该笔记基于:Multimodal Machine Learning:A Survey and Taxonomy
- 该论文是一篇对多模态机器学习领域的总结和分类,且发表于2017年,算是相当新的综述了。老师在课上推荐阅读,我花了三天大体看了一边,其中有很多实际的方法或者技术对我来说是全新的领域,也是未来学习的方向,但是对这个领域和其想解决的问题有了大致的了解。记录如下:
关键名词解释:
- Modality:A particular mode in which something exists or is experienced or expressed. 中文释义为模态或形态。一个事物存在(被体验/被表达)的一种特定的方式。如一只猫,能被看见,图像是模态;能被听见,声音是模态;能被触摸,它身上的皮毛纹理是一种模态;某些人可以通过气味辨别自己的猫,那么气味是模态。模态之间大都是异质性的(heterogeneity)。
- Multimodal:多模态,顾名思义,包含了多种模态。如果一个研究问题或者数据集包含了多个上述的模态时,也可以被称为multimodal。
目的&目标:
- 为了使人工智能进一步加强对我们周边事物的理解,它需要具备解释多模态信号的能力。(因为我们就身处在一个多模态的环境中,接收并处理着大量多模态信号)
- 多模态机器学习致力于搭建能够处理和连接多模态信息的模型。“Multimodal machine learning aims to build models that can process and relate information from multiple modalities”
面临的挑战(Challenges):
一个领域的挑战是对这个领域所研究的问题和解决方案的概括,举个例子,比如机器视觉中有一个挑战是“遮挡”,这意味着,在面临一个实际计算机视觉问题时,你需要考虑遮挡对你的任务是否有影响,研究对象被遮挡了怎么解决,现有的解决方案是否能满足你的需求,你是否需要改进已有方案。以下是多模态ML所面临的挑战:
- 表征(Representation)
- 翻译(Translation)
- 对齐(Alignment)
- 融合(Fusion)
- 联合学习(Co-learning)
下图是综述中给出的各应用涉及到的挑战
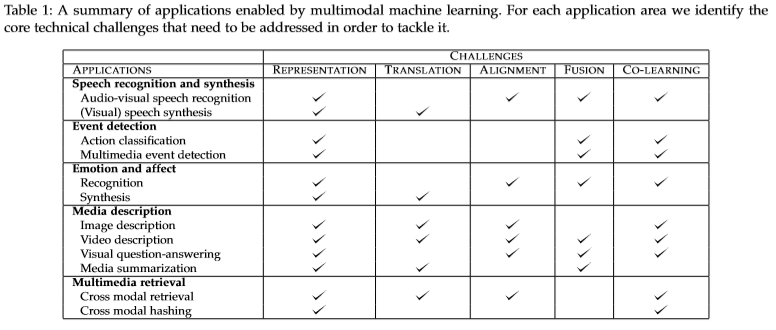
表征:
表征也可以理解为表示,即试图通过各模态的信息找到某种对多模态信息的统一表示。当然,在计算机领域,一般都会是一个向量,但维度、各维度的具体值能否具备好的性质就成了关键。那么什么是好的性质呢?这需要具体任务具体分析,一个简单的例子,如果做的是多模态信息检索(就是比如百度搜索“在捉老鼠的猫”,能得到一系列图片和视频),学习出的视频、图片、文本的表征(向量)的相似性非常重要,来自同一个体的不同模态信息的表征(向量)间应具备更高的相似程度。
- 来自综述中的定义:“we use the term feature and representation interchangeably, with each referring to a vector or tensor representation of an entity, be it an image, audio sample, individual word, or a sentence. A multimodal representation is a representation of data using information from multiple such entities. ”
- 表征是一个非常基础的任务,好的表征能极大的提高模型的表现。
- 表征任务的困难点:如何结合异质性的来源的数据,比如文字是符号性的,图片是一个RGB矩阵,视频是时序的RGB矩阵,声音需要采样成一个一位数组;如何处理不同级别的噪音,原因是不同模态产生的噪声是不同的;如何处理数据缺失的问题
- 好的表征应具备的性质:
- 平滑 smoothness, 可以类比一下自然语言处理中语言模型的平滑
- 时序和空间一致性 temporal and spatial coherence
- 稀疏性 sparsity
- 自然聚类 natural clustering(我不太确定怎么翻译,暂时这样)
- 在表征空间的相似性应能够反映出表征所对应的概念的相似性 similarity in the representation space should reflect the similarity of the corresponding concepts
- 即使在某些模态数据缺失的情况下,这种多模态的表征依旧能够轻松获得 the representation should be easy to obtain even in the absence of some modalities
- 应能够在给出被观察到的其他模态的数据后,填补出缺失的模态数据 ,it should be possible to fill-in missing modalities given the observed ones
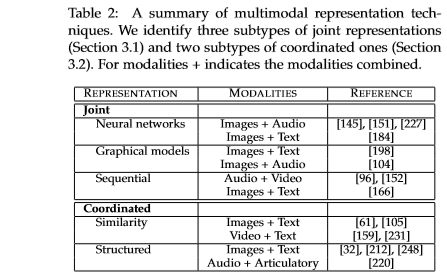
- 两种主要的表征思路
- Joint representations
- Coordinated representations
- 表征技术一览表,其中[#]是综述中引用的论文编号
翻译:
- 实际上,也可以理解为映射(mapping)。MMML很大一部分研究专注于将一种模态数据翻译(映射)为另一种模态数据。即,任务为给出一个实体的一个模态,需要生成该实体的另一模态。例如给出一段人说话的脸部特写视频(无声音),生成人说话的声音信号。又比如,给定一张照片,生成对照片的描述。
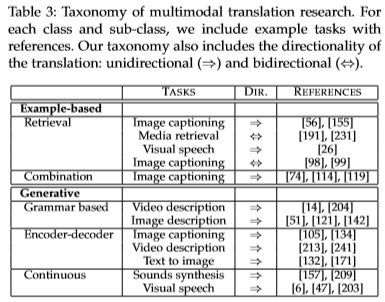
- 技术分类
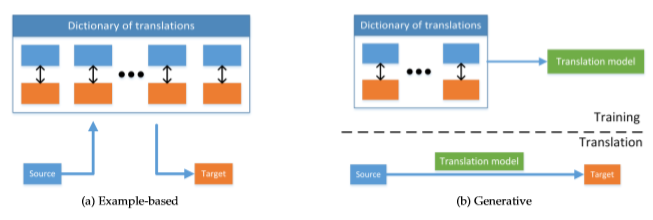
- 基于例子的 example-based
- 生成式的 generative
- 简单的理解,测试阶段,example-based是需要字典的,而生成式是不需要字典的,它通过数据学习到两个模态潜在的映射关系。
- 翻译任务面临的困难点
- 非常难于评估,因为这类任务没有标准答案,答案通常非常开放和主观。这其实也是机器翻译面临的问题。
- 为了解决评估困难,提出了VQA(Visual question-answering)任务。然而它也有问题,例如特定问题的歧义性,回答和问题偏置(ambiguity of certain questions and answers and question bias)。
- 技术和实际应用一览表:
对齐:
- 从两个甚至多个模态中寻找事物子成份之间的关系和联系。比如给定一张图片和图片的描述,找到图中的某个区域以及这个区域在描述中对应的表述。又比如给定一个美食制作视频和对应的菜谱,实现菜谱中的步骤描述与视频分段的对应。
- 对齐分为两类:显式对齐和隐式对齐。显式对齐即应用的主要任务就是对齐,而隐式对齐是指应用在完成主要任务时需要用到对齐的技术。
- 显式对齐的技术方法分类
- 无监督方法 Unsupervised
- (弱)监督方法 (Weakly)Supervised
- 隐式对齐的技术方法分类
- 图模型 Graphical models
- 神经网络 Neural networks ----- 综述中尤其提到attention机制
- 对齐任务的困难点
- 很少有显式对齐标注的数据集
- 很难建模不同模态之间相似度计算
- 存在多个可能的对齐方案并且不是一个模态的所有元素在另一个模态中都存在对应
- 技术和实际应用一览表

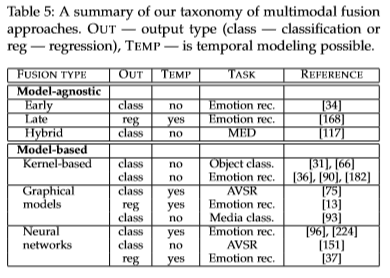
融合:
融合是MMML最早的关注点之一。
- 多模态融合指从多个模态信息中整合信息来完成分类或回归任务。“multimodal fusion is the concept of integrating information from multiple modalities with the goal of predicting an outcome measure: a class (e.g., happy vs. sad) through classification, or a continuous value (e.g., positivity of sentiment) through regression.”融合还有更宽泛的定义,而综述中的定义的融合,是指任务在最后预测并以预测输出值为目的时才进行多模态整合。在深度神经网络方法下,融合和表征两个任务是很难区分的。但在图模型以及基于核的方法中比较好区分。(我暂时也没法解释这一段,需要进一步研究)
- 融合的价值
- 在观察同一个现象时引入多个模态,可能带来更健壮(robust)的预测
- 接触多个模态的信息,可能让我们捕捉到互补的信息(complementary information),尤其是这些信息在单模态下并不“可见”时
- 一个多模态系统在缺失某一个模态时依旧能工作
- 多模态融合有两大类:无模型 model-agnostic / 基于模型 model-based
- model-agnostic:不直接依赖于某个特定的机器学习算法
- 进一步分为early\late\hybrid fusion
- early fusion,也称为feature-based,基于特征。通常是在各模态特征被抽取后就进行融合,通常只是简单的连接他们的表征,也就是joint representation,直接连接多个向量。并使用融合后的数据进行模型训练,相比之后两种在训练上更为简单。
- late fusion,也称为decision-based,基于决策的。该方法在各个模态做出决策后才进行融合,得出最终的决策。常见的机制有平均(averaging)、投票(voting schemes)等等。这种方法中,各模态可以使用不同的模型来训练,带来更多的便利性。
- hybrid fusion,一种尝试结合early fusion和late fusion优势的方法。
- model-based:显式的在构造中完成融合
- Multiple Kernel learning(MKL),多核学习
- Graphical models,图模型
- Neural Networks,神经网络
- 神经网络在近期成为解决融合问题非常流行的方案,然而图模型以及多核学习依旧被使用,尤其是在有限的训练数据和模型可解释性非常重要的情况下。
- 融合任务的困难点:
- 信号可能并不是时序对齐的(temporally aligned)。很可能是密集的连续信号和稀疏的事件(比如一大段视频只对应一个词,然后整个视频只对应稀少的几个词)。
- it is difficult to build models that exploit supplementary and not only complementary information(翻译不出来,综述在最开始也提到过supplementary和complementary是两种模态间的关系)
- 每一个模态在不同的时间点可能表现出不同的形式和不同等级的噪声
- 技术和实际应用一览表
联合学习:
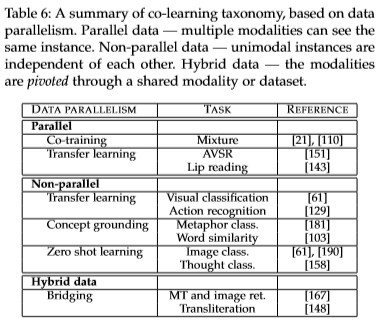
- 联合学习的目的是通过利用资源丰富(比如数据量大)的模态的知识来辅助资源稀缺(比如较小数据)的模态建立模型。
- 联合学习时任务独立的(task independent)并可以用于提升融合、翻译和对齐任务中的模型。
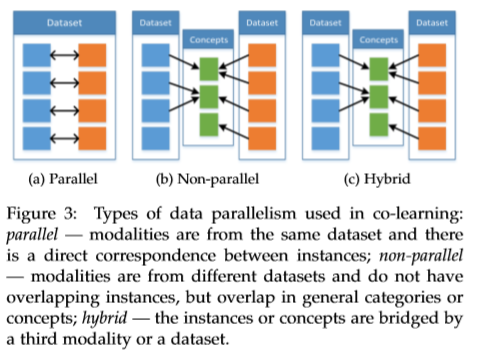
- 联合学习中,辅助模态(helper modality)通常只参与模型的训练过程,并不参与模型的测试使用过程。即使用时,模型输入并不需要辅助模态的数据。 联合学习的分类是基于训练资源(数据)形式划分的,下图的文字部分解释得很清楚,并在分类后记录各分类涉及的技术。
- parallel:Co-training\Transfer learning
- non-parallel:Transfer learning\Concept grounding(概念接地)\Zero shot learning
- hybrid:Bridging
- 技术和实际应用一览表
接下来可能会针对一两个我感兴趣的挑战和具体应用,阅读相应论文并尝试复现(虽然很可能失败或者需要学习大量的知识),如果你对MMML感兴趣,欢迎继续关注我的博客。
Plus Ultra