作者:胡安文(人大在读 多模态、NLP)
来自:人工智能与算法学习
大型语言模型LLM(Large Language Model)具有很强的通用知识理解以及较强的逻辑推理能力,但其只能处理文本数据。虽然已经发布的GPT4具备图片理解能力,但目前还未开放多模态输入接口并且不会透露任何模型上技术细节。因此,现阶段,如何利用LLM做一些多模态任务还是有一定的研究价值的。
本文整理了近两年来基于LLM做vision-lanuage任务的一些工作,并将其划分为4个类别:
利用LLM作为理解中枢调用多模态模型,例如VisualChatGPT(2023)[1], MM-REACT(2023)[2];
将视觉转化为文本,作为LLM的输入,例如PICA(2022)[3],PromptCap(2022)[4],ScienceQA(2022)[5];
利用视觉模态影响LLM的解码,例如ZeroCap[6],MAGIC[7];
冻住LLM,训练视觉编码器等额外结构以适配LLM,例如Frozen[8],BLIP2[9],Flamingo[10],PaLM-E[11];
接下来每个类别会挑选代表性的工作进行简单介绍:
一. 利用LLM作为理解中枢调用多模态模型
以微软Visual ChatGPT[1]为例,它的目标是使得一个系统既能和人进行视觉内容相关的对话,又能进行画图以及图片修改的工作。为此,Visual ChatGPT采用ChatGPT作为和用户交流的理解中枢,整合了多个视觉基础模型(Visual Foundation Models),通过prompt engineering (即Prompt Manager)告诉ChatGPT各个基础模型的用法以及输入输出格式,让ChatGPT决定为了满足用户的需求,应该如何调用这些模型,如图1所示。
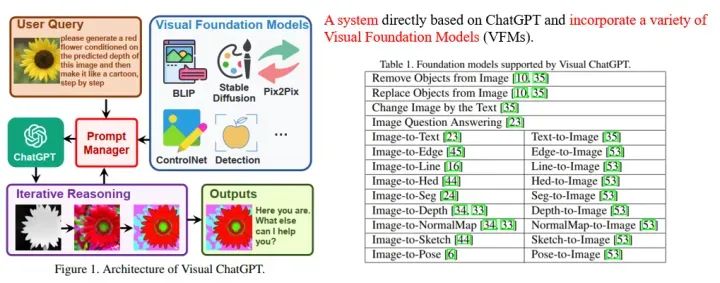
微软另一个小组稍晚一段时间提出的MM-REACT[2]也是同样的思路,区别主要在于prompt engineering的设计以及MM-REACT更侧重于视觉的通用理解和解释,包含了很多Microsoft Azure API,例如名人识别、票据识别以及Bing搜索等。
二. 将视觉转化为文本,作为LLM的输入
以PICA[3]为例,它的目标是充分利用LLM中的海量知识来做Knowledge-based QA。给定一张图和问题,以往的工作主要从外部来源,例如维基百科等来检索出相关的背景知识以辅助答案的生成。但PICA尝试将图片用文本的形式描述出来后,直接和问题拼在一起作为LLM的输入,让LLM通过in-context learning的方式直接生成回答,如图2所示。
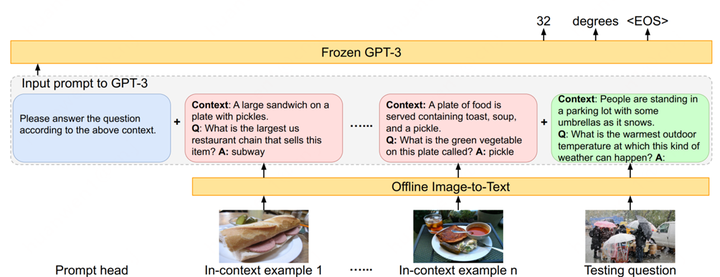
in-context learning的效果比较依赖example/demonstration的质量,为此PICA的作者利用CLIP挑选了和当前测试样例在问题和图片上最接近的16个训练样例作为examples。
三. 利用视觉模态影响LLM的解码
以MAGIC[3]为例,它的目标是让LLM做image captioning的任务,它的核心思路是生成每一个词时,提高视觉相关的词的生成概率,公式如图3所示。

该公式主要由三部分组成:1)LLM预测词的概率;2)退化惩罚(橙色);3)视觉相关性(红色)。退化惩罚主要是希望生成的词能带来新的信息量。视觉相关性部分为基于CLIP计算了所有候选词和图片的相关性,取softmax之后的概率作为预测概率。
四. 训练视觉编码器等额外结构以适配LLM
这部分工作是目前关注度最高的工作,因为它具有潜力来“以远低于多模态通用模型训练的代价将LLM拓展为多模态模型”。DeepMind于2021年发表的Frozen,2022年的Flamingo以及Saleforce 2023年的BLIP2都是这条路线,如图4所示。
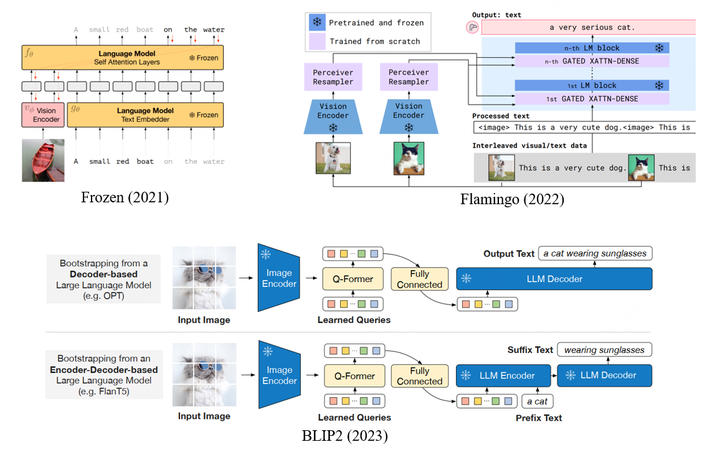
Frozen训练时将图片编码成2个vision token,作为LLM的前缀,目标为生成后续文本,采用Conceptual Caption作为训练语料。Frozen通过few-shot learning/in-context learning做下游VQA以及image classification的效果还没有很强,但是已经能观察到一些多模态in-context learning的能力。
Flamingo为了解决视觉feature map大小可能不一致(尤其对于多帧的视频)的问题,用Perceiver Resampler (类似DETR的解码器)生成固定长度的特征序列(64个token),并且在LLM的每一层之前额外增加了一层对视觉特征进行注意力计算的cross-attention layer,以实现更强的视觉相关性生成。Flamingo的训练参数远高于Frozen,因此采用了大量的数据:1)MultiModal MassiveWeb(M3W) dataset:从43million的网页上收集的图文混合数据,转化为图文交叉排列的序列(根据网页上图片相对位置,决定在转化为序列后,<image>token 在文本token系列中的位置);2)ALIGN (alt-text & image Pairs): 1.8 million图文对;3)LTIP (LongText & Image Pairs):312 million图文对;4)VTP (Video & Text Pairs) :27 million视频文本对(平均一个视频22s,帧采样率为1FPS)。类似LLM,Flamingo的训练目标也为文本生成,但其对于不同的数据集赋予不同的权重,上面四部分权重分别为1.0、0.2、0.2、0.03,可见图文交叉排列的M3W数据集的训练重要性是最高的,作者也强调这类数据是具备多模态in-context learning能力的重要因素。Flamingo在多个任务上实现了很不错的zero-shot以及few-shot的表现。
BLIP2采用了类似于Flamingo的视觉编码结构,但是采用了更复杂的训练策略。其包含两阶段训练,第一阶段主要想让视觉编码器学会提取最关键的视觉信息,训练任务包括image-Text Contrastive Learning, Image-grounded Text Generation以及Image-Text Matching;第二阶段则主要是将视觉编码结构的输出适配LLM,训练任务也是language modeling。BLIP2的训练数据包括MSCOCO,Visual Genome,CC15M,SBU,115M来自于LAION400M的图片以及BLIP在web images上生成的描述。BLIP2实现了很强的zero-shot capitoning以及VQA的能力,但是作者提到未观察到其in-context learning的能力,即输入样例并不能提升它的性能。作者分析是因为训练数据里不存在Flamingo使用的图文交错排布的数据。不过Frozen也是没有用这类数据,但是也观察到了一定的in-context learning能力。因此多模态的in-context learning能力可能和训练数据、训练任务以及位置编码方法等都存在相关性。
总结
“利用LLM作为理解中枢调用多模态模型”可以方便快捷地基于LLM部署一个多模态理解和生成系统,难点主要在于prompt engineering的设计来调度不同的多模态模型;
“将视觉转化为文本,作为LLM的输入”和“利用视觉模态影响LLM的解码”可以直接利用LLM做一些多模态任务,但是可能上限较低,其表现依赖于外部多模态模型的能力;
“训练视觉编码器等额外结构以适配LLM”具有更高的研究价值,因为其具备将任意模态融入LLM,实现真正意义多模态模型的潜力,其难点在于如何实现较强的in-context learning的能力。
相关工作
略……
后台回复:入群,加入NLP交流大群~