plt.ylabel('世纪天鸿收益率')
plt.grid(visible=True,axis="both")
ax=plt.subplot(3,1,3)
plt.scatter(Ret2,Ret3,s=50,c="g",norm = 0.5, alpha =0.4, linewidths =0)
plt.title('中文在线与世纪天鸿收益率的散点图')
plt.xlabel('中文在线收益率')
plt.ylabel('世纪天鸿收益率')
plt.grid(visible=True,axis="both")
plt.savefig('fig2.png',dpi=400,bbox_inches='tight')返回如下:
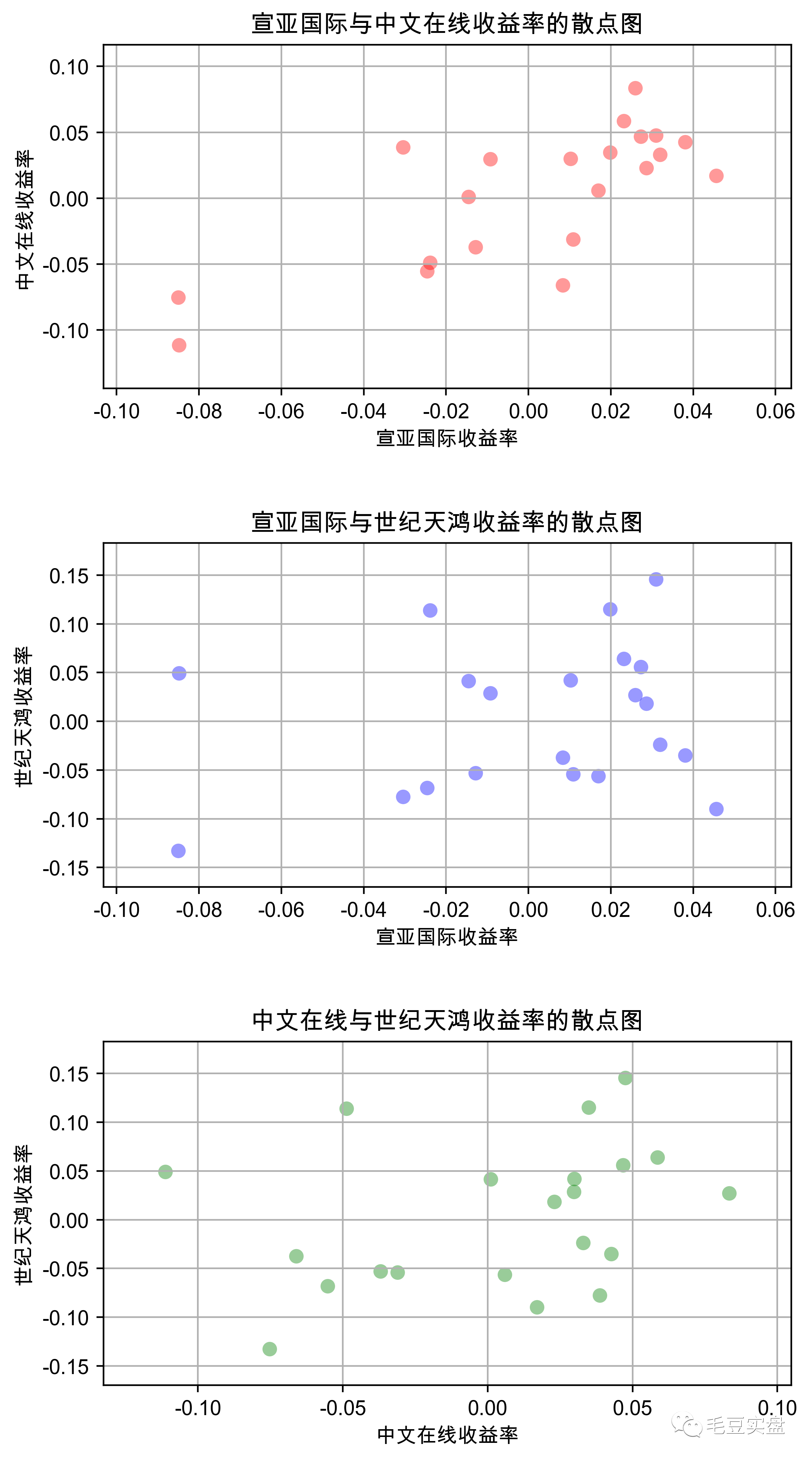
这三只股虽然同属于传媒板块,但不难看出,宣亚国际和中文在线这两只股之间存在较强的线性相关性,而宣亚国际与世纪天鸿、中文在线与世纪天鸿之间没有明显的相关性。
以此类推,我们可以计算出市场中全部个股两两之间的相关性,并构建相关系数矩阵。计算方法与上述方法相同,这里就不展示代码了。
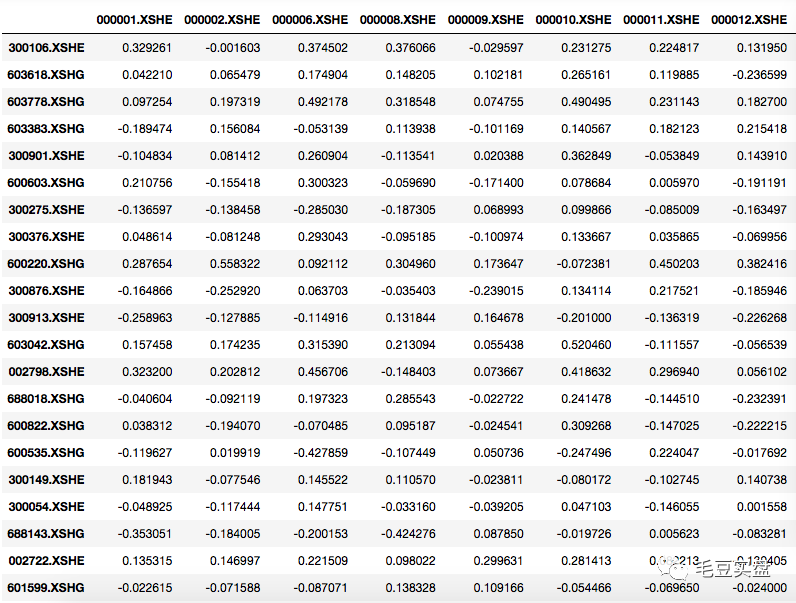
查看相关性较高的一对个股(部分展示):

经验上来说同板块的个股相关性会比较强,但这并不是绝对的,通过相关性分析我们不仅可以挖掘到更多强相关的个股,也可以排除掉同板块内不相关的个股。具有强相关性的个股表现为同涨同跌,且涨跌幅呈现出线性相关性,可以作为个股间关联性套利的重要参考。
三、行业相关性分析
除了对个股间做相关性分析,我们也可以对行业板块、概念板块做相关性分析,来挖掘具有强相关性的行业,进而构建行业网络模型:

这里不做代码展示,感兴趣的朋友可以查看我前面的帖子:量化研究分享:如何构建行业网络模型
以上是今天的全部干货内容,毛豆会在每周末更新这个系列,也会在每个交易日继续和大家分享旋风冲锋量化策略的实盘情况,欢迎大家点赞关注。