1. hive是由Facebook实现并开源的
解决mapreduce编写复杂和学习程度高的问题。
2. hive是hadoop的数据仓库工具
hive是将存储在HDFS上的结构化数据映射为一张二维表格,编写sql语句来统计分析。
结构化数据:csv、tsv
半结构化数据:图片格式、音频格式、视频格式
非结构化数据:html、xml
用一张图来解释:
把存储在HDFS上的结构化数据,通过Hive的sql语句创建数据库表映射为一张二维表格,然后可以写sql语句进行查询分析。

3. hive存储的数据其实底层是存储在HDFS上
hive本身不存储数据,数据都是存储在HDFS上。
4.hive将HDFS上存储的结构化数据映射成一张二维库表/二维结构
为什么hive提供的是sql的select语法?
因为mysql的表就是一种二维结构,然后我们可以使用sql来操作
针对结构化的数据,其实都可以使用sql的查询分析语句select来进行表达
5.hive提供HQL(hive query language)查询功能
语法和SQL语法有区别,但是大致一样。
6.hive的本质是将sql语句转化为mapreduce任务运行,使不熟悉mapreduce的用户能够通过HQL处理和计算HDFS上存储的结构化数据
hive的目的是为了减轻mapreduce的编码复杂问题,但是不是用来提升mapreduce运行效率低下的问题。
hive—》mapreduce 减轻编码压力
spark—》mapreduce提升执行效率
用hive写语句,用来转换成mapreduce或者spark程序
spark和mapreduce是同种类型的东西,都是分布式并行计算框架
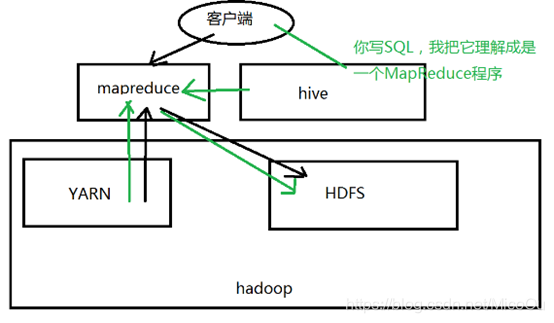
用一张图来解释:
客户端可以看作是我们常用的CRT,通过CRT客户端编写hive,将sql语句转化成mapreduce程序,处理和计算HDFS上存储的结构化数据,YARN集群调度资源执行mapreduce任务计算,最后将结果呈现返回给CRT客户端。