7.HDFS NameNode HA
7.1 NameNode HA概述
所谓HA(High Availablity [əˌveɪlə’bɪləti] ),即高可用(7x24小时服务不中断)。通过主备NameNode解决,如果主NameNode发生故障,则切换到备NameNode上,从而解决NameNode单点故障的问题。
- 实现高可用最关键的目的是消除单点故障。HA严格来说应该分成各个组件的HA机制:HDFS的HA和YARN的HA。
- Hadoop1.x在HDFS集群中NameNode存在单点故障;Hadoop2.0+可以通过NameNode HA解决单点故障的问题。
- Hadoop2.x中支持两个NameNode做HA,一个主,一个备。Hadoop3.x中支持两个或两个以上的NameNode做HA,一主一备,或一主多备。
- NameNode主要在以下两个方面影响HDFS集群
- NameNode机器发生意外,如宕机,集群将无法使用,直到管理员修复重启后。
- NameNode机器需要升级,包括软件、硬件升级,此时集群也将无法使用
- HDFS HA功能通过配置Active/Standby两个NameNodes实现在集群中对NameNode的热备来解决上述问题。如果出现故障,如机器崩溃或机器需要升级维护,这时可通过此种方式将NameNode很快的切换到另外一台机器。
7.2 自动NameNode HA概述
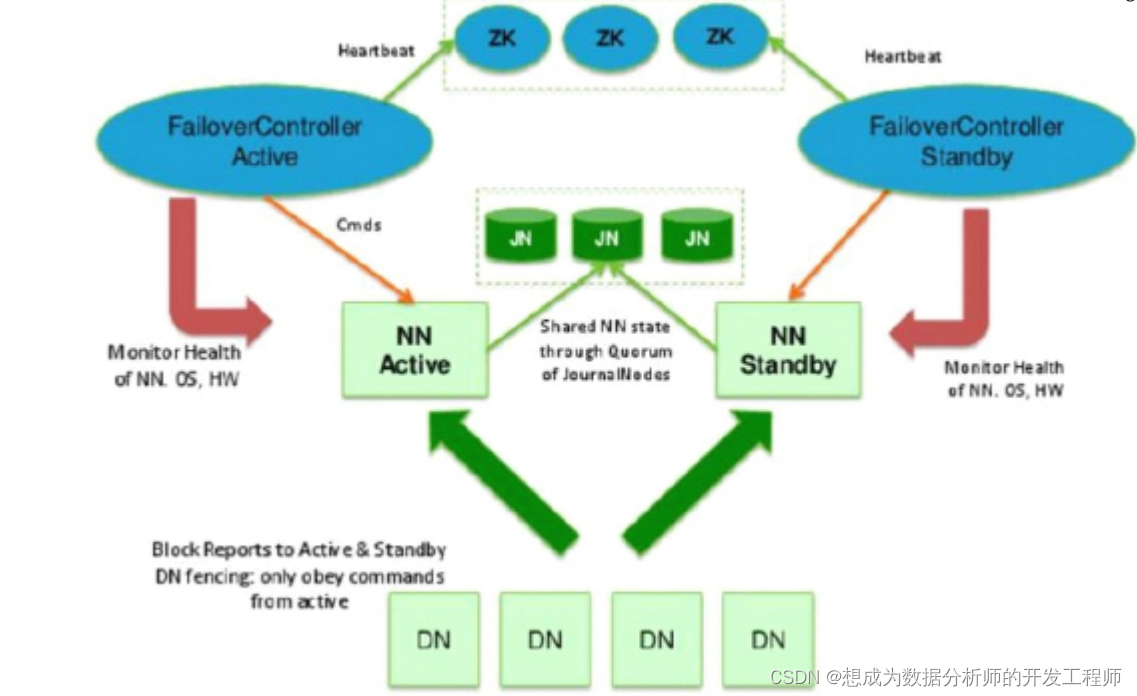
主备NameNode自动切换解决单点故障
- 主NameNode对外提供服务,备NameNode同步主NameNode元数据,以待切换
- 所有DataNode同时向两个NameNode汇报数据块信息(位置)
- JNN:集群(属性)同步edits log
- standby:备,完成了fsimage+edits.log文件的合并产生新的fsimage,推送回ANN
- 自动切换:基于Zookeeper自动切换方案
- ZooKeeper Failover Controller:监控NameNode健康状态,并向Zookeeper注册NameNode。NameNode挂掉后,ZKFC为NameNode竞争锁,获得ZKFC 锁的NameNode变为active
7.3NameNode自动HA 集群搭建
7.3.1 规划

- 切换快照到 “初始化”:
- 确认防火墙保持关闭状态(Linux阶段)
- 配置4台服务器彼此之间免密登录(Zookeeper阶段)
- 4台服务器上安装JDK,并配置环境变量(Linux阶段)
- node2-4,安装Zookeeper(Zookeeper阶段)
- ssh时不提示信息的配置
- 配置HDFS HA
- 切换快照到“format_pre"(NN格式化之前):
- ssh时不提示信息的配置
- 配置HDFS HA
- 不切换快照,在当前位置:
- 删除/var/itbaizhan/hadoop/full目录和/opt/hadoop3.1.3/logs目录下的全部内容
- ssh时不提示信息的配置
- 配置HDFS HA
7.3.2 ssh时不提示信息配置
后续需要编写HDFS HA集群的启动和关闭的Shell脚本,在Shell脚本中会涉及到 ssh nodeX 命令,将会出现提示fingerprint信息,比较烦人, 如何让ssh不提示fingerprint信息?
/etc/ssh/ssh_config(客户端配置文件) 区别于sshd_config(服务端配置文件)
[root@node0 ~]# vim /etc/ssh/ssh_config
#StrictHostKeyChecking ask
#找到上一行代码 改为下一行
StrictHostKeyChecking no
# 发送给其他虚拟机
[root@node0 ~]# scp /etc/ssh/ssh_config node1:/etc/ssh/
ssh_config 100% 2271 1.9MB/s 00:00
[root@node0 ~]# scp /etc/ssh/ssh_config node2:/etc/ssh/
ssh_config 100% 2271 2.0MB/s 00:00
[root@node0 ~]# scp /etc/ssh/ssh_config node3:/etc/ssh/
ssh_config 100% 2271 2.2MB/s 00:00
7.3.3 HDFS配置
关闭hdfs集群后,删除四台节点上/var/itbaizhan/hadoop/full目录和/opt/hadoop3.1.3/logs目录下的全部内容
rm -rf /var/itbaizhan/hadoop/full
rm -rf /opt/hadoop3.1.3/logs
以下一律在node0上操作,做完后scp到node1、node2、node3
- hadoop-env.sh配置JDK
[root@node0 ~]# cd /opt/hadoop-3.1.3/etc/hadoop/
[root@node0 hadoop]# vim hadoop-env.sh
# 添加图片中的代码

- 修改workers指定datanode的位置
[root@node0 hadoop]# pwd
/opt/hadoop-3.1.3/etc/hadoop
[root@node0 hadoop]# vim workers
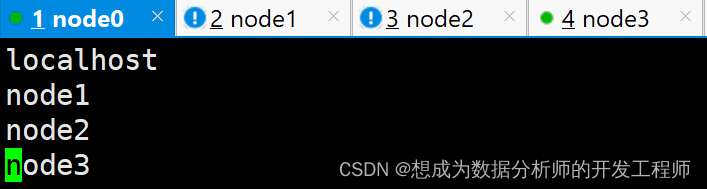
- 修改core-sit.xml
[root@node0 hadoop]# pwd
/opt/hadoop-3.1.3/etc/hadoop
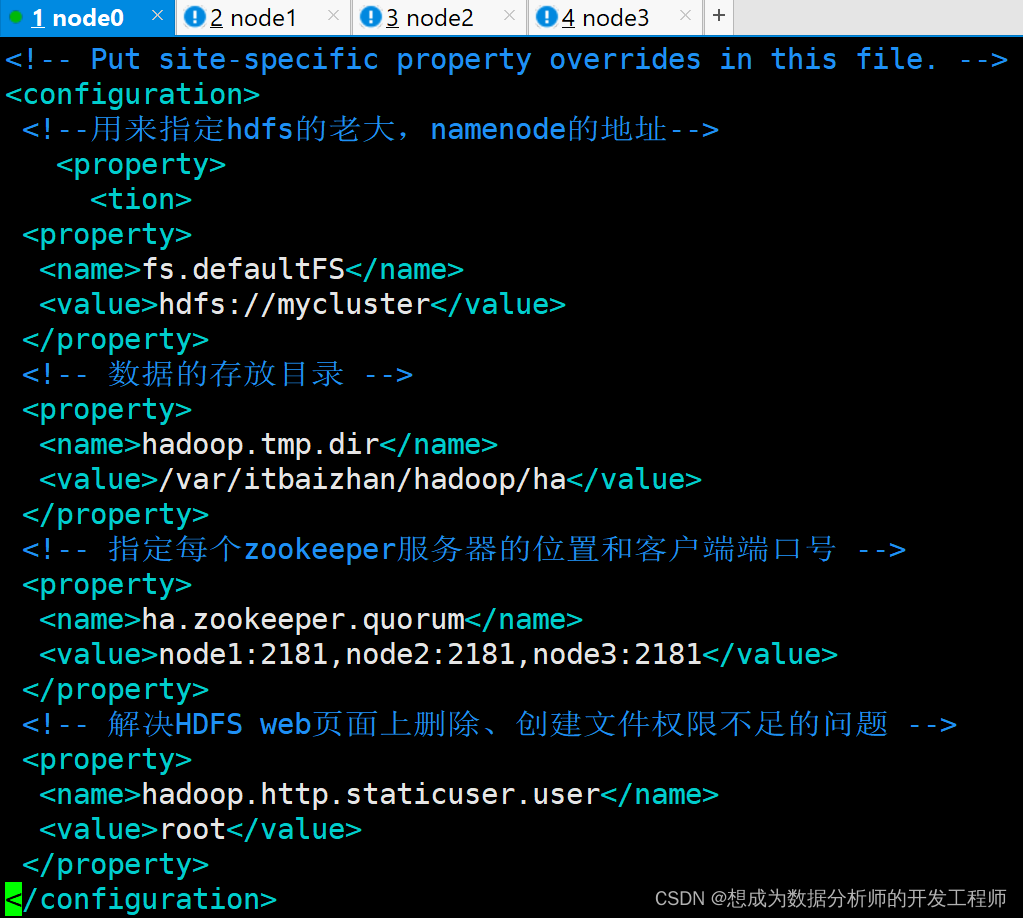
[root@node0 hadoop]# vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 数据的存放目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/var/itbaizhan/hadoop/ha</value>
</property>
<!-- 指定每个zookeeper服务器的位置和客户端端口号 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>node1:2181,node2:2181,node3:2181</value>
</property>
<!-- 解决HDFS web页面上删除、创建文件权限不足的问题 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>
- hdfs-site.xml
[root@node0 hadoop]# pwd
/opt/hadoop-3.1.3/etc/hadoop
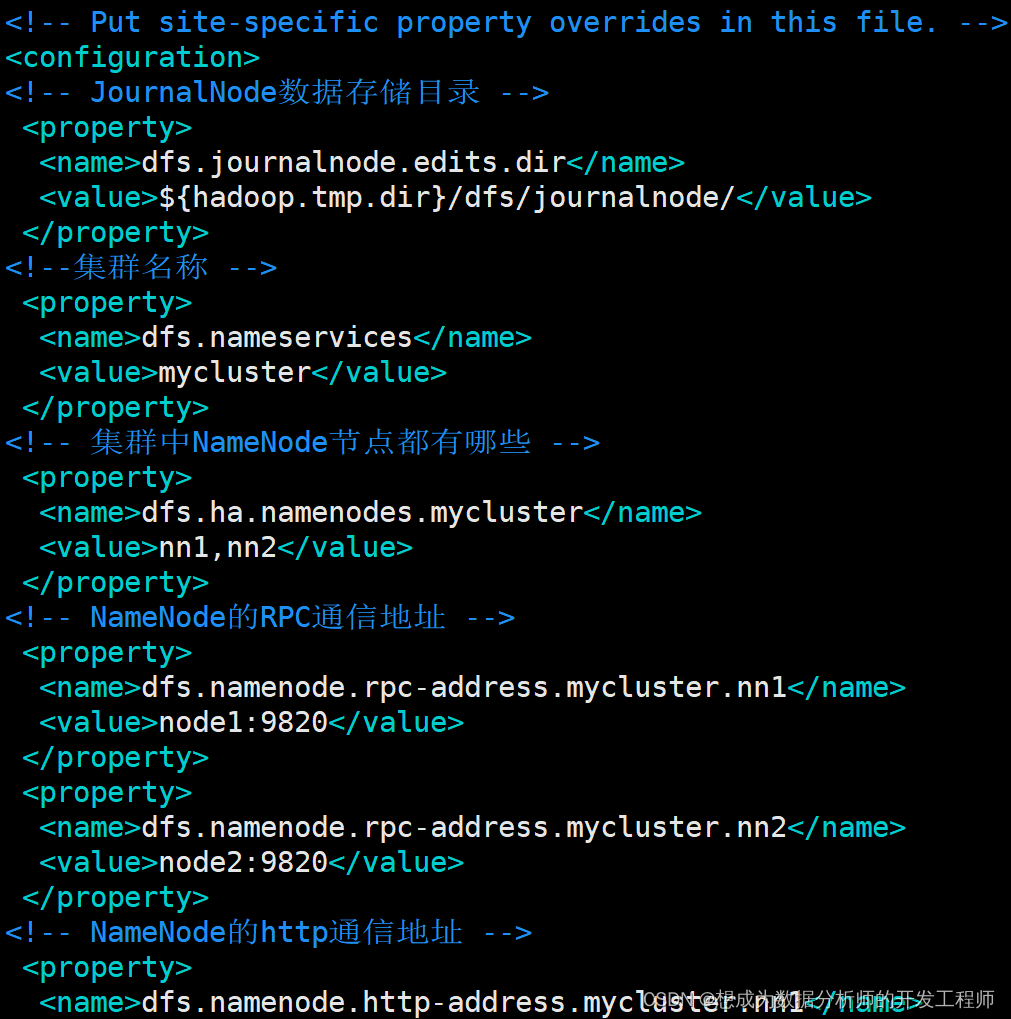
[root@node0 hadoop]# vim hdfs-site.xml
<configuration>
<!-- JournalNode数据存储目录 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>${
hadoop.tmp.dir}/dfs/journalnode/</value>
</property>
<!--集群名称 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- 集群中NameNode节点都有哪些 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn0,nn1</value>
</property>
<!-- NameNode的RPC通信地址 -->
<property>
<name>dfs.namenode.rpcaddress.mycluster.nn0</name>
<value>node0:9820</value>
</property>
<property>
<name>dfs.namenode.rpcaddress.mycluster.nn1</name>
<value>node1:9820</value>
</property>
<!-- NameNode的http通信地址 -->
<property>
<name>dfs.namenode.httpaddress.mycluster.nn0</name>
<value>node0:9870</value>
</property>
<property>
<name>dfs.namenode.httpaddress.mycluster.nn1</name>
<value>node1:9870</value>
</property>
<!-- 指定NameNode元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node0:8485;node1:8485;node2:8485/mycluster</value>
</property>
<!-- 访问代理类:client用于确定哪个NameNode为Active-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh秘钥登录-->
<property>
<name>dfs.ha.fencing.ssh.private-keyfiles</name>
<value>/root/.ssh/id_dsa</value>
</property>
<!-- 启用nn故障自动转移 -->
<property>
<name>dfs.ha.automaticfailover.enabled</name>
<value>true</value>
</property>
</configuration>
- 先同步配置文件到node1、node2、node3
[root@node0 hadoop]# scp hadoop-env.sh core-site.xml hdfs-site.xml node1:`pwd`
[root@node0 hadoop]# scp hadoop-env.sh core-site.xml hdfs-site.xml node2:`pwd`
[root@node0 hadoop]# scp hadoop-env.sh core-site.xml hdfs-site.xml node3:`pwd`
hadoop-env.sh 100% 16KB 10.6MB/s 00:00
core-site.xml 100% 1337 1.7MB/s 00:00
hdfs-site.xml 100% 2593 3.5MB/s 00:00
Hadoop环境变量配置参考完全分布式的环境变量配置(参考此专栏之前的博客)
[root@node0 hadoop]# echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/usr/java/default/bin:/usr/java/default/bin:/opt/hadoop-3.1.3/bin:/opt/hadoop-3.1.3/sbin:/root/bin
7.3.4 首次启动HDFS HA集群
a) 启动zookeeper集群并查看状态, node1、node2、node3分别执行:
zkServer.sh start
检查四台虚拟机是否启动zookeeeper集群,node0未安装
[root@node0 ~]# zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@node1 ~]# zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.5.7/bin/../conf/zoo.cfg
Starting zookeeper ... already running as process 69903.
[root@node2 ~]# zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.5.7/bin/../conf/zoo.cfg
Starting zookeeper ... already running as process 60415.
[root@node3 ~]# zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.5.7/bin/../conf/zoo.cfg
Starting zookeeper ... already running as process 25958.
查看启动状态与Mode
[root@node1 ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.5.7/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: follower
[root@node2 ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.5.7/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: leader
[root@node3 ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.5.7/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: follower
b) 在node0\node1\node2上启动三台journalnode
[root@node0 ~]# cd /opt/hadoop-3.1.3/etc/hadoop
[root@node0 hadoop]# jps
15331 NameNode
71333 Jps
16379 DataNode
[root@node0 hadoop]# hdfs --daemon start journalnode
[root@node0 hadoop]# jps
71555 Jps
15331 NameNode
71496 JournalNode
16379 DataNode
[root@node1 ~]# cd /opt/hadoop-3.1.3/etc/hadoop
[root@node1 hadoop]# jps
22500 SecondaryNameNode
22824 DataNode
88458 Jps
69903 QuorumPeerMain
[root@node1 hadoop]# hdfs --daemon start journalnode
[root@node1 hadoop]# jps
22500 SecondaryNameNode
88661 Jps
22824 DataNode
69903 QuorumPeerMain
88623 JournalNode
[root@node2 ~]# cd /opt/hadoop-3.1.3/etc/hadoop
[root@node2 hadoop]# jps
22437 DataNode
60415 QuorumPeerMain
78270 Jps
[root@node2 hadoop]# hdfs --daemon start journalnode
[root@node2 hadoop]# jps
22437 DataNode
78468 Jps
78431 JournalNode
60415 QuorumPeerMain
[root@node3 ~]# cd /opt/hadoop-3.1.3/etc/hadoop
[root@node3 hadoop]# jps
25958 QuorumPeerMain
43768 Jps
[root@node3 hadoop]# jps
25958 QuorumPeerMain
43901 Jps
c) 选择node0(未安装zookeeper),格式化HDFS
[root@node0 hadoop]# hdfs namenode -format
#看到如下提示,表示格式化成功
2021-10-15 13:21:33,318 INFO common.Storage: Storage directory /var/itbaizhan/hadoop/ha/dfs/name has been successfully formatted.
/var/itbaizhan/hadoop/ha/dfs/name/current/目录下产生了fsimage文件
[root@node0 hadoop]# ll /var/itbaizhan/hadoop/ha/dfs/name/current/
total 16
-rw-r--r--. 1 root root 391 Mar 5 00:56 fsimage_0000000000000000000
-rw-r--r--. 1 root root 62 Mar 5 00:56 fsimage_0000000000000000000.md5
-rw-r--r--. 1 root root 2 Mar 5 00:56 seen_txid
-rw-r--r--. 1 root root 219 Mar 5 00:56 VERSION
格式化后,启动namenode进程
[root@node0 hadoop]# hdfs --daemon start namenode
[root@node0 hadoop]# jps
62032 Jps
61923 NameNode
60228 QuorumPeerMain
61252 JournalNode
22437 DataNode
d) 在另一台node1上同步元数据,然后在该节点上启动NameNode。
[root@node1 hadoop]# hdfs namenode -bootstrapStandby
# 出现以下信息说明成功
About to bootstrap Standby ID nn1 from:
Nameservice ID: mycluster
Other Namenode ID: nn2
Other NN's HTTP address: http://node2:9870
Other NN's IPC address: node2/192.168.188.140:9820
Namespace ID: 365299465
Block pool ID: BP-2070874415-192.168.188.140-1678006602170
Cluster ID: CID-f5b32a07-6a91-4044-b097-fd5ba69fd631
Layout version: -64
isUpgradeFinalized: true
# 启动namenode
[root@node1 hadoop]# hdfs --daemon start namenode
e) 初始化zookeeper上的内容 一定是在namenode节点(node1或node2)上执行格式命令之前在node2-node4任一节点上:
[root@node4 hadoop]# zkCli.sh
[zk: localhost:2181(CONNECTED) 1] ls /
[itbaizhan, registry, wzyy, zk001, zookeeper]
接下来在node0上执行:
[root@node0 ~]# hdfs zkfc -formatZK
2021-10-15 13:30:20,048 INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/mycluster in ZK.
然后在node4上接着执行:
[zk: localhost:2181(CONNECTED) 1] ls /
[zookeeper, hadoop-ha]
[zk: localhost:2181(CONNECTED) 2] ls /hadoop-ha
[mycluster]
[z: localhost:2181(CONNECTED) 3] ls /hadoop-ha/mycluster
[]
执行到此处,还没有启动3个DataNode和2个ZKFC进程。
f) 启动hadoop集群,在node1执行
[root@node0 ~]# start-dfs.sh
#出现如下错误提示
ERROR: Attempting to operate on hdfs journalnode as root
ERROR: but there is no HDFS_JOURNALNODE_USER defined. Aborting operation.
Starting ZK Failover Controllers on NN hosts [node1 node2]
ERROR: Attempting to operate on hdfs zkfc as root
ERROR: but there is no HDFS_ZKFC_USER defined. Aborting operation.
#解决办法:修改start-dfs.sh文件
[root@node1 ~]# vim /opt/hadoop-3.1.3/sbin/start-dfs.sh
#添加
HDFS_JOURNALNODE_USER=root
HDFS_ZKFC_USER=root
#为了防止关闭时出现类似的错误提示,修改stop-dfs.sh
[root@node0 ~]# vim /opt/hadoop-3.1.3/sbin/stop-dfs.sh
#添加
HDFS_JOURNALNODE_USER=root
HDFS_ZKFC_USER=root
#再次启动
[root@node0 hadoop]# start-dfs.sh
在启动zkCli.sh的节点node4上观察:
[zk: localhost:2181(CONNECTED) 5] ls /hadoop-ha/mycluster
[ActiveBreadCrumb, ActiveStandbyElectorLock]
[zk: localhost:2181(CONNECTED) 6] get -s /hadoop-ha/mycluster/ActiveStandbyElectorLock
myclusternn1node1 �L(�>
cZxid = 0x600000008
ctime = Fri Oct 15 13:40:10 CST 2021
mZxid = 0x600000008
mtime = Fri Oct 15 13:40:10 CST 2021
pZxid = 0x600000008
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x300006fd40a0002
dataLength = 29
numChildren = 0

将Active NameNode对应节点node1上NameNode进程kill掉:
[root@node0 hadoop]# jps
10337 Jps
7347 JournalNode
9701 DFSZKFailoverController
7689 NameNode
[root@node0 hadoop]# kill -9 7689
#或者
[root@node0 hadoop]# hdfs --daemon stop namenode
[root@node0 hadoop]# jps
7347 JournalNode
9701 DFSZKFailoverController
10381 Jps
node3上继续查看:
[zk: localhost:2181(CONNECTED) 12] get -s /hadoop-ha/mycluster/ActiveStandbyElectorLock
myclusternn2node2 �L(�>
cZxid = 0x60000006c
......
但是通过浏览器访问发现Active NameNode不能自动进行切换。这是因为缺少一个rpm包:psmisc。接下来在四台节点上安装psmisc包。
yum install -y psmisc
node0访问不了,node1 从Standby变为了Active。
node0上再次启动namenode:
7.3.5 编写HDFS HA启动和关闭脚本
在node0的/root/bin目录下编写zk、hdfs启动脚本
[root@node1 ~]# mkdir bin
[root@node1 ~]# ls
anaconda-ks.cfg bin hh.txt
[root@node1 ~]# cd bin/
[root@node1 bin]# vim allJps.sh
#!/bin/bash
#查看当前节点的角色进程
echo "-----------node1 jps--------------"
jps
for node in node2 node3 node4
do
echo "-----------$node jps--------------"
ssh $node "source /etc/profile;jps"
done
[root@node1 bin]# chmod +x allJps.sh
[root@node1 bin]# vim starthdfs.sh
#!/bin/bash
#启动zk集群
for node in node2 node3 node4
do
ssh $node "source /etc/profile;zkServer.sh start"
done
#休眠1s
sleep 1
#启动hdfs集群
start-dfs.sh
allJps.sh
# ESC->:wq
[root@node1 bin]# chmod +x starthdfs.sh
在node0的/root/bin目录下编写zk、hdfs关闭脚本
[root@node1 bin]# vim stophdfs.sh
[root@node1 bin]# cat stophdfs.sh
#!/bin/bash
#关闭hdfs集群
stop-dfs.sh
#休眠1s
sleep 1
#关闭zk集群
for node in node2 node3 node4
do
ssh $node "source /etc/profile;zkServer.sh stop"
done
#查看四个节点中角色进程
allJps.sh
[root@node1 bin]# chmod +x stophdfs.sh
测试:stophdfs.sh进行关闭,starthdfs.sh进行启动