上一篇的文章我们分享了轻量化网络的第一次出色的尝试——MobileNet和MobileNet v2,这一次的文章将分享另一次轻量化网络的尝试——ShuffleNet和ShuffleNet v2,从名字来看就知道它做了一些清洗方面的工作,所以接下来来开始我们的正题——ShuffleNet和ShuffleNet v2。
ShuffleNet主要有两个方面的工作:
- 点态群卷积——pointwise group convolution
- 通道混洗——channel shuffle operation
点态群卷积——pointwise group convolution
实际上在AlexNet就有卷积分组的先例,但是并没有引起伙伴们的注意,毕竟当时AlexNet的卷积分组初衷是在双GPU上死磕网络。在ResNeXt中主要是对3x3的卷积做分组操作,但是在ShuffleNet中,作者是对1x1的卷积做分组操作,因为作者认为1x1的卷积操作的计算量不可忽视。具体的卷积操作可以参见ShuffleNet的构成单元。
通道混洗——channel shuffle operation
话不多说,先来看图:
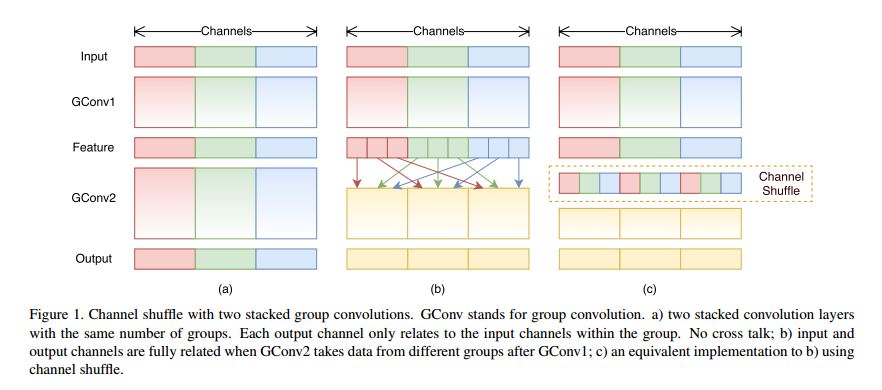
【Figure 1解读】 channel shuffle operation的发展历程:
当我们把卷积操作分组了以后,就如图(a)中所示,每一组卷积各卷各的,相互不通信,谁也不知道别的组卷成了什么样,这就产生了边界效应,显而易见这就丢失了很多信息,尤其是通道间、组间相关性,所以不得不进行组间通信(cross talk);
最直接的想法就是(b)图,我们让Feature层的红块、绿块、蓝块各分成3小块,我们就暂且叫红1-3,绿1-3和蓝1-3;我们想让它们组间通信,只要把不同颜色的重新分组,每组都变成红+绿+蓝就可以了,如图(b)所示让红2和红3去绿组和蓝组交流就可以了;
那我们落实到更普遍的情况是怎样的呢?就是图(c)。具体通道混洗步骤如下:
- 有g x n个输出通道 ,Reshape为(g,n);
- 转置为(n,g);
- 平坦化,再分回g组作为下一层的输入;
ShuffleNet的构成单元
我们来看一下ShuffleNet的构成单元(ShuffleNet Unit):

【Figure 2解读】(a)、(b)和(c)都是残差结构,不同之处是:
(a) 卷积使用普通的1x1的点态卷积和3x3的深度卷积;简单的线性相加(Add);
(b) 在(a)的基础上,普通1x1点态卷积替换成1x1的点态分组卷积,3x3的深度卷积不变,并且做了通道混洗;此外,减少了一次激活Relu的非线性操作;简单的线性相加(Add);
(c) 在(b)的基础上,仍使用1x1的点态分组卷积和3x3的深度卷积,但是3x3的深度卷积步长改为2(实现降采样),同时在另一条之路上使用3x3全局平均池化(AVG Pool),步长为2;在输出是采用的是Concat,通道级联;
ShuffleNet的整体网络结构
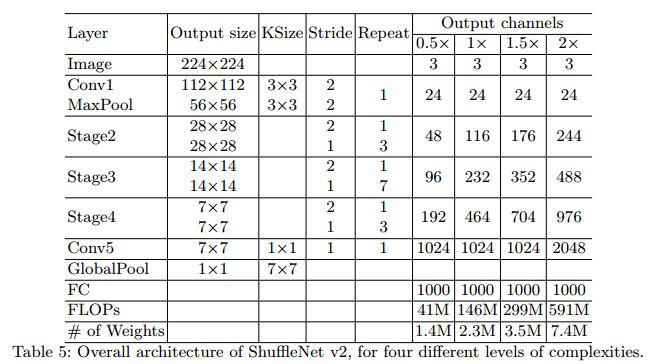
我们再来看一下ShuffleNet的整体网络结构,如下图所示。
ShuffleNet对于卷积操作大体分了四个阶段:步长为2的做降采样,步长为1的保持Feature Map大小不变,重复不同次数做卷积;并且取了不同的g值;使用了全局平均池化和全连接层;

此外,为了要控制网络所需要的复杂性,提出了一个通道数应用比例因子——比例因子s,记作ShuffleNet sx。可以看出:更宽的通道对于小网络尤其重要,受这点启发,作者移除了网络第三阶段的两个结构单元,将节省下来的运算量用来增加网络宽度后,网络性能进一步提高。

ShuffleNet的实验趴
实验一:点态卷积群的实验
详情请见上述比例因子s的实验——Table2。
实验二:通道混洗 vs 通道不混洗

ShuffleNet目的是为多组卷积层提供跨组信息流。上表中比较了通道混洗和不进行通道混洗的操作比较(分组都设为3或8)。从结果易得,性能明显优于同类模型,说明了跨组信息交换的重要性。
实验三:和其他的结构单元的比较

使用一样的整体网络布局,在保持计算复杂度的同时将 ShuffleNet 结构单元分别替换为 VGG-like、ResNet、Xception-like 和 ResNeXt 中的结构单元,使用完全一样训练方法。上表中的结果显示在不同的计算复杂度下,ShuffleNet 始终大大优于其他网络。
实验四:和MobileNet以及其他框架的比较

虽然ShuffleNet是为了轻量级网络设计的,但是当它增加到更大的计算量和复杂性的时候,它的性能同样优异。而在40MFLOPs量级,ShuffleNet仍比MobileNet 错误率低 6.7%。
ShuffleNet的总结
1.采用了点态群卷积和通道混洗两种新的运算方式,在保持精度的同时,大大降低了计算量;
2.在大多数情况下建议选取g=3的分组;(原因:尽管具有较大组号(例如g=4或g=8)的Shufflenet通常具有更好的性能,但我们发现在当前的实现中效率较低)
ShuffleNet v2主要有两个方面的工作:
- 两向基本原则——principles
- 四个实用指南——practical guidelines
- 提出了新的轻量级网络——ShuffleNet v2
这篇ShuffleNet v2一上来先分析了一个问题——是不是准确率和FLOPs(浮点数计算的数量)就可以代表一个网络模型的性能,所以他们做了如图的实验:ShuffleNet v1与MobileNet v2这两个移动端流行网络在GPU/ARM两种平台下的时间消耗分布。结果发现Conv操作也只是占了一部分的运行时间,像Elemwise也占据了很久的时间。

所以问题就来了,评判一个网络模型的性能到底可以用到哪些标准?从这篇ShuffleNet v2整体来看,可以用下述的三个评判标准:准确率(accuracy)、FLOPs、 MAC(memory access cost)。
两个基本原则——principles
首先,应该使用直接的度量(例如:速度)来代替间接的度量(例如:FLOPs)。
第二,应在目标平台上对这种衡量标准进行评估。
四个实用指南——practical guidelines
G1) Equal channel width minimizes memory access cost (MAC).
当输入、输出channels数目相同时,conv计算所需的MAC最为节省。
G2) Excessive group convolution increases MAC.
过多的Group convolution会加大MAC开销。
G3) Network fragmentation reduces degree of parallelism.
网络结构整体的碎片化会减少其可并行优化的程序。
G4) Element-wise operations are non-negligible.
Element-wise操作会消耗较多的时间,不可小视。
高效结构——ShuffleNet v2
简单来说,ShuffleNet v2在ShuffleNet的基础上做了如下的改动:
1.弃用了1x1的GConv,改回了普通的1x1的点态卷积;
2.在module的末尾弃用了线性相加(Add),直接使用了通道级联(Concat);
3.提出了通道分片(Channel Split),将输入的通道分成了两个部分,一部分向下直接传递,另一部分做向后的卷积运算;
4.通道混洗也做了调整,把它放到了Concat的后面,使原信息和计算后的信息做通道间的信息交互,可以说是很精彩的idea了;

【Fig.3解读】ShuffleNet和ShuffleNet v2的Unit结构对比
来整体看一下ShuffleNet v2的网络结构,和ShuffleNet看起来差距不大,但性能优异。
在深度网络的轻量化方面实际上还是有很多方法的,比如说:
1. 改变卷积结构:以MobileNet为例
2. 使用bottleneck结构:以SqueezeNet为例
3. 以低精度浮点数保存:以Deep Compression为例
4. 冗余卷积核剪枝(network pruning)
5. 哈弗曼编码(Huffman Coding)
6. 连接学习(connectivity learning)
我们也会在后续的文章中慢慢补充,所以还请大家多多关注我们的博客!!!谢谢大家一直以来的支持,深度学习网络篇(以分类为主)就要到此告一段落了,接下来是一些其他专题的文章,还请大家多多指教!