文章目录
前言
大家好,我是陪你们一起在研途中共勉的小曾哥,也许很多人会有疑惑,为什么我的这个博客的内容覆盖面也是非常广的,有多目标进化的、有大规模稀疏的文章【相信有一大部分人是看到多目标优化而关注我的】、有智慧教育、主动学习的文章,现在又要继续学习强化学习,并不是在一个领域内继续探索研究。
答案也很简单,学无止境,学海无涯,当你需要解决目前所遇到的问题时,那就必须拓宽知识面,用所学的方法来解决你的问题。也正如下图中,我们会阅读到更多的学术论文,来继续不断的加深对自己领域的领悟!
什么是强化学习?
百度百科:强化学习(Reinforcement Learning, RL),又称再励学习、评价学习或增强学习,是机器学习的范式和方法论之一,用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题。

理解版本:强化学习是一类算法,是让计算机实现从一开始完全随机的进行操作,通过不断地尝试,从错误中学习,最后找到规律,学会了达到目的的方法。这就是一个完整的强化学习过程。让计算机在不断的尝试中更新自己的行为,从而一步步学习如何操自己的行为得到高分。
强化学习基本元素
强化学习第一层结构:基本元素
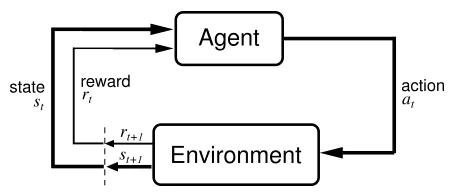
Agent----与环境进行互动的主体(可以认为是玩家)
Environment----环境
Goal----目标
强化学习过程:是玩家在与环境的互动中为了达成一个目标而学习的过程
环境是什么?目标又是什么?
强化学习的第二层结构:主要元素
State----状态
Action----在一个状态下,玩家需要做出某种行动,叫做Action
Reward----Agent在一个状态之下采取了特定的行动之后所得到的即时的反馈
举个例子----围棋
1、围棋的状态比较简单,就是棋盘上的361个落子点多状态整体,对于每个落子点来说可以有三种状态:黑棋、白棋、空 ;那么整个围棋的状态就是3的361次方
2、在围棋中,黑棋先手,在当前状态是棋盘中没有落子,因此黑棋就有361种可能的行动,可以在任何一个位置进行落子。
3、当在棋盘中放置黑子后,那么目前的棋盘状态就已经发生改变,因此就在下一个状态的情况下,开始进行白棋落子,这样状态和动作的往复就构成了强化学习的主体部分
4、在围棋中,玩家的目标是赢得棋局,只有在达到赢棋的状态时才有一个大于0的奖励,可以认为赢棋的奖励为1,输棋或者和棋设置的奖励为0【奖励由最终的目标所决定的】
强化学习的第三层结构:核心元素
Policy----策略,在数学中可以是一个函数,输入某种状态,那么输出的就是一个行动
Value----价值,同样也是一个函数,策略函数就取决于价值函数
策略:在围棋中,将当前的棋盘的状态告诉这个策略函数,那么就会告诉你下一步应该在下在哪个位置,强化学习想达到的最终效果,就是一个好的策略
价值主要包括State Value 状态价值函数,输入状态,输出状态的价值(预期将来得到的所有奖励之和)
强化学习的分类:
通过价值选择行为:Q learning Sarsa Deep Q Network
直接选择行为: Policy Gradients 基于概率 --回合更新版
想象环境并从中学习:Model based RL
场景应用分类
1、是否理解环境?
不理解环境:不尝试去理解环境,环境给什么就是什么
理解环境:为真实世界建模
Model-based 就是在model free的基础上多一个虚拟环境
2 基于概率与基于价值
基于概率:直接输出下一步要采取动作的概率,根据概率选取行动,可以支持连续动作
基于价值:而基于价值的方法输出则是所有动作的价值, 根据最高价值来选着动作
基于价值的谁价值高选谁,基于概率根据概率执行动作
3、更新
回合更新:回合结束后更新行为准则
单步更新:每一步都更新准则
4、在线与否?
在线学习 边玩边学,sarsa、sarsa(lambda)
离线学习 学完再玩,Q Learning、Deep Q Network
经典强化学习算法
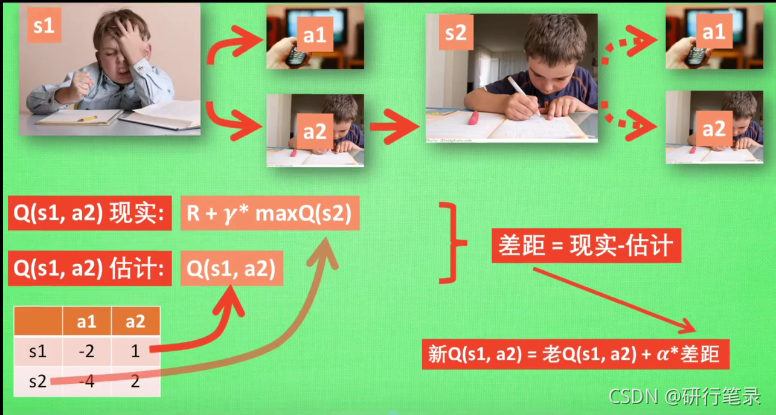
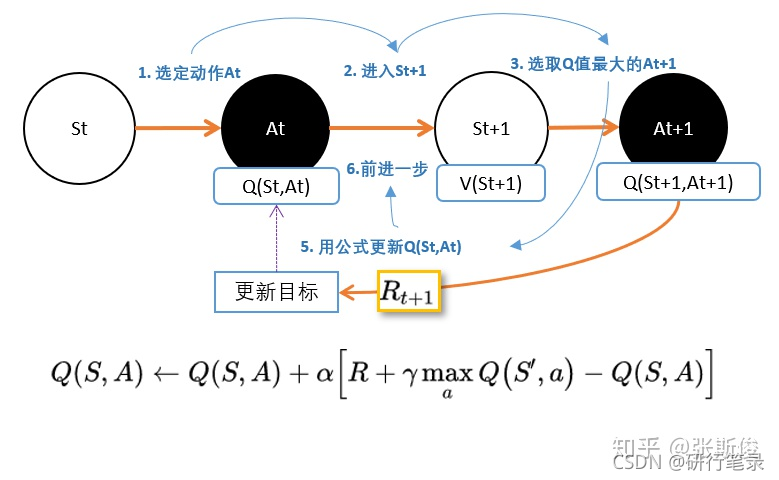
Q learning (说到不一定做到 Off policy)
算法伪代码

Sarsa 算法(说到做到型–On policy)

DQN
Deep Q Network 的简称叫 DQN, 是将 Q learning 的优势 和 Neural networks 结合了. 如果我们使用 tabular Q learning, 对于每一个 state, action 我们都需要存放在一张 q_table 的表中. 如果像显示生活中, 情况可就比那个迷宫的状况复杂多了, 我们有千千万万个 state, 如果将这千万个 state 的值都放在表中, 受限于我们计算机硬件, 这样从表中获取数据, 更新数据是没有效率的. 这就是 DQN 产生的原因了. 我们可以使用神经网络来 估算 这个 state 的值, 这样就不需要一张表了.
Q learning 表格数据较多
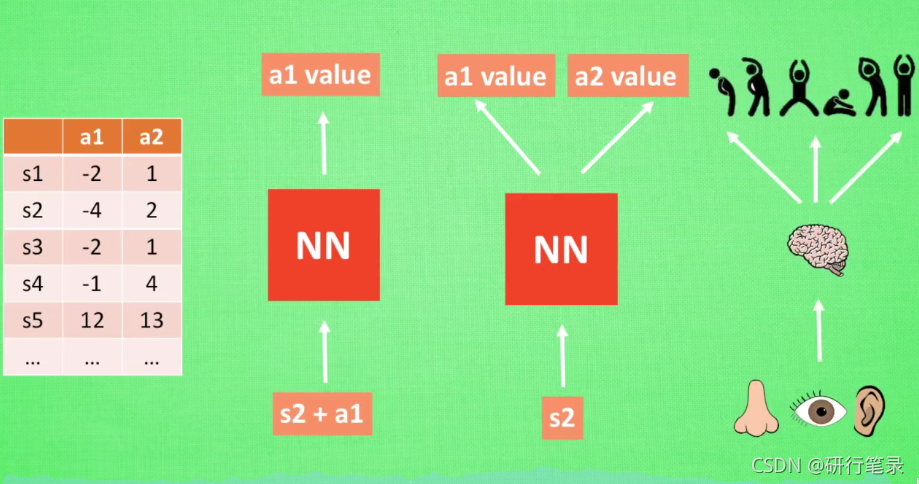
我们使用表格来存储每一个状态 state, 和在这个 state 每个行为 action 所拥有的 Q 值. 而当今问题是在太复杂, 状态可以多到比天上的星星还多(比如下围棋). 如果全用表格来存储它们, 恐怕我们的计算机有再大的内存都不够, 而且每次在这么大的表格中搜索对应的状态也是一件很耗时的事。
在机器学习中, 有一种方法对这种事情很在行, 那就是神经网络. 我们可以将状态和动作当成神经网络的输入, 然后经过神经网络分析后得到动作的 Q 值, 这样我们就没必要在表格中记录 Q 值, 而是直接使用神经网络生成 Q 值. 还有一种形式的是这样, 我们也能只输入状态值, 输出所有的动作值, 然后按照 Q learning 的原则, 直接选择拥有最大值的动作当做下一步要做的动作. 我们可以想象, 神经网络接受外部的信息, 相当于眼睛鼻子耳朵收集信息, 然后通过大脑加工输出每种动作的值, 最后通过强化学习的方式选择动作。
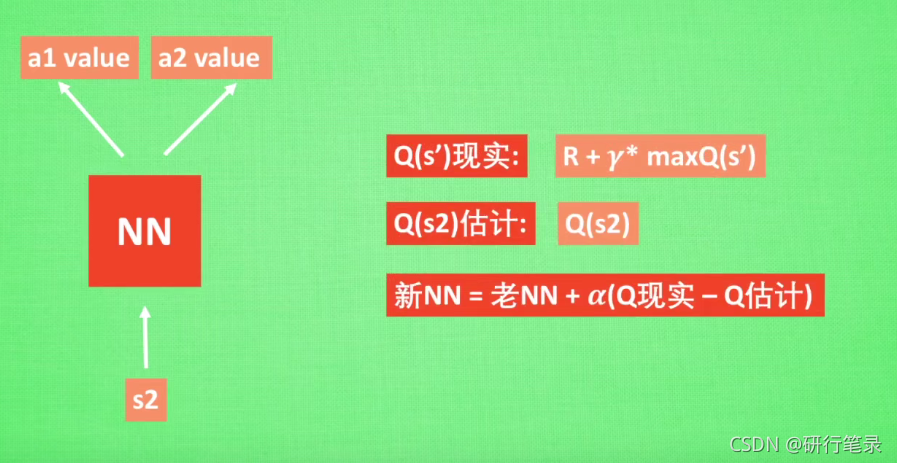
打乱记忆相关性的方法 Experience replay Fixed Q-targets

算法

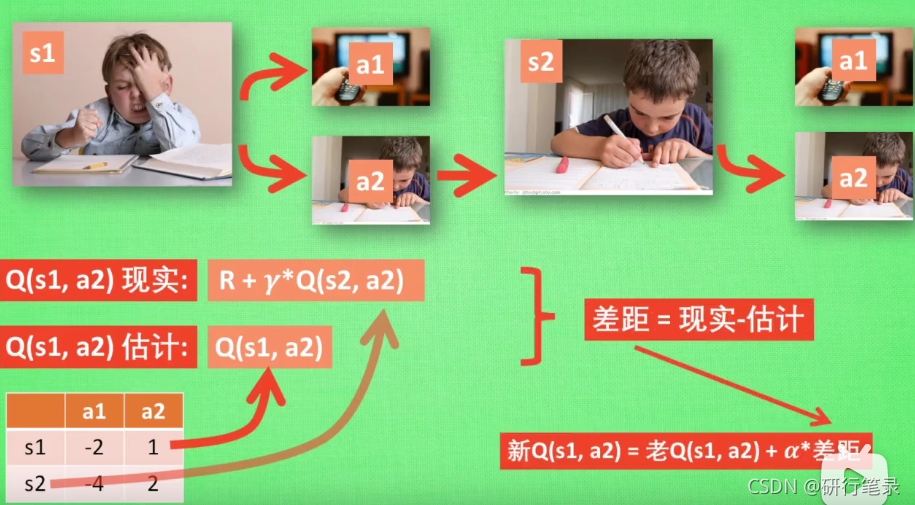
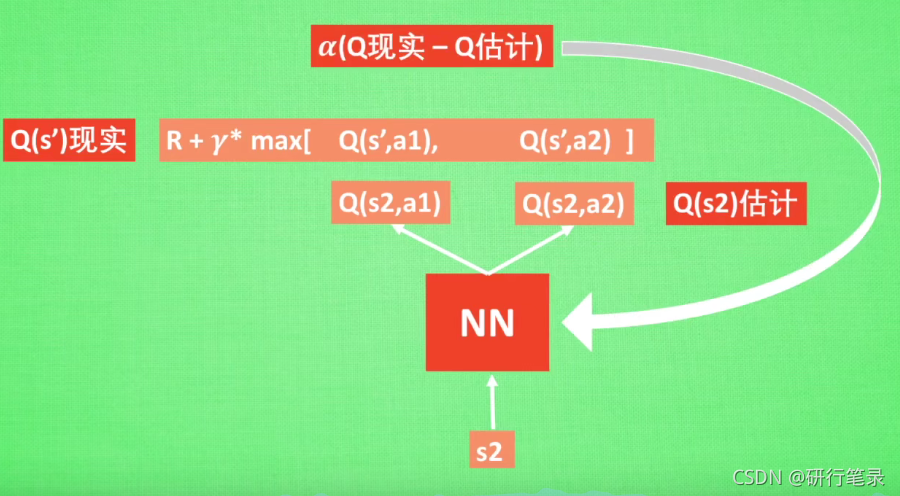
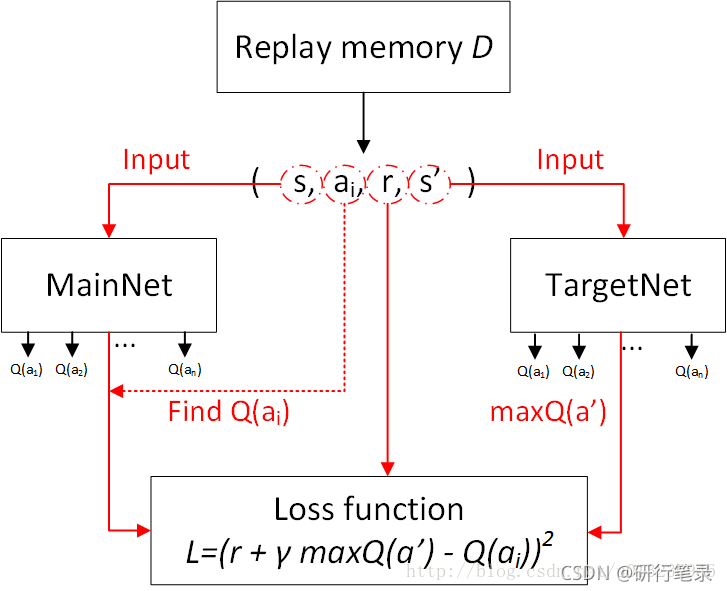
DQN中存在两个结构完全相同但是参数却不同的网络,预测Q估计的网络MainNet使用的是最新的参数,而预测Q现实的神经网络TargetNet参数使用的却是很久之前的,Q ( s , a ; θ i ) Q(s,a;θ_i)Q(s,a;θi)表示当前网络MainNet的输出,用来评估当前状态动作对的值函数;Q ( s , a ; θ i − ) Q(s,a;θ^−_i)Q(s,a;θi−) 表示TargetNet的输出,可以解出targetQ,因此当agent对环境采取动作a时就可以根据上述公式计算出Q并根据LossFunction更新MainNet的参数,每经过一定次数的迭代,将MainNet的参数复制给TargetNet。
Policy Gradients
什么是 Policy Gradients?

强化学习是一个通过奖惩来学习正确行为的机制. 家族中有很多种不一样的成员, 有学习奖惩值, 根据自己认为的高价值选行为, 比如 Q learning, Deep Q Network, 也有不通过分析奖励值, 直接输出行为的方法, 这就是今天要说的 Policy Gradients 了. 甚至我们可以为 Policy Gradients 加上一个神经网络来输出预测的动作. 对比起以值为基础的方法, Policy Gradients 直接输出动作的最大好处就是, 它能在一个连续区间内挑选动作, 而基于值的, 比如 Q-learning, 它如果在无穷多的动作中计算价值, 从而选择行为, 这, 它可吃不消.
更新不同之处
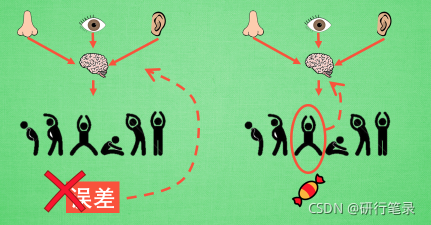
有了神经网络当然方便, 但是, 我们怎么进行神经网络的误差反向传递呢? Policy Gradients 的误差又是什么呢? 答案是! 哈哈, 没有误差! 但是他的确是在进行某一种的反向传递. 这种反向传递的目的是让这次被选中的行为更有可能在下次发生. 但是我们要怎么确定这个行为是不是应当被增加被选的概率呢? 这时候我们的老朋友, reward 奖惩正可以在这时候派上用场,
具体更新步骤
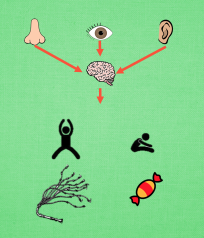
观测的信息通过神经网络分析, 选出了左边的行为, 我们直接进行反向传递, 使之下次被选的可能性增加, 但是奖惩信息却告诉我们, 这次的行为是不好的, 那我们的动作可能性增加的幅度 随之被减低. 这样就能靠奖励来左右我们的神经网络反向传递. 我们再来举个例子, 假如这次的观测信息让神经网络选择了右边的行为, 右边的行为随之想要进行反向传递, 使右边的行为下次被多选一点, 这时, 奖惩信息也来了, 告诉我们这是好行为, 那我们就在这次反向传递的时候加大力度, 让它下次被多选的幅度更猛烈!
这就是 Policy Gradients 的核心思想了.
我们从某个state出发,然后一直走,直到最终状态。然后我们从最终状态原路返回,对每个状态评估G值。
所以G值能够表示在策略 下,智能体选择的这条路径的好坏。
Actor Critic
什么是 Actor Critic?
强化学习中的一种结合体 Actor Critic (演员评判家), 它合并了以值为基础 (比如 Q learning) 和以动作概率为基础 (比如 Policy Gradients) 两类强化学习算法.
为什么要有 Actor 和 Critic?
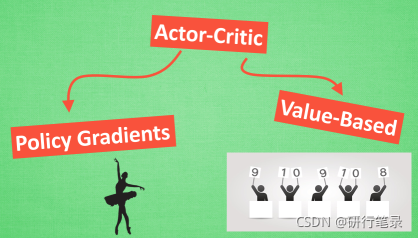
原来 Actor-Critic 的 Actor 的前生是 Policy Gradients, 这能让它毫不费力地在连续动作中选取合适的动作, 而 Q-learning 做这件事会瘫痪. 那为什么不直接用 Policy Gradients 呢? 原来 Actor Critic 中的 Critic 的前生是 Q-learning 或者其他的 以值为基础的学习法 , 能进行单步更新, 而传统的 Policy Gradients 则是回合更新, 这降低了学习效率.

Actor 和 Critic, 他们都能用不同的神经网络来代替 . 在 Policy Gradients 的影片中提到过, 现实中的奖惩会左右 Actor 的更新情况. Policy Gradients 也是靠着这个来获取适宜的更新. 那么何时会有奖惩这种信息能不能被学习呢? 这看起来不就是 以值为基础的强化学习方法做过的事吗. 那我们就拿一个 Critic 去学习这些奖惩机制, 学习完了以后. 由 Actor 来指手画脚, 由 Critic 来告诉 Actor 你的那些指手画脚哪些指得好, 哪些指得差, Critic 通过学习环境和奖励之间的关系, 能看到现在所处状态的潜在奖励, 所以用它来指点 Actor 便能使 Actor 每一步都在更新, 如果使用单纯的 Policy Gradients, Actor 只能等到回合结束才能开始更新.
缺点:Actor-Critic 涉及到了两个神经网络, 而且每次都是在连续状态中更新参数, 每次参数更新前后都存在相关性, 导致神经网络只能片面的看待问题, 甚至导致神经网络学不到东西.
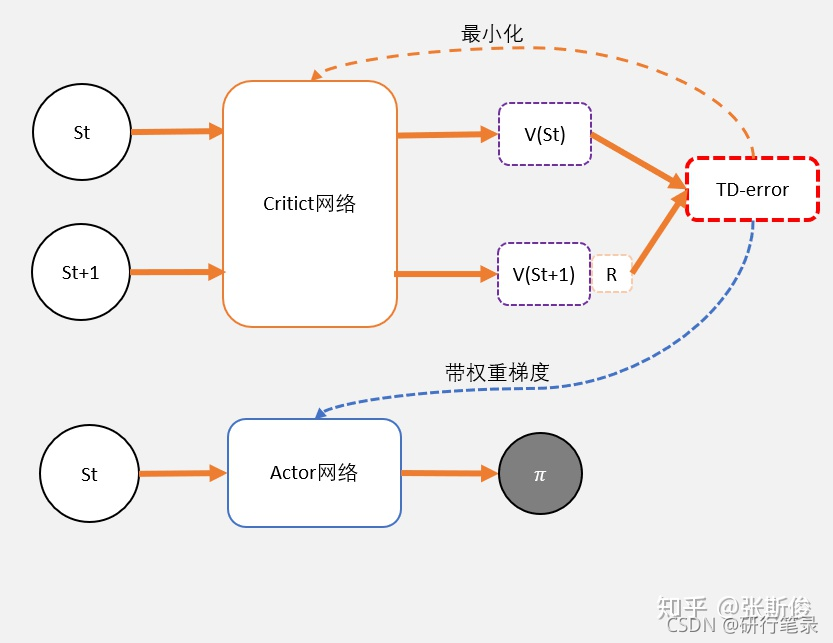
TD-error
在DQN预估的是Q值,在AC中的Critic,估算的是V值。
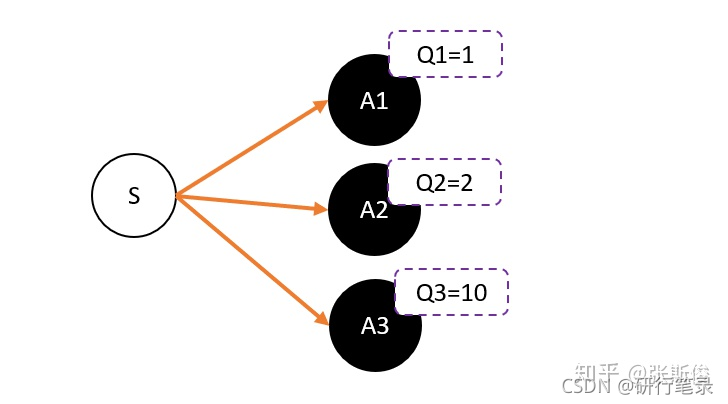
Q值的期望(均值)就是V
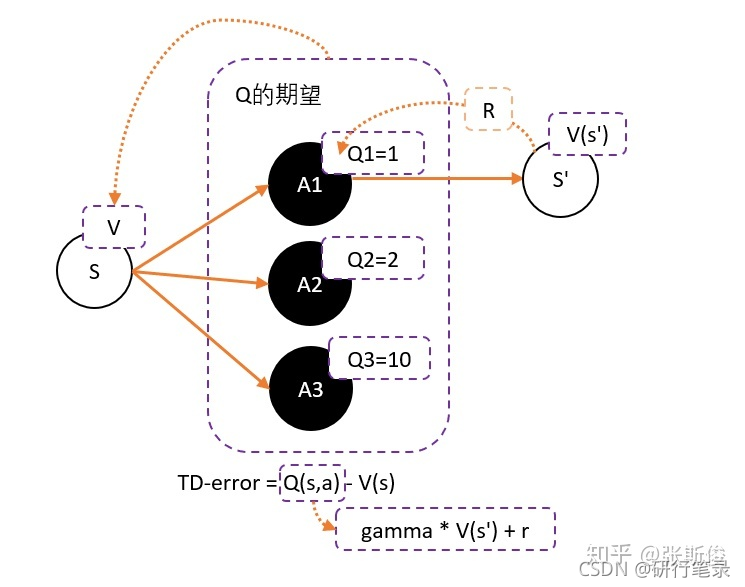
Critic的任务就是让TD-error尽量小。然后TD-error给Actor做更新
现在我们再总结一下TD-error的知识:
-
为了避免正数陷阱,我们希望Actor的更新权重有正有负。因此,我们把Q值减去他们的均值V。有:Q(s,a)-V(s)
-
为了避免需要预估V值和Q值,我们希望把Q和V统一;由于Q(s,a) = gamma * V(s’) + r - V(s)。所以我们得到TD-error公式: TD-error = gamma * V(s’) + r - V(s)
-
TD-error就是Actor更新策略时候,带权重更新中的权重值;
-
现在Critic不再需要预估Q,而是预估V。而根据马可洛夫链所学,我们知道TD-error就是Critic网络需要的loss,也就是说,Critic函数需要最小化TD-error。
AC 流程
1、定义两个network:Actor 和 Critic
2、j进行N次更新。
从状态s开始,执行动作a,得到奖励r,进入状态s’记录的数据。
把s’输入到Critic,根据公式: TD-error = gamma * V(s’) + r - V(s) 求 TD-error,并缩小TD-error
把TD-error输入到Actor,计算策略分布 。
DQN
DDPG
Critic
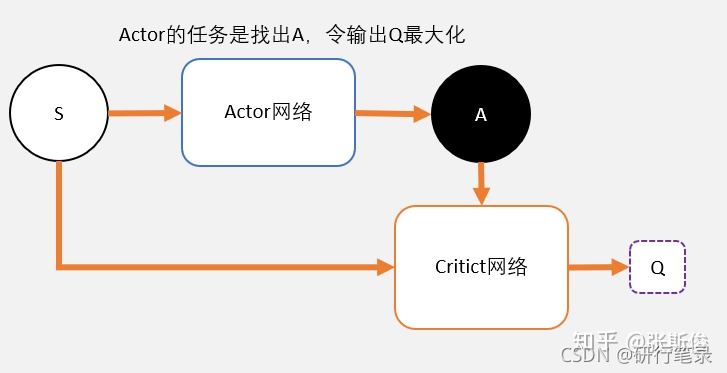
Critic网络的作用是预估Q,虽然它还叫Critic,但和AC中的Critic不一样,这里预估的是Q不是V;
注意Critic的输入有两个:动作和状态,需要一起输入到Critic中;
Critic网络的loss其还是和AC一样,用的是TD-error。这里就不详细说明了,我详细大家学习了那么久,也知道为什么了。
Actor
和AC不同,Actor输出的是一个动作;
Actor的功能是,输出一个动作A,这个动作A输入到Crititc后,能够获得最大的Q值。
所以Actor的更新方式和AC不同,不是用带权重梯度更新,而是用梯度上升。
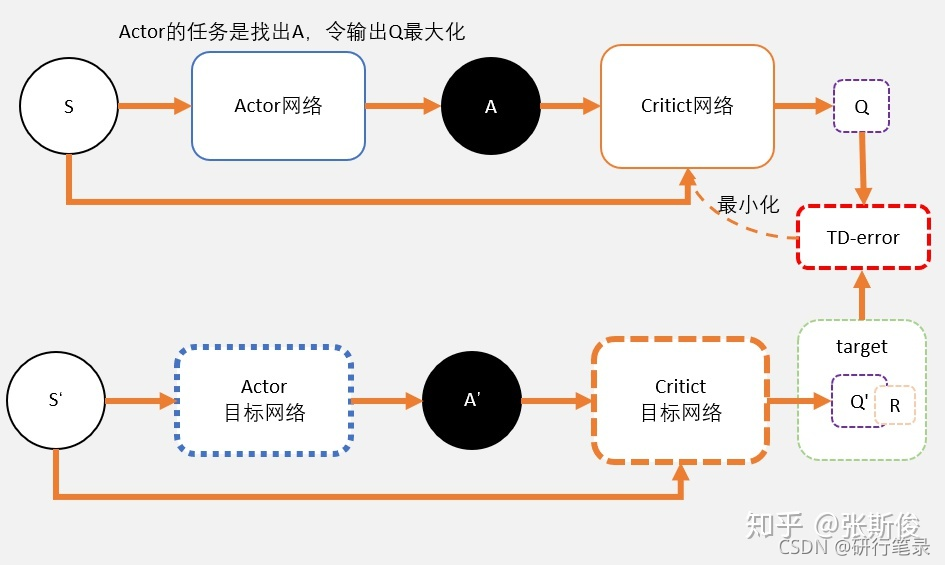
跟DQN一样,更新的时候如果更新目标在不断变动,会造成更新困难。所以DDPG和DQN一样,用了固定网络(fix network)技术,就是先冻结住用来求target的网络。在更新之后,再把参数赋值到target网络。
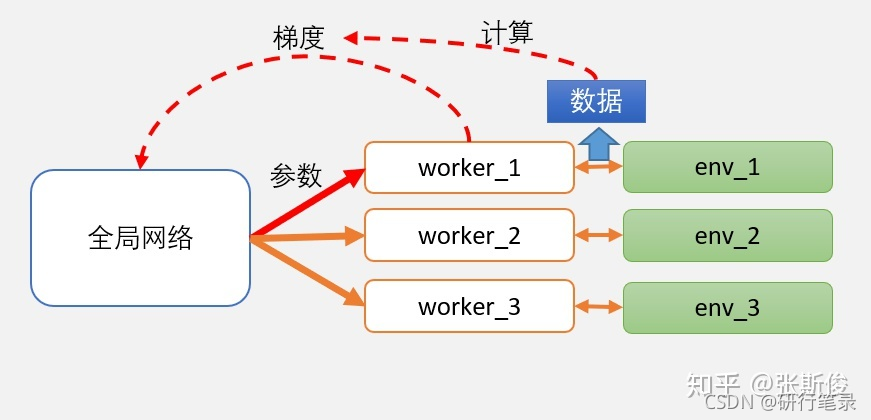
A3C
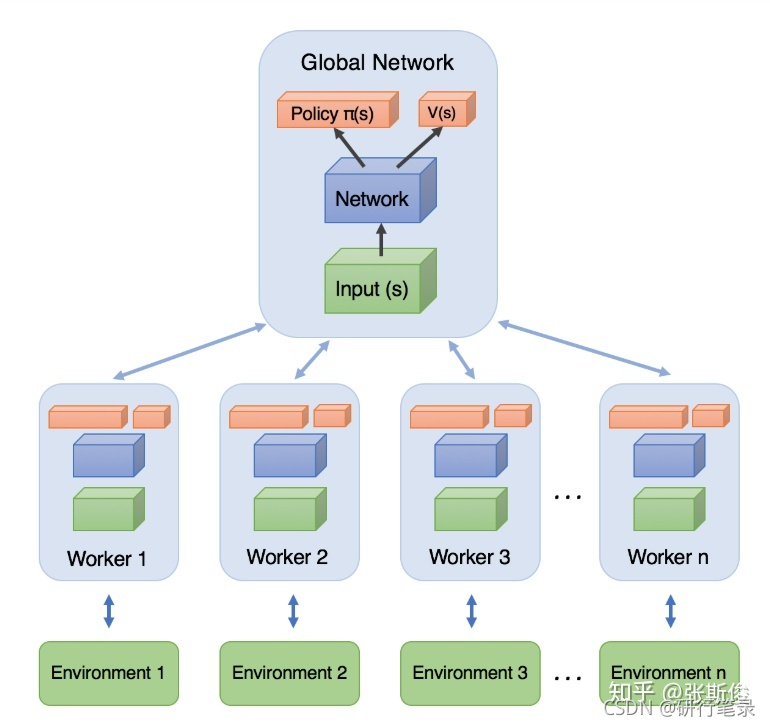
架构图分为两个主要部分:Global Network(全局网络)和 worker(工人)
worker向全局网络汇总梯度之后,并应用在全局网络的参数后,全局网络会把当前学习到的最新版本的参数,直接给worker。
worker按照最新的网络继续跟环境做互动。互动后,再把梯度提交,获取新的参数… 如此循环。