关于自动代码生成的文献综述阅读记录。这篇文献为《Code Generation Using Machine Learning:A Systematic Review》。
一、摘要
1.代码生成领域的主要研究内容:description-to-code、code-to-description、code-to-code。
2.最流行的应用:code generation from natural language descriptions, documentation generation, and automatic program repair。
3.最常用的机器学习方法:RNN、Transformer、CNN。
二、介绍
为了提高软件开发的效率,一些研究人员开始利用神经网络来完成一些自动化编程任务。比如,用RNN、transformer等结构来进行从注释到代码、从代码到注释、跨PL翻译等等工作。还产生了一些商用产品,如Tabnine、Copilot。
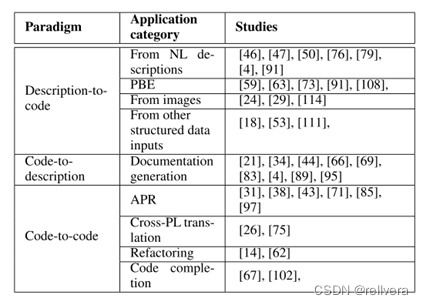
三、代码生成领域的三大主要研究内容
(一)Description-to-code
(二)Code-to-description
(三)Code-to-code
四、Tokenizer 词语切分
Tokenization是一个预处理工作,用于把输入的字符串划分为块。这些块/tokens(令牌)被映射成为数字,输入到ML模型里面。
Tokenizer(分词器)的类型有三种:
1.基于词 word-based
2.基于字符 character-based
3.基于子词 subword-based
subword-based tokenization是基于词和基于字符的折中方案,其词汇表包括所有基本字符以及经常出现的字符序列。
但是,在代码中进行tokenize的工作时,会存在一个问题:代码中唯一的“单词”数量会比natural language中的单词数量大得多。这部分是因为,函数名、变量的标识符通常是用多个英文单词连接起来的。比如:若想将“hello world”打印到控制台,其函数名可以是‘‘helloWorld’’ ‘‘hello_world’’等等。所以在这种情况下,word-based tokenization这种方法不太理想。此外,character_based的方法在各个研究中也用的很少。部分文献采用了subword-based的方法。
有些研究采用自定义标记化过程(custom tokenization process),在保持vocabulary的size很小的同时,封装有用的信息。比如:token copying、token abstraction这两个策略。
五、数据
训练数据/测试数据有三个来源:开源代码、人工编的代码、机器自动生成的代码。
如何评估训练数据/测试数据的质量?
自动评估、人工评估。
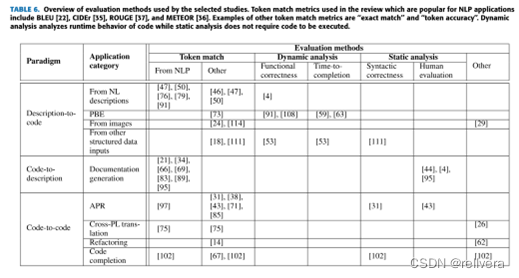
六、如何评估合成代码的质量
把合成代码与完全正确的代码进行比较、进行静态分析、运行时分析等等操作。主要方法如表6所示。
(1)token match:比如NLP中的BLEU,CIDEr,ROUGE和METEOR等方法。
(2)dynamic analysis:此方法用得少,分析代码运行时的行为。动态分析包括在运行时评估可执行代码的功能正确性、完成时间。
(3)static analysis:此方法用得少,静态分析不要求代码是可执行的,但如果只考虑语法,则会导致退化。
七、未来的工作
1.提高语言模型的效率。有利于降低成本。
2.集成学习。
3.使用AST(源代码抽象语法树)。本文讨论的多个研究,如[21],[95],在其模型中使用了代码的AST表示。