写作日期:2022.4.25。 天气:下大雨。
2021 NeurIPS。
《subgraph federated learning with missing neighbor generation》论文阅读
1.提出动机
一个大图由于存储或者是隐私问题等存储在不同的子图中,如何在不共享子图之间信息的情况下训练一个好的可以综合不同子图之间信息的模型?更精确点来说:“without sharing actual data,how to obtain a globally powerful graph mining model”。 子图内存储的信息可能和全局图的信息具有很大的偏差(biased)。于是本文under subgraph federated learning,做出了以下贡献:
1.FedSage:基于FedAvg训练一个GraphSage模型:在多个局部子图之中综合了节点特征、链接结构、任务标签。
2.FedSage+:训练一个缺失邻居生成器,处理局部子图之内的缺失链接。
实验证明了我们的模型的有效性和高效性。
2.挑战+解决思路
挑战1: 如何从多个局部子图之间共同进行学习?(局部子图是具有异质的特征和结构的,如果根据这些局部子图学习一个全局的model)
解决方案1:通过FedAvg训练GraphSage。
挑战2: 如何处理局部子图中缺失的链接?(missing links)
子图内可能缺失链接;子图之间among data owners可能缺失链接,这是data owners之间的bridge,这是很重要的。
解决方案2: 通过FedSage+来生成缺失的neighbors。
总 的 来 说 , 本 文 考 虑 了 广 泛 存 在 的 但 是 没 有 进 行 研 究 的 一 种 场 景 : 分 布 式 子 图 系 统 , 子 图 与 子 图 之 间 的 链 接 完 全 丢 失 了 , 我 们 着 眼 于 在 分 布 式 子 图 上 通 过 联 邦 学 习 获 得 一 个 全 局 的 节 点 分 类 器 。 \textcolor{red}{总的来说,本文考虑了广泛存在的但是没有进行研究的一种场景:分布式子图系统,子图与子图之间的链接完全丢失了,我们着眼于在分布式子图上通过联邦学习获得一个全局的节点分类器。} 总的来说,本文考虑了广泛存在的但是没有进行研究的一种场景:分布式子图系统,子图与子图之间的链接完全丢失了,我们着眼于在分布式子图上通过联邦学习获得一个全局的节点分类器。
3.具体解决方案
3.1 FedSage
3.1.1 分布在局部系统内的子图
符号定义:全局图: G = { V , E , X } G = \{V,E,X\} G={ V,E,X},节点集合为V,节点特征X,边集合E。在联邦学习系统中,我们有一个central server S,以及M个data owner,每个data owner都拥有一个分布式子图。 G i = { V i , E i , X i } G_i = \{V_i, E_i, X_i\} Gi={ Vi,Ei,Xi}属于data owner D i D_i Di。

问题定义: V = V 1 ∪ ⋯ ∪ V m V = V_1 \cup \cdots \cup V_m V=V1∪⋯∪Vm, V i ∩ V j = ∅ V_i \cap V_j = \empty Vi∩Vj=∅。需要注意的是central server S纸保留了一个graph mining model,并没有实际的图数据被存储。任何data owner D i D_i Di不能直接使用来自于其他data owner D j D_j Dj的节点信息。于是在两个data owner之间将不存在任何链接,但是在事实上可能是存在的。
目标:本文的系统使用了一个FL框架来协同地在多个data owner的独立的子图上进行协同学习,没有源图数据共享,来获得一个全局的节点分类器 F F F。
ϕ ∗ = argmin R ( F ( ϕ ) ) = 1 M ∑ i M R i ( F i ( ϕ ) ) , (1) \phi^* = \operatorname{argmin}R(F(\phi)) = \frac{1}{M}\sum_{i}^M R_i(F_i(\phi)), \tag{1} ϕ∗=argminR(F(ϕ))=M1i∑MRi(Fi(ϕ)),(1)
R i R_i Ri为经验风险损失函数:
R i ( F i ( ϕ ) ) = E ( G i , Y i ) ∼ D G i [ l ( F i ( ϕ ; G i ) , Y i ) ] , (2) R_i(F_i(\phi)) = \mathbb{E}_{(G_i,Y_i)\sim D_{G_i}}[\mathcal{l}(F_i(\phi;G_i),Y_i)],\tag{2} Ri(Fi(ϕ))=E(Gi,Yi)∼DGi[l(Fi(ϕ;Gi),Yi)],(2)
l \mathbb{l} l为task-specific loss function:
l = 1 ∣ V i ∣ ∑ v ∈ V i l ( ϕ ; G i ( v ) , y v ) . (3) \mathbb{l}=\frac{1}{|V_i|} \sum_{v\in V_i}\mathbb{l}(\phi;G_i(v),y_v).\tag{3} l=∣Vi∣1v∈Vi∑l(ϕ;Gi(v),yv).(3)
3.1.2 在独立的子图上进行协同学习
以子图 G i G_i Gi举例, h v 0 = x v h_v^0 = x_v hv0=xv,F计算v的表征 h v k h_v^k hvk如下: h v k = σ ( ϕ k ⋅ ( h v k − 1 ∣ ∣ A g g ( h u k − 1 , ∀ u ∈ N G i ( v ) ) ) ) . (4) h_v^k = \sigma(\phi^k \cdot (h_v^{k-1}||Agg({h_u^{k-1},\forall u \in N_{G_i(v)}}))).\tag{4} hvk=σ(ϕk⋅(hvk−1∣∣Agg(huk−1,∀u∈NGi(v)))).(4)
损失函数定义如下: L c = l ( ϕ ∣ G i ( v ) , y v ) = C E ( y ~ v , y v ) = − [ y v l o g y ~ v + ( 1 − y v ) l o g ( 1 − y ~ v ) ] . (5) L^c = l(\phi | G_i(v),y_v)\\=CE(\tilde{y}_v,y_v) \\= -[y_v log \tilde{y}_v + (1-y_v)log(1-\tilde{y}_v)]. \tag{5} Lc=l(ϕ∣Gi(v),yv)=CE(y~v,yv)=−[yvlogy~v+(1−yv)log(1−y~v)].(5)
重 要 的 有 关 F e d S a g e 更 新 方 式 的 说 明 : \textcolor{red}{重要的有关FedSage更新方式的说明:} 重要的有关FedSage更新方式的说明:
假设经过 e c e_c ec轮的训练通过分布式的子图系统获得一个共享的全局节点分类器(参数为 ϕ \phi ϕ)。
在每一轮训练 t t t中: ϕ i ← ϕ − η ∇ l ( ϕ ∣ { ( G i ( v ) , y v ) ∣ v ∈ V i t } ) . \phi_i \leftarrow \phi - \eta \nabla l(\phi | \{(G_i(v),y_v)|v \in V_i^t\}). ϕi←ϕ−η∇l(ϕ∣{
(Gi(v),yv)∣v∈Vit}).其中 v i t v_i^t vit是在t轮中从所有节点中采样出的训练节点。
然后central server S收集最近的 { ϕ i ∣ i ∈ [ M ] } \{\phi_i | i \in [M]\} {
ϕi∣i∈[M]},S设置 ϕ \phi ϕ为前面收集的值的均值。
最后S将 ϕ \phi ϕ广播到所有的data owner,完成了一轮的训练过程。
在经过了 e c e_c ec轮的训练之后,整个系统返回F作为全局分类器的输出,它不局限于和偏向于任何一个data owner。
那 么 这 样 存 在 什 么 问 题 呢 ? \textcolor{red}{那么这样存在什么问题呢?} 那么这样存在什么问题呢?
data owner之间有可能是存在链接的,但是这种链接是缺失的,且这种信息不能被任何data owner所cover。
3.2 FedSage+
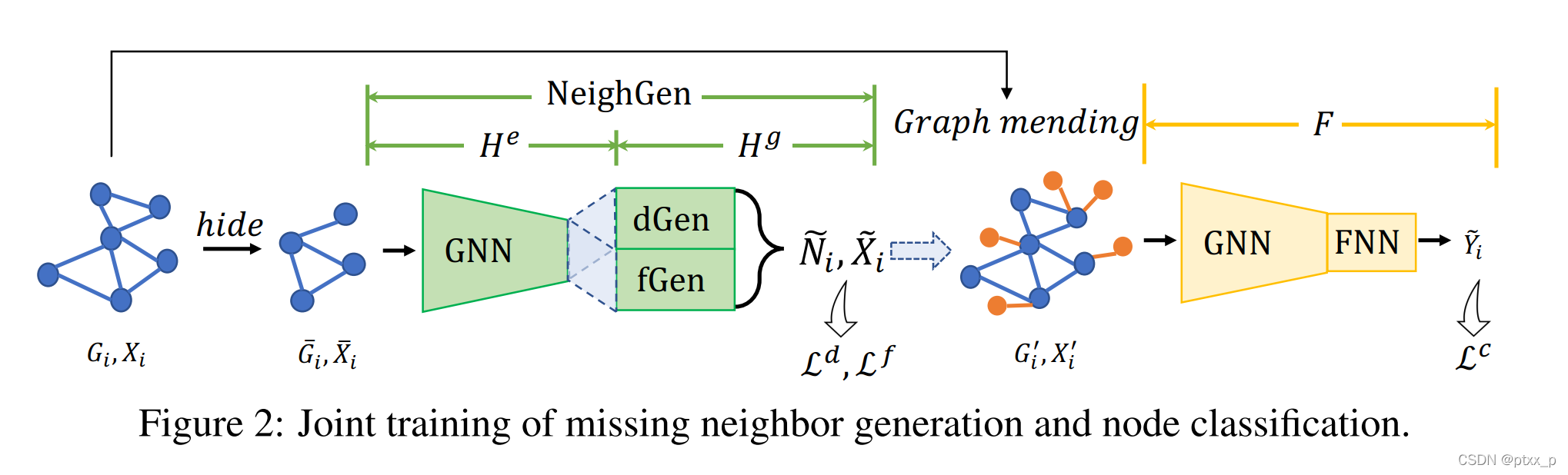
FedSage+:带有邻居生成的子图FL。
NeighGen:缺失邻居生成器。
NeighGen i _i i: D i D_i Di的缺失邻居生成器。
training:通过graph mending。
3.2.1 缺失邻居生成器(NeighGen,missing neighbor generator)
fig 2中展示了NeighGen的框架。NeighGen = encoder H e H^e He + H g H^g Hg。
H e : H^e : He: 一个GNN模型。具有参数 θ e \theta^e θe的K层的GraphSage encoder。 H e H^e He通过公式(4)来获取节点的embedding Z i = { z v ∣ z v = h v K , z v ∈ R d z , v ∈ V i } Z_i = \{z_v|z_v = h_v^K,z_v\in \mathbb{R}^{d_z},v\in V_i\} Zi={
zv∣zv=hvK,zv∈Rdz,v∈Vi}。
H g H^g Hg:一个生成式模型基于节点嵌入为输入图还原缺失邻居。 H g = d G e n + f G e n H^g = dGen+fGen Hg=dGen+fGen。
dGen:一个线性回归模型,参数为 θ d \theta^d θd,用来预测缺失邻居的数目 N ~ i = { n ~ v ∣ n ~ v ∈ N , v ∈ V i } \tilde{N}_i = \{\tilde{n}_v | \tilde{n}_v \in \mathbb{N},v \in V_i\} N~i={
n~v∣n~v∈N,v∈Vi}。
fGen:一个特征生成器,参数为 θ f \theta_f θf,用来生成 N ~ i \tilde{N}_i N~i个特征向量 X ~ i = { x ~ v ∣ x ~ v ∈ R n ~ v × d x , n ~ v ∈ N ~ i , v ∈ V i } \tilde{X}_i = \{\tilde{x}_v|\tilde{x}_v \in \mathbb{R}^{\tilde{n}_v \times d_x}, \tilde{n}_v \in \tilde{N}_i,v\in V_i\} X~i={
x~v∣x~v∈Rn~v×dx,n~v∈N~i,v∈Vi}。


4.实验
利用Louvain algorithm来划分子图。数据集划分情况如下:
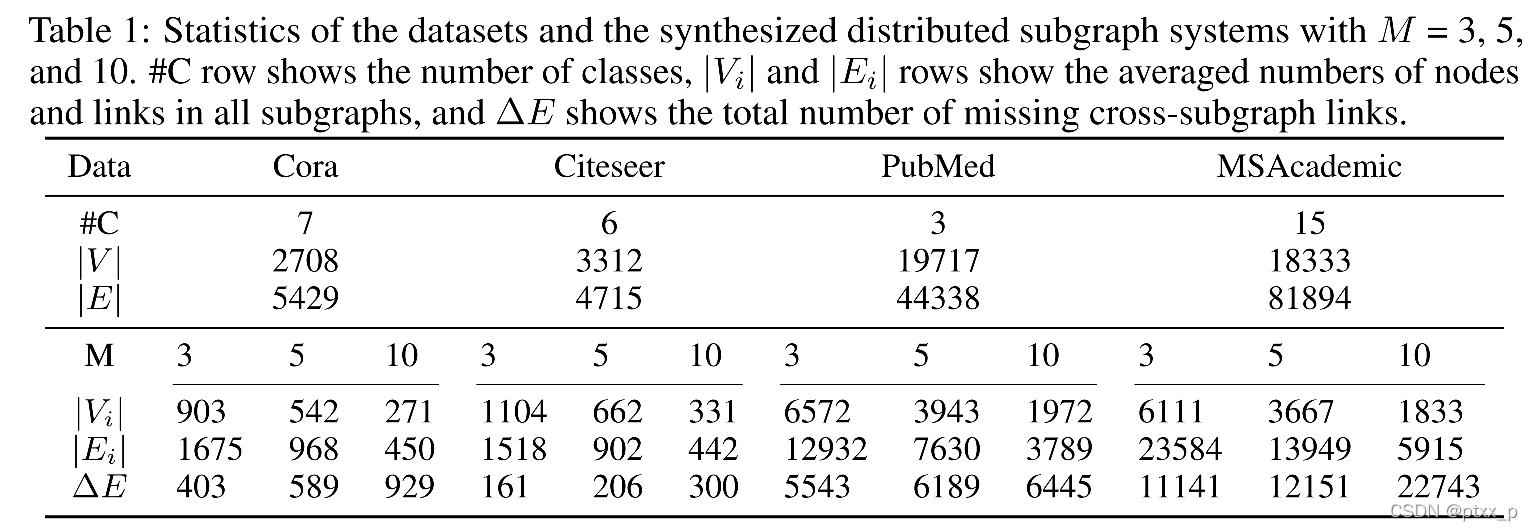
Locsage:无邻居生成。
Locsage+:无邻居生成+多个data owner共同参与训练。
Fedsage:有邻居生成。
Fedsage+:有邻居生成+多个data owner共同参与训练。
overall performance:
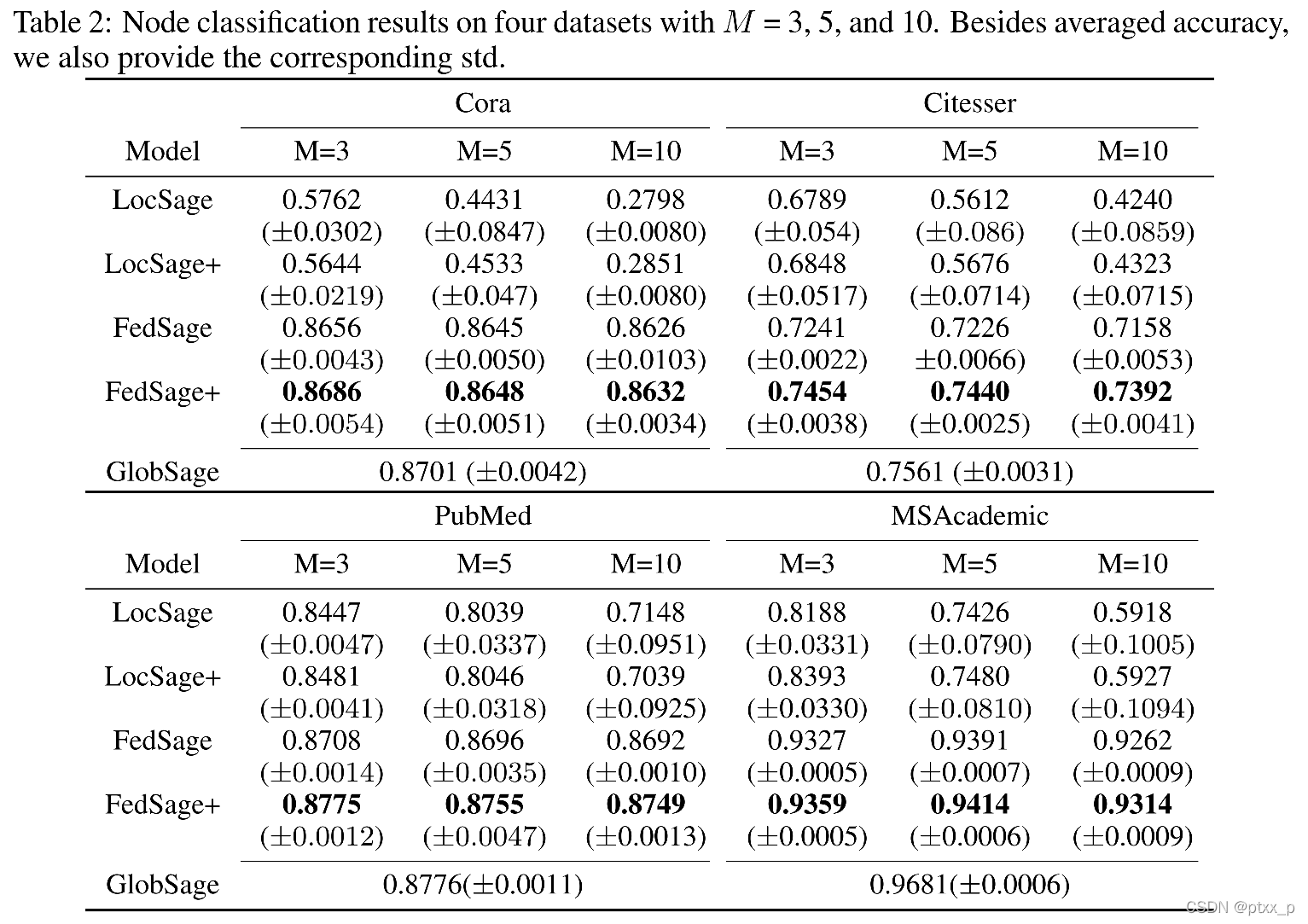
Fedsage差不多可以达到GlobSage的效果了。(损失很小)
参数学习:

样例分析:
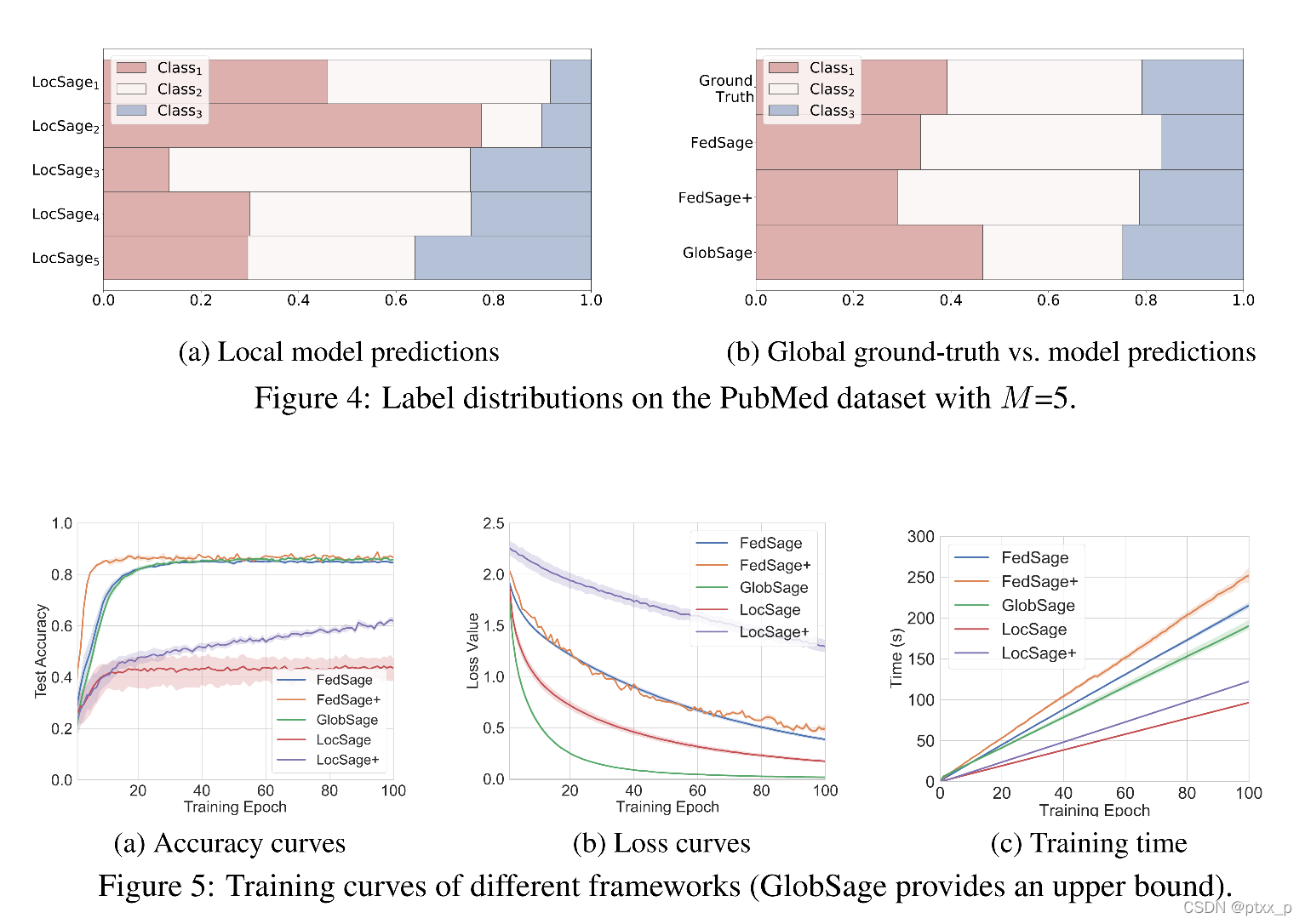
可以看出FedSage+基本上可以利用局部的子图(且子图非独立同分布)还原出全局的标签分布情况。
之后作者比较了收敛和训练速度的情况(图5)。
5.代码阅读
5.我的思考
实际上还是造成了信息的泄漏,fedSage+虽然没有利用raw data,但是还是利用了embedding data from other data owners。