Part1 论文阅读与视频学习
1 ShuffleNet V1&V2
1.1 网络结构
亮点:提出了channel shuffle的思想,由GConv和DWConv组成,在移动端设备上具有更短的演算时间
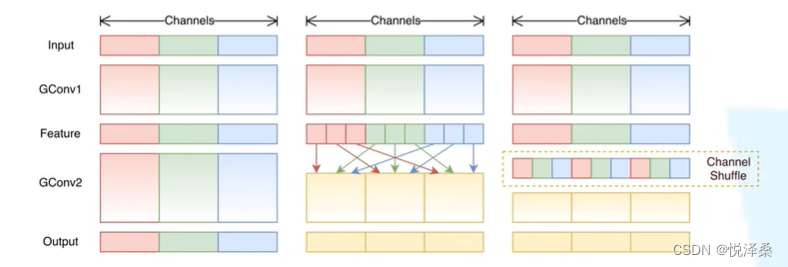
channel shuffle:增强channel间的信息交流
ShuffleNet V1:
ShuffleNet结构表:

在只考虑纯理论计算的情况下,ShuffleNet需要的计算量更小:

在V1的基础上,V2指出,计算复杂度不能只看FLOPs,并提出了4条设计高效网络的准则,提出了新的block设计。
FLOPs并不是衡量计算量的直接指标,内存访问造成的时间成本,并行等级,memory,size和cost等也会影响计算量: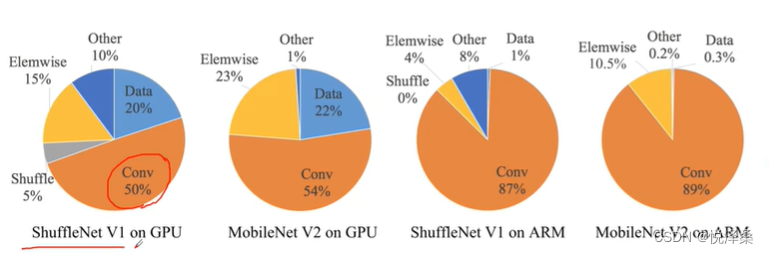
设计高效网络的4条准则:
- 当FLOPs不变时,卷积层的输入特征矩阵与输出特征矩阵相等时MAC最小(MAC即memory access cost)
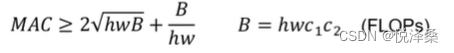
- 当FLOPs不变时,GConv的groups增大时MAC也会增大
- 网络设计的碎片化程度越高,速度越慢
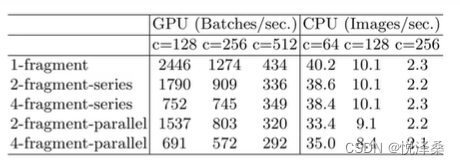
- Element-wise操作带来的影响是不可逆的(Element-wise指对每个元素进行的操作,包含激活函数ReLU,加操作AddTensor,Addbias等,这些操作FLOPs很小但MAC很大)
总结:
- 使用比较平衡的卷积(输入和输出的比值尽量接近1)
- 注意分组卷积的运算成本
- 降低网络的碎片化程度
- 减少element-wise操作的使用
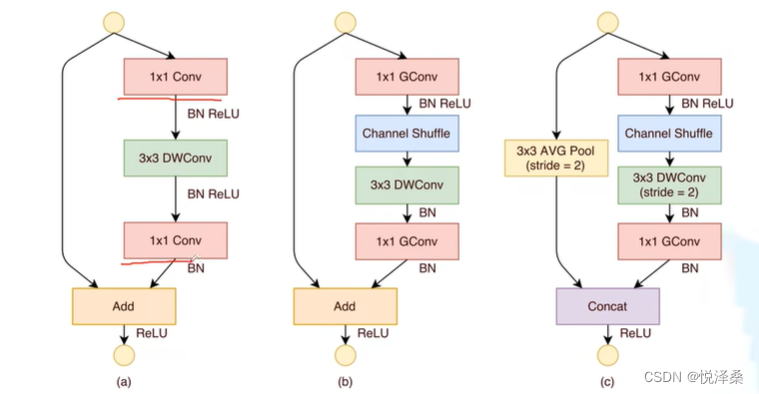
shuffleNet的结构,其中前两个是V1,后两个是V2:
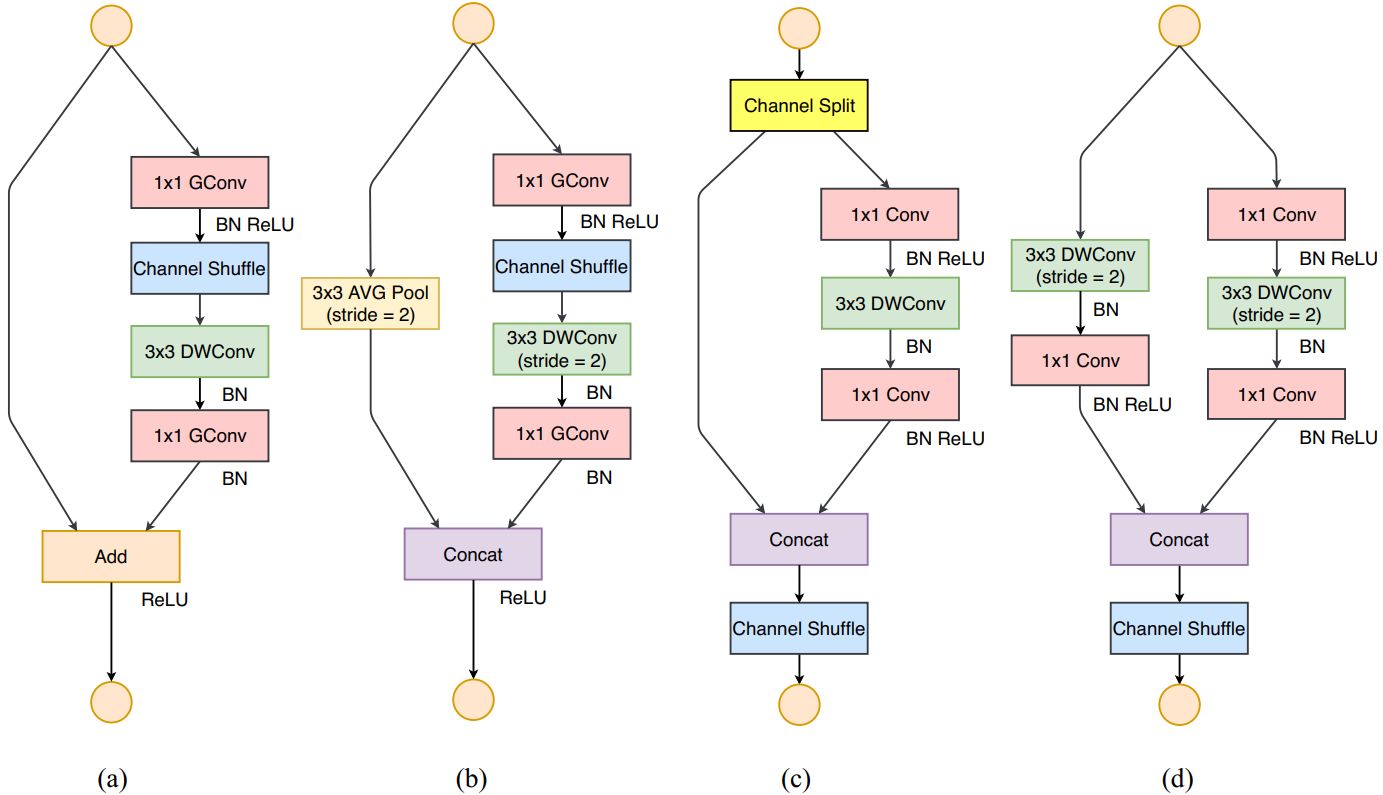
(c)结构减少了碎片化操作,左分支没有单元,只对右分支进行ReLU,输入与输出channel保持一致,摒弃了分组卷积。
(d)结构中,左右分支的输出channel都和输入channel保持一致,经过拼接操作后,最后的输出channel为输入channel的两倍。
1.2 基于PyTorch搭建ShuffleNet V2
代码链接:(colab)ShuffleNetV2
# ShuffleNet V2
# 划分并组合
def channel_shuffle(x:Tensor,groups:int)->Tensor:
batch_size,num_channels,height,width = x.size()
channels_per_group = num_channels//groups
# [batch_size,num_channels,height,width]->[batch_size,groups,channels_per_group,height,width]
x = x.view(batch_size,groups,channels_per_group,height,width)
# 转换成在内存中连续的数据
x = torch.transpose(x,1,2).contiguous()
# flatten
x = x.view(batch_size,-1,height,width)
return x
class InvertedResidual(nn.Module):
def __init__(self,input_c:int,output_c:int,stride:int):
super(InvertedResidual,self).__init__()
if stride not in [1,2]:
raise ValueError("illegal stride value.")
self.stride = stride
assert output_c%2==0
branch_features = output_c//2
# 当stride为1时,input_channel应该是branch_features的两倍
# <<是位运算
assert (self.stride!=1) or (input_c==branch_features<<1)
# 右分支
if self.stride == 2:
self.branch1 = nn.Sequential(
self.depthwise_conv(input_c,input_c,kernel_s=3,stride=self.stride,padding=1),
nn.BatchNorm2d(input_c),
nn.Conv2d(input_c,branch_features,kernel_size=1,stride=1,padding=0,bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True)
)
# 左分支没有操作
else:
self.branch1 = nn.Sequential()
self.branch2 = nn.Sequential(
nn.Conv2d(input_c if self.stride>1 else branch_features,branch_features,kernel_size=1,stride=1,padding=0,bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True),
self.depthwise_conv(branch_features,branch_features,kernel_s=3,stride=self.stride,padding=1),
nn.BatchNorm2d(branch_features),
nn.Conv2d(branch_features,branch_features,kernel_size=1,stride=1,padding=0,bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True)
)
@staticmethod
def depthwise_conv(input_c:int,output_c:int,kernel_s:int,stride:int=1,padding:int=0,bias:bool=False)->nn.Conv2d:
return nn.Conv2d(in_channels=input_c,out_channels=output_c,kernel_size=kernel_s,
stride=stride,padding=padding,bias=bias,groups=input_c)
def forward(self,x:Tensor)->Tensor:
if self.stride==1:
x1,x2 = x.chunk(2,dim=1)
out = torch.cat((x1,self.branch2(x2)),dim=1)
else:
out = torch.cat((self.branch1(x),self.branch2(x)),dim=1)
out = channel_shuffle(out,2)
return out
class ShuffleNetV2(nn.Module):
def __init__(self,
stages_repeats:List[int],
stages_out_channels:List[int],
num_classes:int=1000,
inverted_residual:Callable[...,nn.Module]=InvertedResidual):
super(ShuffleNetV2,self).__init__()
if len(stages_repeats)!=3:
raise ValueError("expected stages_repeats as list of 3 positive ints")
if len(stages_out_channels)!=5:
raise ValueError("expected stages_out_channels as list of 5 positive ints")
self._stage_out_channels = stages_out_channels
# input RGB image
input_channels = 3
output_channels = self._stage_out_channels[0]
self.conv1 = nn.Sequential(
nn.Conv2d(input_channels,output_channels,kernel_size=3,stride=2,padding=1,bias=False),
nn.BatchNorm2d(output_channels),
nn.ReLU(inplace=True)
)
input_channels = output_channels
self.maxpool = nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
# Static annotations for mypy
self.stage2: nn.Sequential
self.stage3: nn.Sequential
self.stage4: nn.Sequential
stage_names = ["stage{}".format(i) for i in [2,3,4]]
for name, repeats, output_channels in zip(stage_names,stages_repeats,self._stage_out_channels[1:]):
seq = [inverted_residual(input_channels,output_channels,2)]
for i in range(repeats-1):
seq.append(inverted_residual(output_channels,output_channels,1))
setattr(self,name,nn.Sequential(*seq))
input_channels = output_channels
output_channels = self._stage_out_channels[-1]
self.conv5 = nn.Sequential(
nn.Conv2d(input_channels,output_channels,kernel_size=1,stride=1,padding=0,bias=False),
nn.BatchNorm2d(output_channels),
nn.ReLU(inplace=True)
)
self.fc = nn.Linear(output_channels,num_classes)
def _forward_impl(self,x:Tensor)->Tensor:
x = self.conv1(x)
x = self.maxpool(x)
x = self.stage2(x)
x = self.stage3(x)
x = self.stage4(x)
x = self.conv5(x)
x = x.mean([2,3])
x = self.fc(x)
return x
def forward(self,x:Tensor)->Tensor:
return self._forward_impl(x)
def shufflenet_v2_x0_5(num_classes=1000):
model = ShuffleNetV2(stages_repeats=[4,8,4],stages_out_channels=[24,48,96,192,1024],num_classes=num_classes)
return model
def shufflenet_v2_x1_0(num_classes=1000):
model = ShuffleNetV2(stages_repeats=[4,8,4],stages_out_channels=[24,116,232,464,1024],num_classes=num_classes)
return model
def shufflenet_v2_x1_5(num_classes=1000):
model = ShuffleNetV2(stages_repeats=[4,8,4],stages_out_channels=[24,176,352,704,1024],num_classes=num_classes)
return model
def shufflenet_v2_x2_0(num_classes=1000):
model = ShuffleNetV2(stages_repeats=[4,8,4],stages_out_channels=[24,244,488,976,2048],=num_classes)
return model2 EfficientNet V3
2.1 网络结构
亮点:同时探索了输入分辨率,网络的深度、宽度的影响
- 增加深度能提取到更多、更复杂的特征,但会面临梯度消失、训练困难的问题
- 增加宽度能获得更高细粒度的特征,更容易训练,但很难学习到更深层次的特征
- 增加输入网络的图像的分辨率能潜在地获得更高细粒度地特征,但准确率增益会减小,并且大分辨率图像会增加计算量
- 如果同时增加深度,宽度和输入图像的分辨率,就有可能会达到更好的效果

EfficientNet网络的结构是通过网络搜索技术得到的
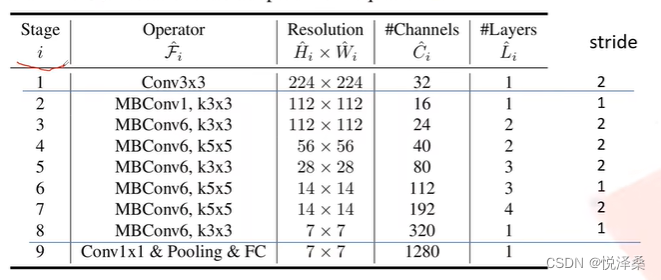
MBConv:

- 先用1*1卷积升维,卷积核个数是输入channel的n倍
- n=1时,不用1*1卷积,即stage2的MBConv结构都没有用于升维的1*1卷积
- 当且仅当输入特征矩阵与输出特征矩阵的shape相同时,shortcut连接才存在
SE模块:

SE模块由一个全局平均池化和两个全连接层组成,第一个全连接层的节点个数时输入该MBConv特征矩阵的1/4,且使用Swish激活函数,第二个全连接层节点个数为DW卷积层输出的特征矩阵的channels,且使用Sigmoid激活函数。
B0到B7的网络参数设置:
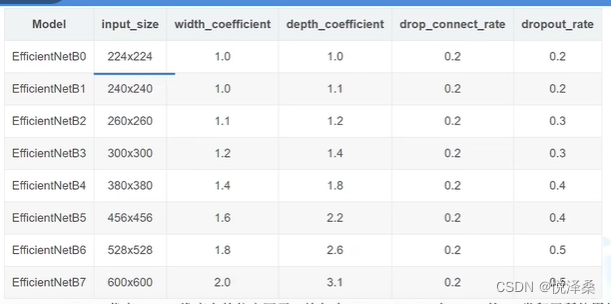
效果:
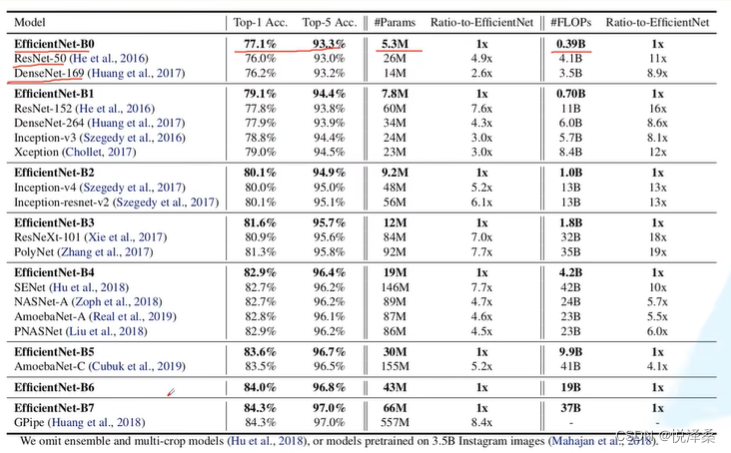
实际体验:准确率高,参数少,但占用GPU显存较多
2.2 基于PyTorch搭建EfficientNet V3
# EfficientNet V3
def _make_divisible(ch,divisor=8,min_ch=None):
if min_ch is None:
min_ch = divisor
new_ch = max(min_ch,int(ch+divisor/2)//divisor*divisor)
if new_ch<0.9*ch:
new_ch += divisor
return new_ch
def drop_path(x, drop_prob: float = 0., training: bool = False):
if drop_prob==0. or not training:
return x
keep_prob = 1-drop_prob
shape = (x.shape[0],)+(1,)*(x.ndim-1) # 适用于多种维度
random_tensor = keep_prob+torch.rand(shape,dtype=x.dtype,device=x.device)
random_tensor.floor_()
output = x.div(keep_prob)*random_tensor
return output
class DropPath(nn.Module):
def __init__(self,drop_prob=None):
super(DropPath,self).__init__()
self.drop_prob = drop_prob
def forward(self,x):
return drop_path(x,self.drop_prob,self.training)
class ConvBNActivation(nn.Sequential):
def __init__(self,
in_planes:int,
out_planes:int,
kernel_size:int=3,
stride:int=1,
groups:int=1,
norm_layer:Optional[Callable[..., nn.Module]]=None,
activation_layer:Optional[Callable[...,nn.Module]]=None):
padding=(kernel_size-1)//2
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if activation_layer is None:
activation_layer = nn.SiLU
super(ConvBNActivation, self).__init__(nn.Conv2d(in_channels=in_planes,
out_channels=out_planes,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups,
bias=False),
norm_layer(out_planes),
activation_layer())
class SqueezeExcitation(nn.Module):
def __init__(self,
input_c:int,
expand_c:int,
squeeze_factor:int=4):
super(SqueezeExcitation,self).__init__()
squeeze_c = input_c//squeeze_factor
self.fc1 = nn.Conv2d(expand_c,squeeze_c, 1)
self.ac1 = nn.SiLU()
self.fc2 = nn.Conv2d(squeeze_c,expand_c,1)
self.ac2 = nn.Sigmoid()
def forward(self,x:Tensor)->Tensor:
scale = F.adaptive_avg_pool2d(x,output_size=(1,1))
scale = self.fc1(scale)
scale = self.ac1(scale)
scale = self.fc2(scale)
scale = self.ac2(scale)
return scale*x
class InvertedResidualConfig:
def __init__(self,
kernel:int, # 3or5
input_c:int,
out_c:int,
expanded_ratio:int, # 1or6
stride:int, # 1or2
use_se:bool, # True
drop_rate:float,
index:str, # 1a,2a,2b...
width_coefficient:float):
self.input_c = self.adjust_channels(input_c,width_coefficient)
self.kernel = kernel
self.expanded_c = self.input_c*expanded_ratio
self.out_c = self.adjust_channels(out_c,width_coefficient)
self.use_se = use_se
self.stride = stride
self.drop_rate = drop_rate
self.index = index
@staticmethod
def adjust_channels(channels:int,width_coefficient:float):
return _make_divisible(channels*width_coefficient,8)
class InvertedResidual(nn.Module):
def __init__(self,cnf:InvertedResidualConfig,norm_layer:Callable[...,nn.Module]):
super(InvertedResidual,self).__init__()
if cnf.stride not in [1,2]:
raise ValueError("illegal stride value.")
self.use_res_connect = (cnf.stride==1andcnf.input_c==cnf.out_c)
layers = OrderedDict()
activation_layer = nn.SiLU
# expand
if cnf.expanded_c!=cnf.input_c:
layers.update({"expand_conv":ConvBNActivation(cnf.input_c,
cnf.expanded_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=activation_layer)})
# depthwise
layers.update({"dwconv":ConvBNActivation(cnf.expanded_c,
cnf.expanded_c,
kernel_size=cnf.kernel,
stride=cnf.stride,
groups=cnf.expanded_c,
norm_layer=norm_layer,
activation_layer=activation_layer)})
if cnf.use_se:
layers.update({"se":SqueezeExcitation(cnf.input_c,cnf.expanded_c)})
# project
layers.update({"project_conv":ConvBNActivation(cnf.expanded_c,
cnf.out_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=nn.Identity)})
self.block = nn.Sequential(layers)
self.out_channels = cnf.out_c
self.is_strided = cnf.stride>1
# 只有在使用shortcut连接时才使用dropout层
if self.use_res_connect and cnf.drop_rate>0:
self.dropout = DropPath(cnf.drop_rate)
else:
self.dropout = nn.Identity()
def forward(self,x:Tensor)->Tensor:
result = self.block(x)
result = self.dropout(result)
if self.use_res_connect:
result += x
return result
class EfficientNet(nn.Module):
def __init__(self,
width_coefficient:float,
depth_coefficient:float,
num_classes:int=1000,
dropout_rate:float=0.2,
drop_connect_rate:float=0.2,
block:Optional[Callable[...,nn.Module]]=None,
norm_layer:Optional[Callable[...,nn.Module]]=None):
super(EfficientNet,self).__init__()
# kernel_size,in_channel,out_channel,exp_ratio,strides,use_SE,drop_connect_rate,repeats
default_cnf = [[3,32,16,1,1,True,drop_connect_rate,1],
[3,16,24,6,2,True,drop_connect_rate,2],
[5,24,40,6,2,True,drop_connect_rate,2],
[3,40,80,6,2,True,drop_connect_rate,3],
[5,80,112,6,1,True,drop_connect_rate,3],
[5,112,192,6,2,True,drop_connect_rate,4],
[3,192,320,6,1,True,drop_connect_rate,1]]
def round_repeats(repeats):
return int(math.ceil(depth_coefficient*repeats))
if block is None:
block = InvertedResidual
if norm_layer is None:
norm_layer = partial(nn.BatchNorm2d,eps=1e-3,momentum=0.1)
adjust_channels = partial(InvertedResidualConfig.adjust_channels,width_coefficient=width_coefficient)
# build inverted_residual_setting
bneck_conf = partial(InvertedResidualConfig,width_coefficient=width_coefficient)
b = 0
num_blocks = float(sum(round_repeats(i[-1]) for i in default_cnf))
inverted_residual_setting = []
for stage,args in enumerate(default_cnf):
cnf = copy.copy(args)
for i in range(round_repeats(cnf.pop(-1))):
if i>0:
cnf[-3] = 1
cnf[1] = cnf[2]
cnf[-1] = args[-2]*b/num_blocks #更新dropout
index = str(stage+1)+chr(i+97) #1a,2a,2b...
inverted_residual_setting.append(bneck_conf(*cnf,index))
b += 1
# create layers
layers = OrderedDict()
# first conv
layers.update({"stem_conv":ConvBNActivation(in_planes=3,
out_planes=adjust_channels(32),
kernel_size=3,
stride=2,
norm_layer=norm_layer)})
# building inverted residual blocks
for cnf in inverted_residual_setting:
layers.update({cnf.index: =block(cnf,norm_layer)})
# build top
last_conv_input_c = inverted_residual_setting[-1].out_c
last_conv_output_c = adjust_channels(1280)
layers.update({"top":ConvBNActivation(in_planes=last_conv_input_c,
out_planes=last_conv_output_c,
kernel_size=1,
norm_layer=norm_layer)})
self.features = nn.Sequential(layers)
self.avgpool = nn.AdaptiveAvgPool2d(1)
classifier = []
if dropout_rate>0:
classifier.append(nn.Dropout(p=dropout_rate,inplace=True))
classifier.append(nn.Linear(last_conv_output_c,num_classes))
self.classifier = nn.Sequential(*classifier)
# 权重初始化
for m in self.modules():
if isinstance(m,nn.Conv2d):
nn.init.kaiming_normal_(m.weight,mode="fan_out")
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m,nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m,nn.Linear):
nn.init.normal_(m.weight,0,0.01)
nn.init.zeros_(m.bias)
def _forward_impl(self,x:Tensor)->Tensor:
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x,1)
x = self.classifier(x)
return x
def forward(self,x:Tensor)->Tensor:
return self._forward_impl(x)
def efficientnet_b0(num_classes=1000):
# 224x224
return EfficientNet(width_coefficient=1.0,depth_coefficient=1.0,dropout_rate=0.2,num_classes=num_classes)
def efficientnet_b1(num_classes=1000):
# 240x240
return EfficientNet(width_coefficient=1.0,depth_coefficient=1.1,dropout_rate=0.2,num_classes=num_classes)
def efficientnet_b2(num_classes=1000):
# 260x260
return EfficientNet(width_coefficient=1.1,depth_coefficient=1.2,dropout_rate=0.3,num_classes=num_classes)
def efficientnet_b3(num_classes=1000):
# 300x300
return EfficientNet(width_coefficient=1.2,depth_coefficient=1.4,dropout_rate=0.3,num_classes=num_classes)
def efficientnet_b4(num_classes=1000):
# 380x380
return EfficientNet(width_coefficient=1.4,depth_coefficient=1.8,dropout_rate=0.4,num_classes=num_classes)
def efficientnet_b5(num_classes=1000):
# 456x456
return EfficientNet(width_coefficient=1.6,depth_coefficient=2.2,dropout_rate=0.4,num_classes=num_classes)
def efficientnet_b6(num_classes=1000):
# 528x528
return EfficientNet(width_coefficient=1.8,depth_coefficient=2.6,dropout_rate=0.5,num_classes=num_classes)
def efficientnet_b7(num_classes=1000):
# 600x600
return EfficientNet(width_coefficient=2.0,depth_coefficient=3.1,dropout_rate=0.5,num_classes=num_classes)3 Transformer里的multi-head self-attention
Transformer:最开始是针对NLP领域提出的,替代了之前的无法实现并行、记忆长度短的时序网络。在没有硬件限制的情况下,Transformer可以做到无限长度的记忆。
进行点乘得到的数值很大,当经过softmax后,梯度会变得很小
self-attention:
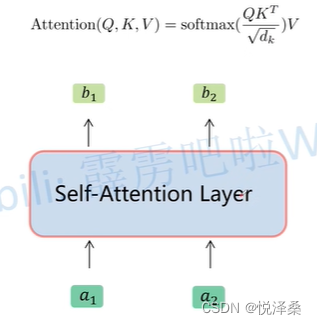
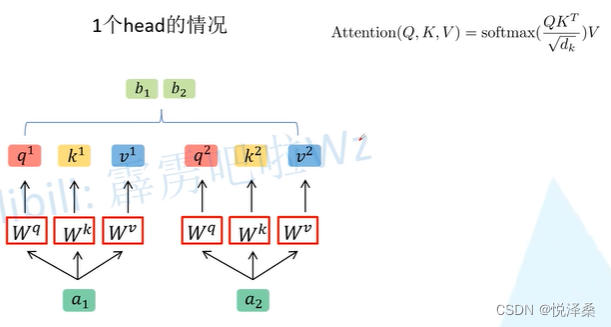
multi-head self-attention:
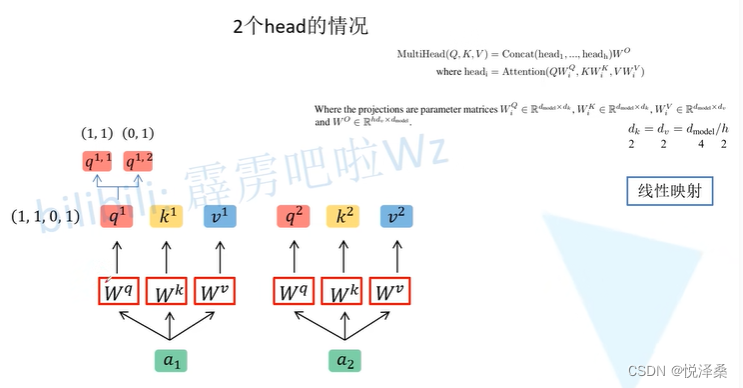
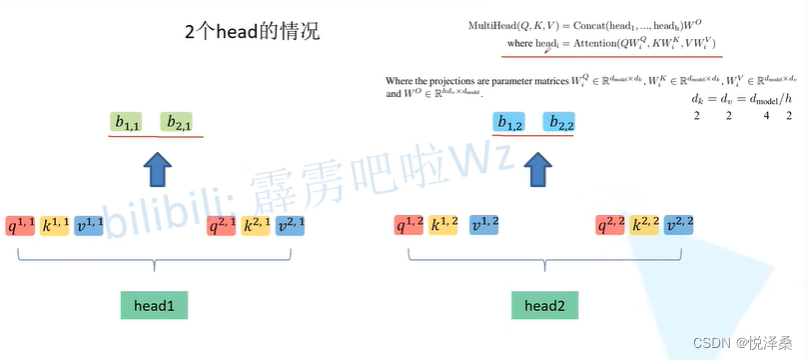
对head进行拼接:

之后要对拼接后的矩阵进行处理,保证输入输出的向量长度保持不变。多头注意力机制能够联合来自不同head部分学习得到的信息,生成更有意义的特征,多头的本质是多个独立的attention计算,有集成的作用,可以防止过拟合。
Part2 代码练习
1 使用VGG模型进行猫狗大战
1.1 调用库
import numpy as np
import matplotlib.pyplot as plt
import os
import torch
import torch.nn as nn
import torchvision
from torchvision import models,transforms,datasets
import time
import json
# 判断是否存在GPU设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print('Using gpu: %s '%torch.cuda.is_available())1.2 下载数据并解压
# 下载数据
! wget http://fenggao-image.stor.sinaapp.com/dogscats.zip
! unzip dogscats.zip1.3 数据处理
# 数据处理
normalize = transforms.Normalize(mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225])
vgg_format = transforms.Compose([transforms.CenterCrop(224),transforms.ToTensor(),normalize])
data_dir = './dogscats'
dsets = {x:datasets.ImageFolder(os.path.join(data_dir,x),vgg_format) for x in ['train','valid']}
dset_sizes = {x:len(dsets[x]) for x in ['train','valid']}
dset_classes = dsets['train'].classes
# 查看dsets的一些属性
print(dsets['train'].classes)
print(dsets['train'].class_to_idx)
print(dsets['train'].imgs[:5])
print('dset_sizes: ', dset_sizes)
loader_train = torch.utils.data.DataLoader(dsets['train'], batch_size=64, shuffle=True, num_workers=6)
loader_valid = torch.utils.data.DataLoader(dsets['valid'], batch_size=5, shuffle=False, num_workers=6)
count = 1
for data in loader_valid:
print(count,end='\n')
if count==1:
inputs_try,labels_try = data
count+=1
print(labels_try)
print(inputs_try.shape)
# 显示图片
def imshow(inp, title=None):
inp = inp.numpy().transpose((1,2,0))
mean = np.array([0.485,0.456,0.406])
std = np.array([0.229,0.224,0.225])
inp = np.clip(std*inp+mean,0,1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001)
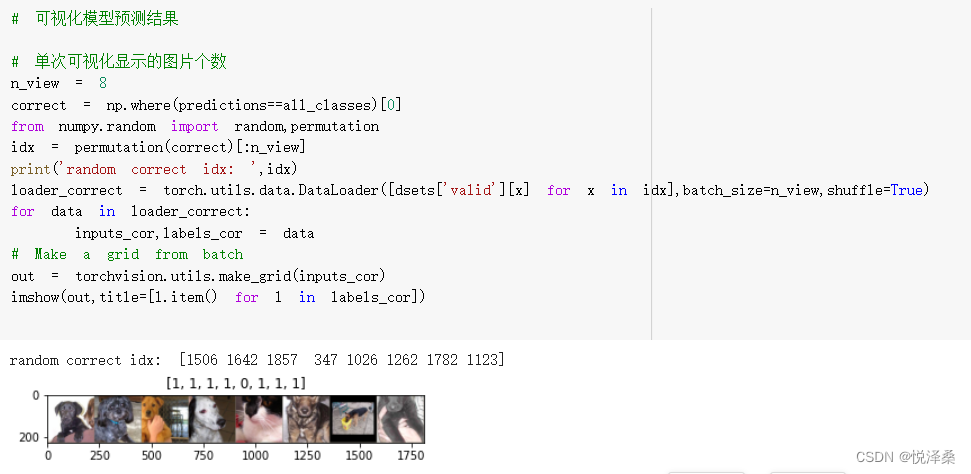
# 显示labels_try的5张图片,即valid里第一个batch的5张图片
out = torchvision.utils.make_grid(inputs_try)
imshow(out,title=[dset_classes[x] for x in labels_try])
1.4 创建模型
# 创建模型
model_vgg = models.vgg16(pretrained=True)
with open('./imagenet_class_index.json') as f:
class_dict = json.load(f)
dic_imagenet = [class_dict[str(i)][1] for i in range(len(class_dict))]
inputs_try,labels_try = inputs_try.to(device),labels_try.to(device)
model_vgg = model_vgg.to(device)
outputs_try = model_vgg(inputs_try)
print(outputs_try)
print(outputs_try.shape)
m_softm = nn.Softmax(dim=1)
probs = m_softm(outputs_try)
vals_try,pred_try = torch.max(probs,dim=1)
print('prob sum: ',torch.sum(probs,1))
print('vals_try: ',vals_try)
print('pred_try: ',pred_try)
print([dic_imagenet[i] for i in pred_try.data])
imshow(torchvision.utils.make_grid(inputs_try.data.cpu()),
title=[dset_classes[x] for x in labels_try.data.cpu()])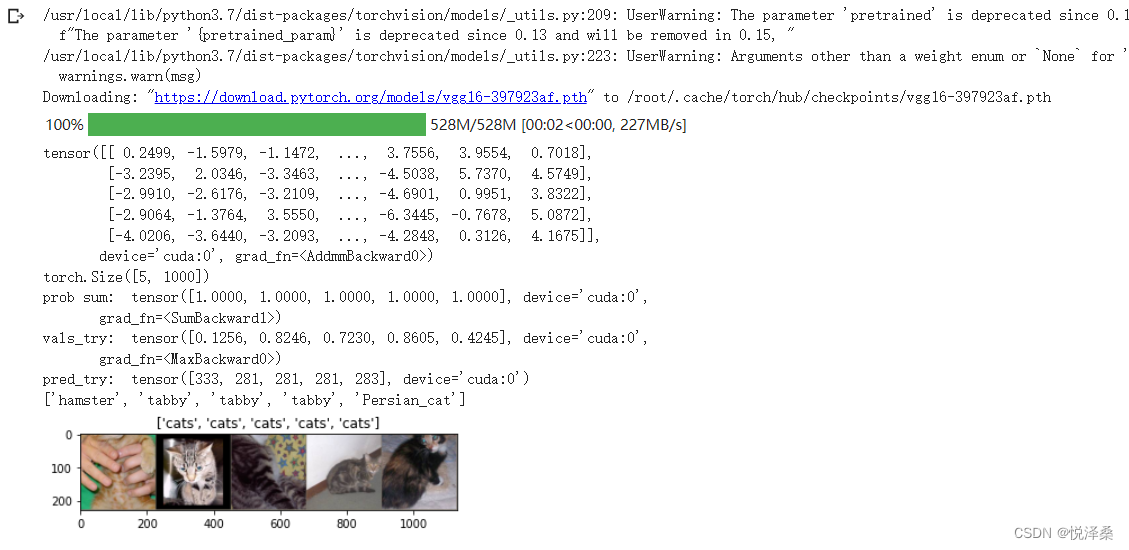
# 修改最后一层,冻结前面层的参数
print(model_vgg)
model_vgg_new = model_vgg;
for param in model_vgg_new.parameters():
param.requires_grad = False
model_vgg_new.classifier._modules['6'] = nn.Linear(4096,2)
model_vgg_new.classifier._modules['7'] = torch.nn.LogSoftmax(dim=1)
model_vgg_new = model_vgg_new.to(device)
print(model_vgg_new.classifier)展示模型:
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=2, bias=True)
(7): LogSoftmax(dim=1)
)1.5 训练与测试
# 训练并测试全连接层
criterion = nn.NLLLoss()
# 学习率
lr = 0.001
# 随机梯度下降
optimizer_vgg = torch.optim.SGD(model_vgg_new.classifier[6].parameters(),lr=lr)
def train_model(model,dataloader,size,epochs=1,optimizer=None):
model.train()
for epoch in range(epochs):
running_loss = 0.0
running_corrects = 0
count = 0
for inputs,classes in dataloader:
inputs = inputs.to(device)
classes = classes.to(device)
outputs = model(inputs)
loss = criterion(outputs,classes)
optimizer = optimizer
optimizer.zero_grad()
loss.backward()
optimizer.step()
_,preds = torch.max(outputs.data,1)
# statistics
running_loss += loss.data.item()
running_corrects += torch.sum(preds==classes.data)
count += len(inputs)
print('Training: No. ',count,' process ... total: ',size)
epoch_loss = running_loss/size
epoch_acc = running_corrects.data.item()/size
print('Loss: {:.4f} Acc: {:.4f}'.format(epoch_loss,epoch_acc))
# 模型训练
train_model(model_vgg_new,loader_train,size=dset_sizes['train'],epochs=1,optimizer=optimizer_vgg) 
# 测试
def test_model(model,dataloader,size):
model.eval()
predictions = np.zeros(size)
all_classes = np.zeros(size)
all_proba = np.zeros((size,2))
i = 0
running_loss = 0.0
running_corrects = 0
for inputs,classes in dataloader:
inputs = inputs.to(device)
classes = classes.to(device)
outputs = model(inputs)
loss = criterion(outputs,classes)
_,preds = torch.max(outputs.data,1)
# statistics
running_loss += loss.data.item()
running_corrects += torch.sum(preds==classes.data)
predictions[i:i+len(classes)] = preds.to('cpu').numpy()
all_classes[i:i+len(classes)] = classes.to('cpu').numpy()
all_proba[i:i+len(classes),:] = outputs.data.to('cpu').numpy()
i += len(classes)
print('Testing: No. ',i,' process ... total: ',size)
epoch_loss = running_loss/size
epoch_acc = running_corrects.data.item()/size
print('Loss: {:.4f} Acc: {:.4f}'.format(epoch_loss,epoch_acc))
return predictions,all_proba,all_classes
predictions,all_proba,all_classes = test_model(model_vgg_new,loader_valid,size=dset_sizes['valid'])

1.6 可视化
2 AI艺术鉴赏挑战赛题
代码链接:
此处尝试使用resnet进行,主要代码如下:
num_workers = 2
batch_size = 32
net = models.resnet50(pretrained=True)
net.fc = nn.Linear(net.fc.in_features,49,bias=True)
net = net.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(),lr=0.001)
train_data = PDataset(train_dir,transform=transform)
train_dataloader = DataLoader(dataset=train_data,shuffle=True,num_workers=num_workers,batch_size=batch_size,pin_memory=True)
for epoch in range(30): # 重复多轮训练
for i,(img,label) in enumerate(train_dataloader):
img = img.to(device)
labels = label.to(device)
# 优化器梯度归零
optimizer.zero_grad()
# 正向传播+反向传播+优化
outputs = net(img)
loss = criterion(outputs,labels)
loss.backward()
optimizer.step()
# 输出统计信息
print('Epoch: %d loss: %.3f' %(epoch+1,loss.item()))
print('Finished Training')
import pandas as pd
test_imgs = os.listdir(test_dir)
id_list = []
label_list = []
for img in test_imgs:
id = img.split('.')[0]
img = Image.open(test_dir+img).convert('RGB')
img = transform(img).to(device)
img = img.unsqueeze(0)
label = net(img)
i = 0
# print(label[0])
max = label[0][0]
max_id = 0
for value in label[0]:
if value > max:
max = value
max_id = i
i+=1
print(max_id)
id_list.append(id)
label_list.append(max_id)
dataframe = pd.DataFrame(
{'id': id_list, 'nameid': label_list})
dataframe.to_csv(r"results.csv", sep=',')resnet50的训练结果:

生成csv并提交后的判定结果:

其中,results1是resnet50训练15轮的结果,result2是resnet50训练50轮的结果,效果都特别差。。。。这可能和训练轮次过少有关,因为该赛题中有49个分类,属于多分类问题,往往需要更好的网络结构和更小的loss才能达到理想的效果。除此之外,根据提供的材料来看,训练集和测试集均趋向于长尾分布,这容易导致训练模型把所有图片都归为同一类的情况,并且观察csv文件发现,绝大多数图片都被归为了3或16号类,而3号和16号确实含有最多的样本量,说明模型投机取巧的现象真的发生了。
接下来本人学习了奖金赛第一名的选手提供的代码方案,这里使用的主干网络为EfficientNet B3,并且记录下了5组不同loss下的测试结果,使用投票的方式决定每个图片属于哪一类,我认为这种投票机制是该代码方案的亮点,它可以综合5个训练成果的优点,取长补短,很巧妙,并且这种主干网络参数量较小,主打运算效率,不会因为评判5次结果而耗费大量时间。
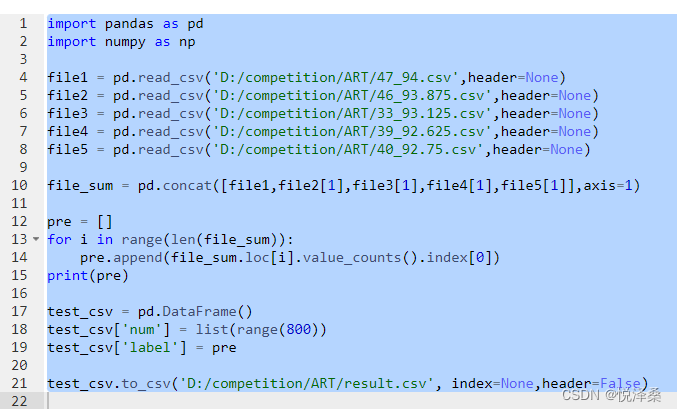
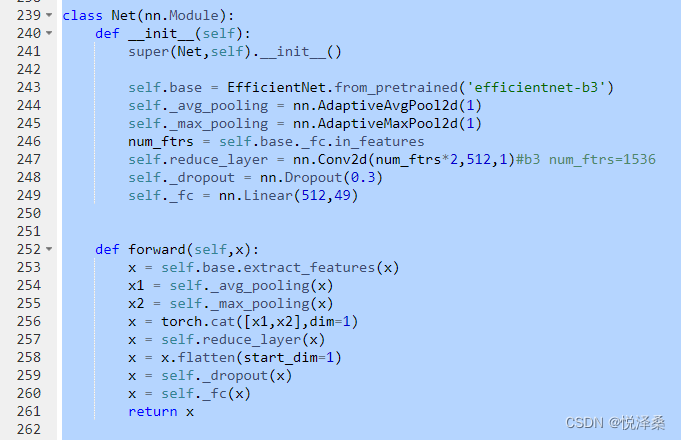
再观察第二名和第三名的代码方案,发现他们也使用了这种投票机制,其中第二名采用resnet200作为主干网络,第三名分别使用了efficientnet b3和resnext50两种网络。个人认为,当主干网络结构简洁、计算效率高时,可以使用这种投票机制提高识别准确率。