1 注意力机制概述
1.1 定义
注意力机制(Attention Mechanism)是深度学习领域中的一种重要技术,特别是在序列模型如自然语言处理(NLP)和计算机视觉中。它使模型能够聚焦于输入数据的重要部分,从而提高整体性能和效率。
1.2 基本原理
-
聚焦关键信息: 注意力机制模仿人类的注意力过程,使模型能夠集中处理输入数据中的关键信息,同时忽略不太相关的部分。
-
权重分配: 通过为输入数据的不同部分分配不同的权重(或注意力分数),模型能够识别最重要的信息。
1.3 应用领域
-
自然语言处理(NLP): 在机器翻译、文本摘要、情感分析等任务中,注意力机制帮助模型关注文本的关键部分。
-
计算机视觉: 在图像分类、目标检测和图像字幕生成等任务中,注意力机制使模型能够专注于图像的关键区域。
-
语音识别: 注意力机制帮助模型关注语音信号的重要部分,提高语音识别的准确性。
1.4 优势
-
提高性能: 通过集中处理重要信息,注意力机制可以提高模型的准确性和效率。
-
提供可解释性: 注意力权重可以用来解释模型的决策过程,增加模型的透明度。
-
灵活性强: 可以与多种模型结构结合,如循环神经网络(RNN)、卷积神经网络(CNN)和Transformer。
2 注意力机制分析
2.1 Encoder-Decoder框架
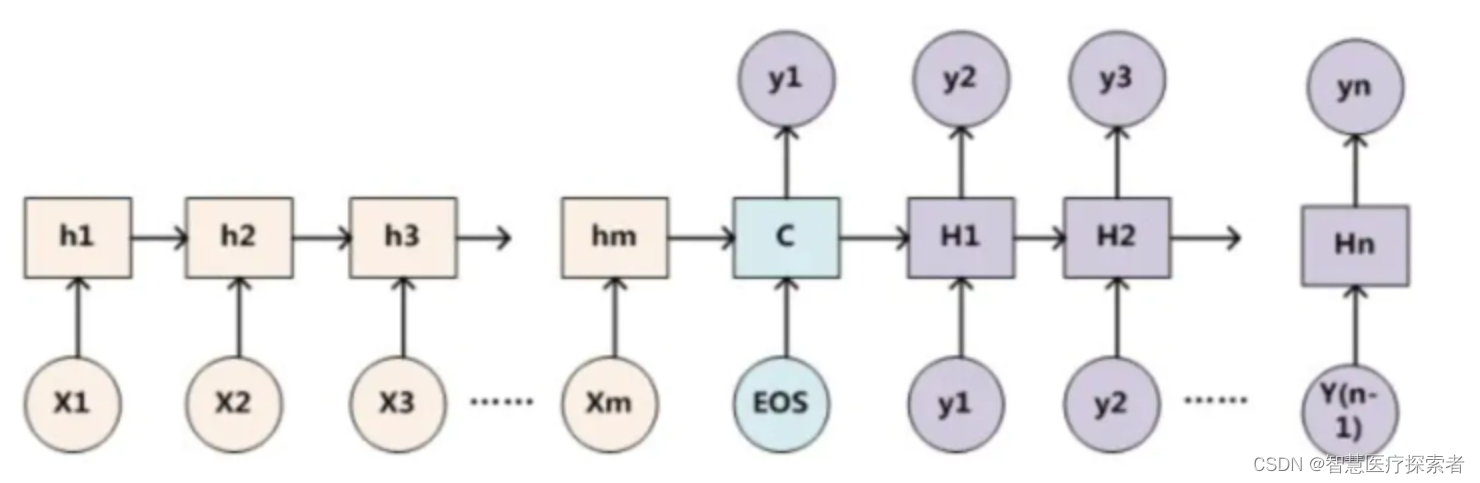
下面基于Encoder-Decoder框架对注意力机制深入分析,Encoder-Decoder框架的原理如下:
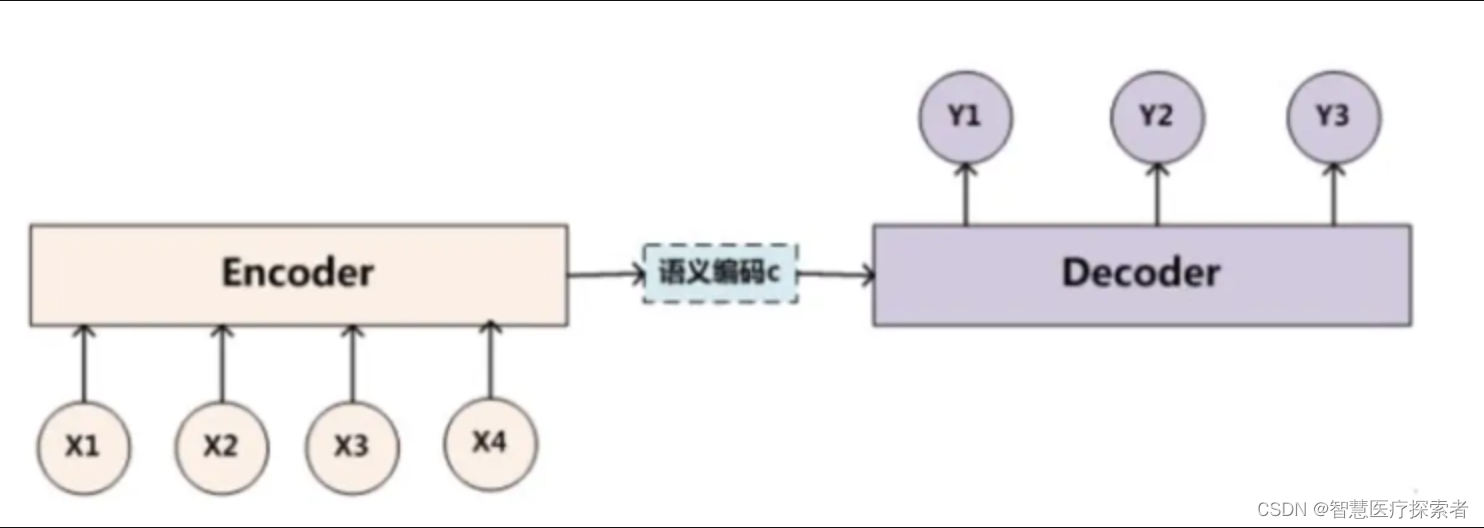
对于句子对<source,target>:
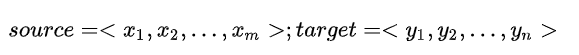
编码器对输入source进行编码,转换成中间语义向量C:
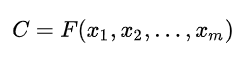
对于解码器Decoder,根据中间语义向量C和当前已生成的历史信息来生成下一时刻要生成的单词:
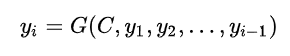
基本的Encoder-Decoder框架没有体现出注意力机制
把Decoder生成拆开来看:
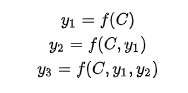
f是非线性变换函数,在生成目标单词时,使用的语义向量C都是一样的,所以,source中任意单词对某个单词y_i来说,影响力都是相同的。
如果输入句子比较短,对于输出影响不是很大,但如果输入句子很长,这时所有的语义都通过一个语义向量C来表示,单词自身的信息会消失,很多细节信息会被丢失,最终的输出也会受到影响,所以要引入注意力机制。
2.2 经典注意力机制
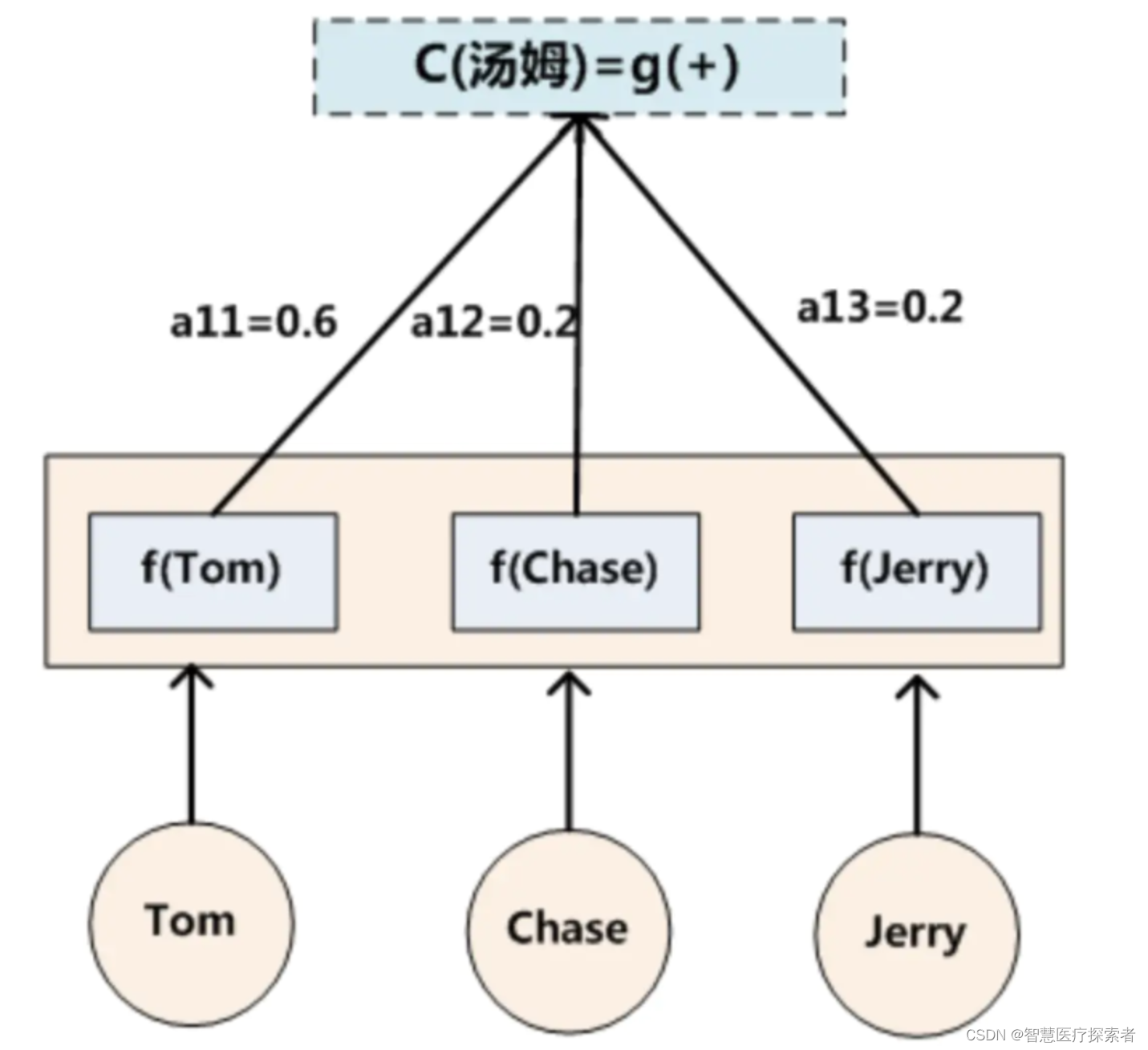
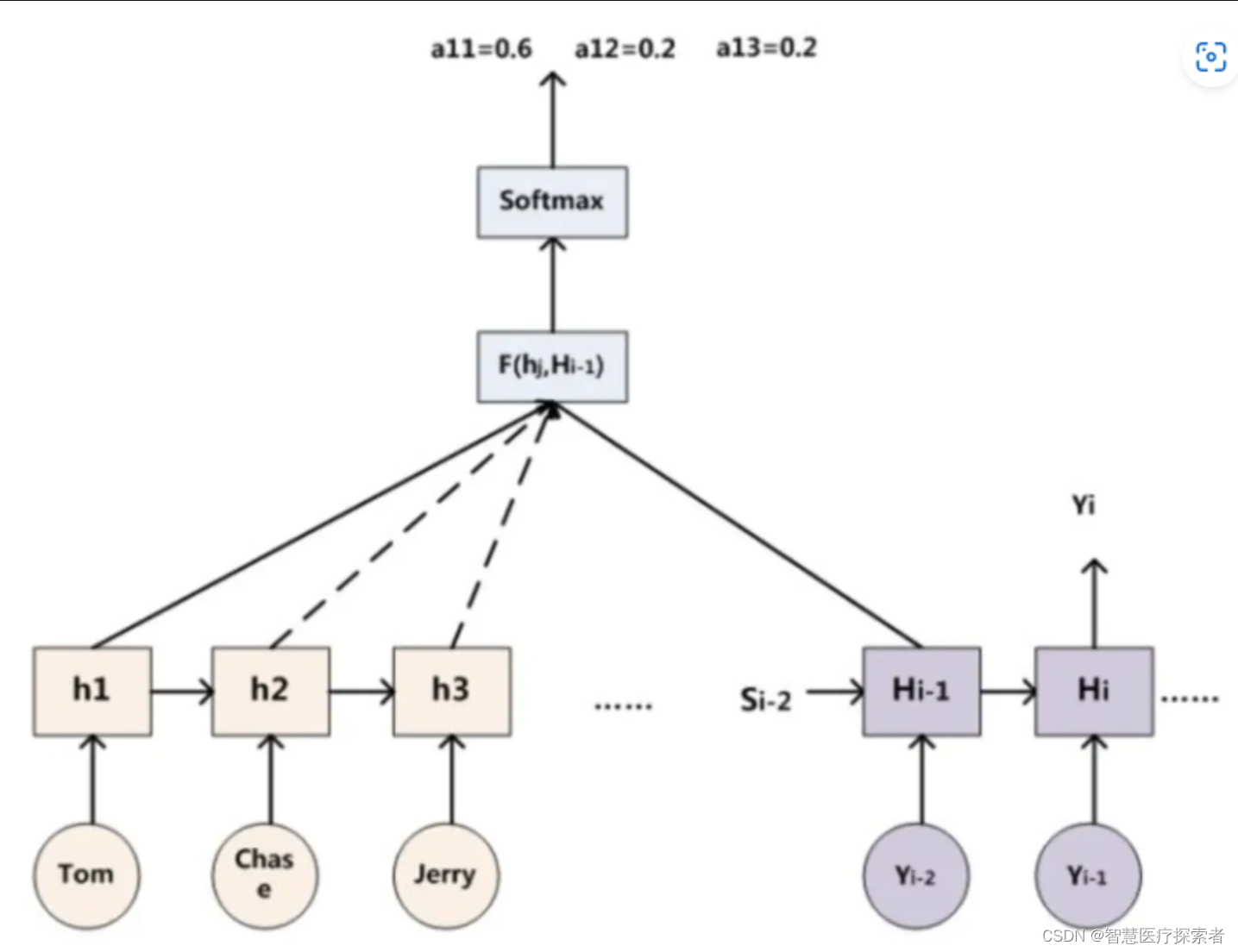
在机器翻译中,比如输入source为Tom chase Jerry。输出想得到中文:汤姆 追逐 杰瑞。在翻译Jerry这个单词时,在普通Encoder-Decoder模型中,source里的每个单词对“杰瑞”贡献是相同的,但这样明显和实际不是很相符,在翻译“杰瑞”的时候,我们更关注的应该是"Jerry",对于另外两个单词,关注的会少一些。
引入Attention模型后,在生成“杰瑞“的时候,会体现出输入source的不同影响程度,比如:
![]()
每个概率代表了翻译当前单词“杰瑞”时注意力分配模型分配给不同英文单词的注意力大小。
在注意力机制中,对于target中每个单词都有一个对应source中单词的注意力概率。
由于注意力模型的加入,原来在生成target单词时候的中间语义C就不再是固定的,而是会根据注意力概率变化的,加入了注意力模型的Encoder-Decoder框架如下:
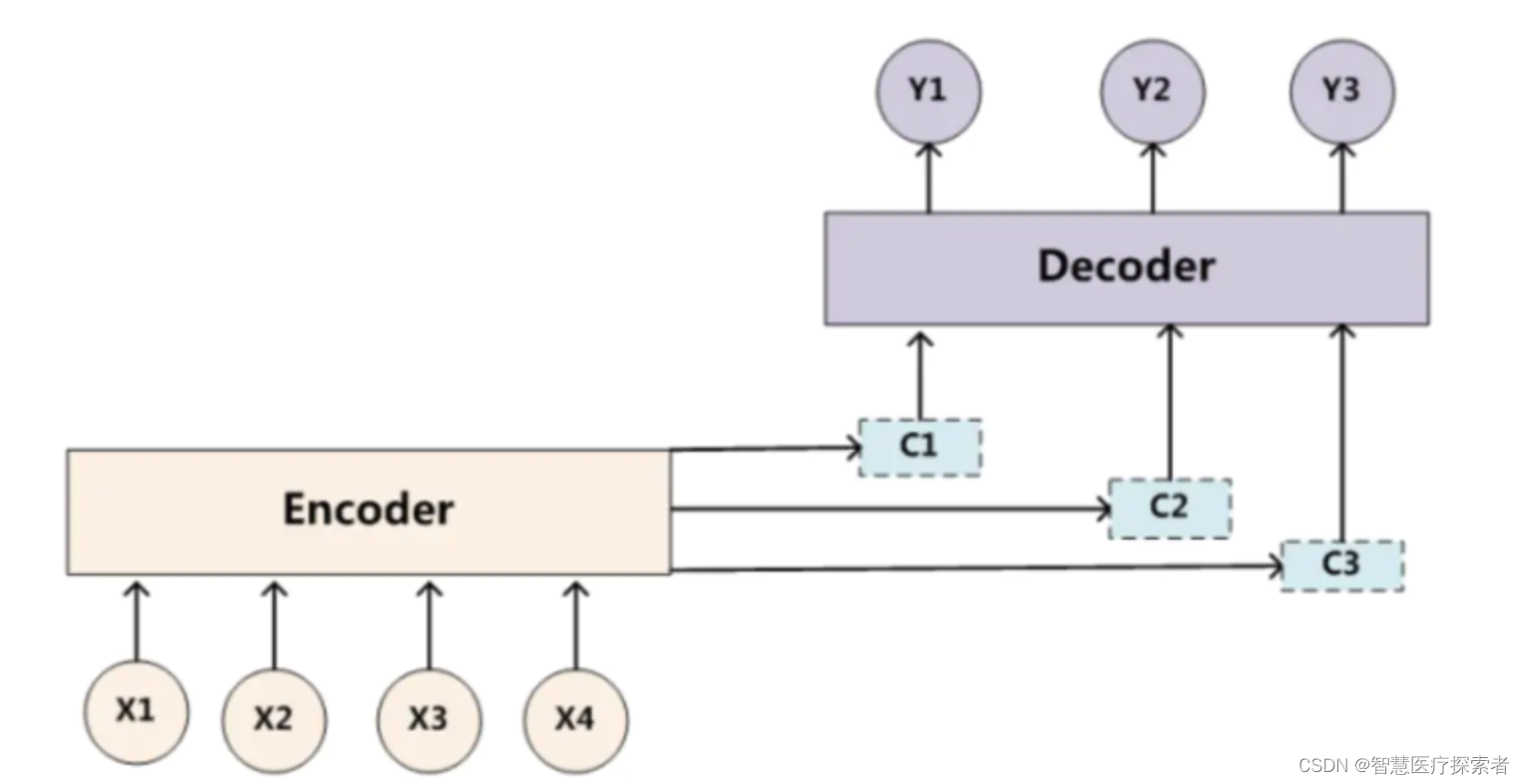
生成target的过程就变成了如下形式:
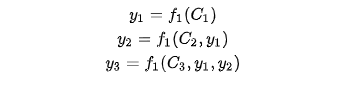
每个可能对应着不同的注意力分配概率分布,比如对于上面的英汉翻译来说,其对应的信息可能如下:
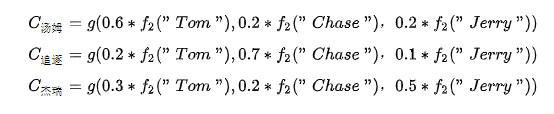
其中,表示Encoder对输入英文单词的某种变换函数, 比如如果Encoder是用RNN模型的话,这个
函数的结果往往是某个时刻输入后隐层节点的状态值。g代表Encoder根据单词的中间表示合成整个句子中间语义表示的变换函数,一般g函数就是对构成元素的加权求和:
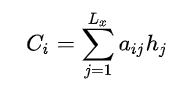
其中,代表输入句子Source的长度,a_i_j代表在Target输出第i个单词时,Source输入第j个单词的注意力分配系数;
代表Source输入句子中第j个单词的语义编码。举例输出汤姆如下:
2.3 注意力分布
注意力分布α就是判断什么信息重要,什么信息不重要,分别赋予不同的权重。
如何计算α:
用X表示输入当输入 N 个向量 :[x1,...,xN],想要从中选出对于目标而言比较重要的信息,需要引入目标任务的表示,称为 查询向量(query vector),此时问题可以转换为考察输入的不同内容和查询向量之间的相关度,也就是对不同内容进行打分,赋予 与当前任务比较相关的部分 更大的权重,再通过一个softmax层得到分布,也就是输入信息的不同部分的权重。
注意力变量z∈[1, N]来表示被选择信息的索引位置,即z=i来表示选择了第i个输入信息,然后计算在给定了q和X的情况下,选择第i个输入信息的概率αi:
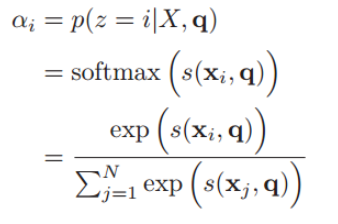
其中αi构成的概率向量就称为注意力分布(Attention Distribution)。s(xi , q)是注意力打分函数,有以下几种形式:
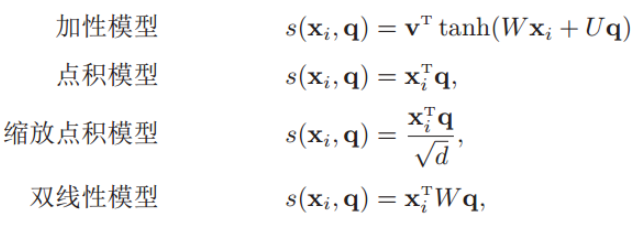
其中W、U和v是可学习的网络参数,d是输入信息的维度
加性模型引入了可学习的参数,将查询向量 q 和原始输入向量 h 映射到不同的向量空间后进行计算打分,显然相较于加性模型,点积模型具有更好的计算效率。
另外,当输入向量的维度比较高的时候,点积模型通常有比较大的方差,从而导致Softmax函数的梯度会比较小。因此缩放点积模型通过除以一个平方根项来平滑分数数值,也相当于平滑最终的注意力分布,缓解这个问题。
最后,双线性模型可以重塑为,即分别对查询向量 q 和原始输入向量 h 进行线性变换之后,再计算点积。相比点积模型,双线性模型在计算相似度时引入了非对称性。
形象表示打分函数:

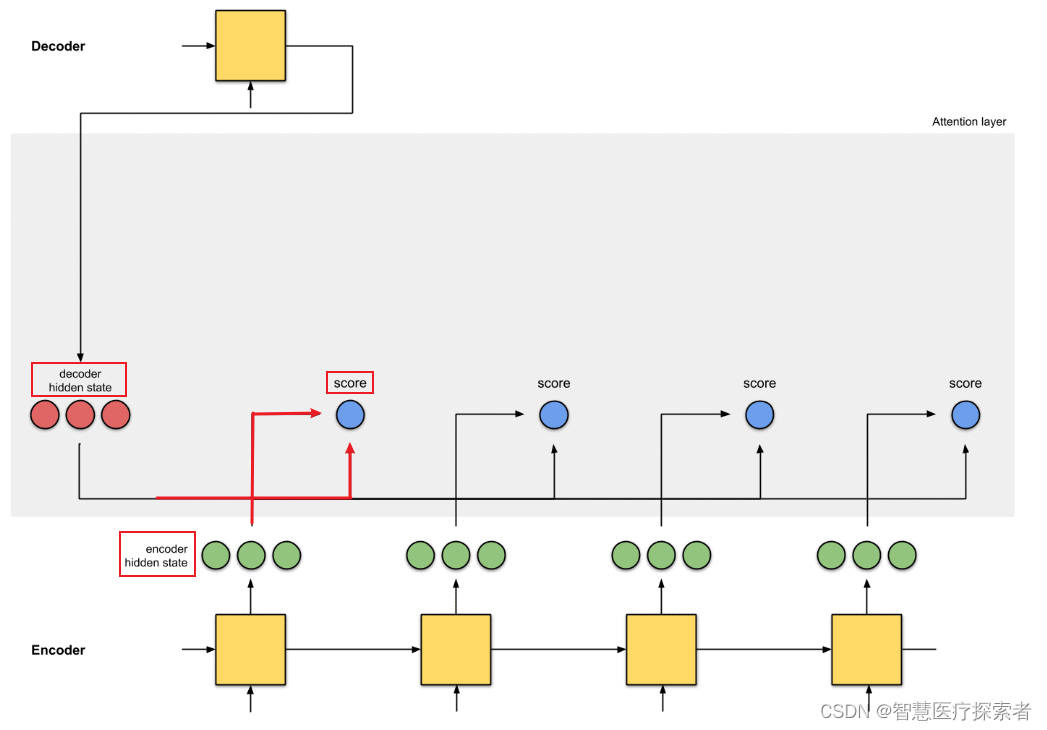
如果Encoder-Decoder都采用RNN,框架如下:
 那计算注意力分布概率值的过程如下:
那计算注意力分布概率值的过程如下:
表示Source中单词 j 对应的隐层节点状态,
表示Target中单词 i 的隐层节点状态,注意力计算的是Target中单词 i 对Source中每个单词对齐可能性
,即打分函数。
计算α,不只是编码器的隐藏状态作为输入,解码器的隐藏状态也要作为输入
可以结合下图理解:
2.4 加权分布
对于软性注意力机制,就是每一个输入按各自权重加权平均,即把每个编码器隐状态xi 和对应的注意力分布相乘求和
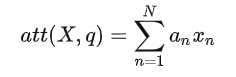
用图像形象表示:
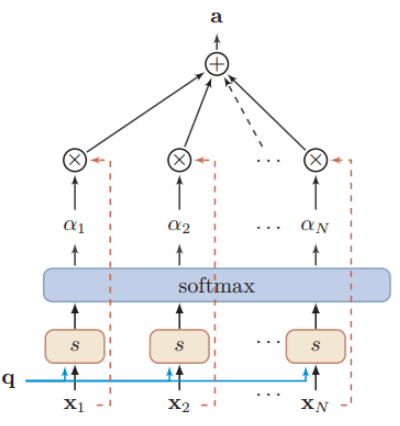
求和之和算出来的就是引入注意力机制的语义向量,再将其输入到解码器中。
结合下图理解:

这样Decoder的最终输出就会有选择性地关注应该关注的地方。