作者 | 小戏、Python
“要是我有一个学法的朋友就好了”
法律作为我们社会生活的最高指引,其重要性毋庸多言。然而类似于医学,法律又是一个入行门槛非常高的专业领域,想想通过率不到 10% 的法考,显然遇到法律相关的专业问题不太支持我们抄起法条生啃,因此一个理想的场景便是我有一个自己的私人法律顾问,可以自信的说“在我律师来之前,我不会说一句话”

事实上,在大家畅想大模型广阔的应用天地时,肯定也想到过将大模型应用于专业的垂直领域,在这些领域大模型所擅长的“问答”必然能带来比纯粹的聊天机器人或是智能客服更多的想象力。但是问题似乎也显而易见,垂直领域的大模型缺少对领域特定知识的训练语料,同时,在医学、法律这样的需要高度“可信”的领域中,大模型的机器幻觉也会带来许许多多的问题。
大模型研究测试传送门
GPT-4传送门(免墙,可直接测试,遇浏览器警告点高级/继续访问即可):
Hello, GPT4!
而最近,北京大学王选计算机研究所的团队推出了一个中文的法律大模型 Lawyer LLaMA,通过在大规模法律语料中进行训练,系统学习中国的法律知识体系使得模型可以掌握中国的法律知识并应用于中国的法律实务。让我们上图片举个栗子:

对比上图左侧的BELLE(Be Everyone's Large Language model Engine)模型,如果提问“中国的法定结婚年龄”,可以看到 Lawyer LLaMA 给出了一个正确的,并且更像是 Lawyer 的回答。并且,即使是提供了必要的法律条文,如上图问题B,BELLE 也无法给出一个正确的回答,而 Lawyer LLaMA 则有理有据的颇具专业性的很好的回答了这个问题。
其实从 BELLE 的回答中也可以看出,直接将这样一个大模型套在专业的垂直领域下往往会出现许多问题,作者团队认为,要使得大模型可以很好的适应法律领域的特殊要求,必须要满足以下三个条件,分别是:
-
精确的表意,避免歧义:在法律领域中常常会有仅仅更换一个字词,就会导致法律关系构建出截然相反的结果,譬如中文中定金与订金仅相差一个字,但是其含义与法律效力在合同法中却完全不同;
-
理解与区分法律术语:在法律中,有许多特有的特定词汇,许多术语仅仅出现在法律领域中,如法人这个概念,而还有更多术语可能在法律领域与日常生活领域拥有着不尽相同的含义,也需要模型加以区分;
-
能够理解实际情况:除了对法律术语与法律分析要有基本的了解与系统的掌握以外,模型还应当具有精确理解现实生活问题的能力,即模型需要拥有一个应用法律理论来解决特定问题的核心能力。
基于上述理论,作者团队便基于开源的 LLaMA 模型期望通过以下几步解决法律领域大模型的适用问题:
-
法律相关知识注入:通过收集大量法律领域的原始文本,如法律条文、司法解释与国家法律文件,对原始模型使用新数据进行继续训练;
-
特定领域技能习得:一个良好的法律大模型应该能够解决法律领域的常见问题,如概念解释、案例分析与法律咨询,因此作者收集了一组实际的任务案例,使用 ChatGPT 生成相应答案从而进行监督微调,以使得模型具有解决法律领域特定任务的能力;
-
信息检索减轻幻觉:为了减轻大模型的机器幻觉问题,作者同时引入了一个信息检索模块,在生成每个回复之前,都首先利用用户的查询与上下文检索相关法律条文,基于这些法律条文再去生成相应回复。
通过以上三步,作者团队便成功的完成了 Lawyer LLaMA 的构建,Lawyer LLaMA 的整体运作流程如下图所示:

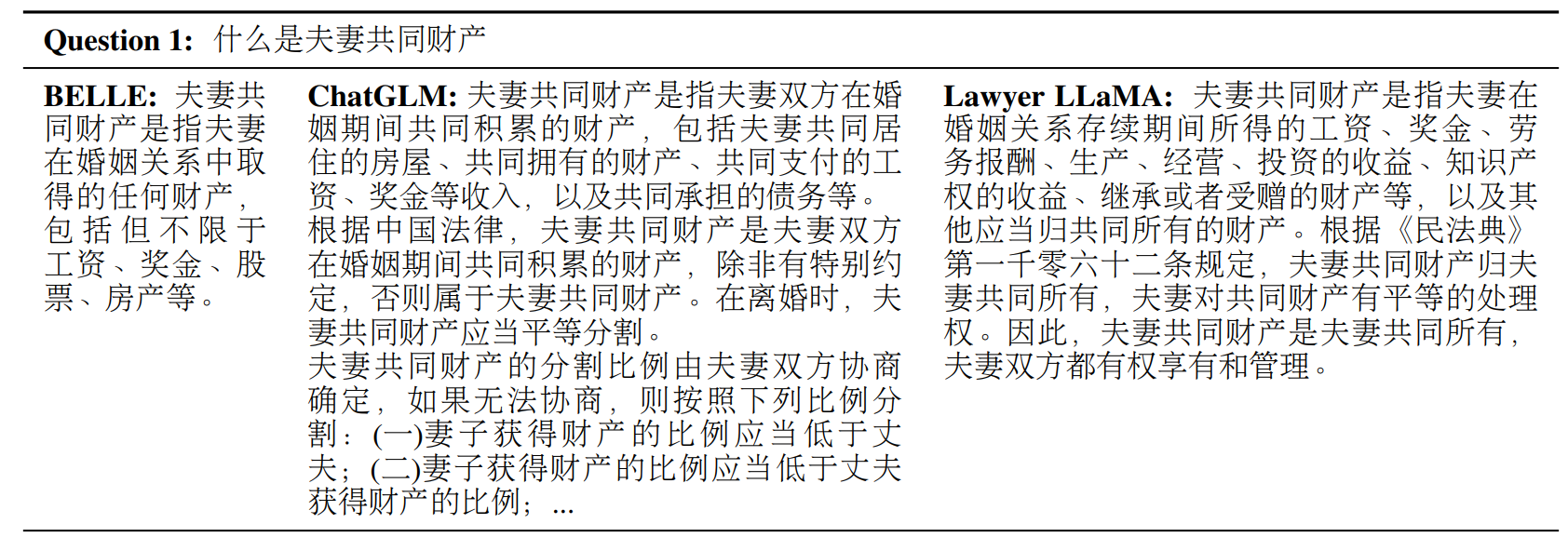
先跳开训练的细节,让我们定性的看一波 Lawyer LLaMA 的回复表现,首先在一个法律概念解释的任务里,当要求模型解释“什么是夫妻共同财产”时,BELLE 与 ChatGLM 都给出了错误的回答,从这两个大模型所犯的错误中可以看到,法律领域的概念解释并不是一个简单的问题,如 BELLE 虽然理解了夫妻共同财产的概念,但是却错误的使用了“任何财产”这样的表达,而 ChatGLM 则错误的将共同债务视为共同的财产类型,甚至对财产分割开始胡言乱语,而只有 Lawyer LLaMA 简明准确的回答了这样一个概念:
更进一步的,作者同样要求 BELLE 与 ChatGLM 以及 Lawyer LLaMA 区分两个相似的法律概念,即离婚与无效婚姻,可以看到 BELLE 和 ChatGLM 都误解了离婚的概念,并且使用了口语化的容易导致歧义的表达,如 BELLE “从未存在过” 这样非常不专业的回答,也只有 Lawyer LLaMA 给出了一个看起来更加专业可信度更高的回复:

除了上述名词解释性的题目外,Lawyer LLaMA 在“应用题”法律实务咨询上也表现良好,如下图所示,关于一个离婚问题,BELLE 与 ChatGLM 的回复都存有一些逻辑问题甚至胡言乱语,这样的回复显然不能作为法律实务咨询的回复,而 Lawyer LLaMA 则非常清晰明了的回答了上述的咨询问题:

同时,在作者的实验中还发现, BELLE 与 ChatGLM 这两个模型事实上并不能理解法律条文的含义,如下面的案例中,BELLE 引用了一个完全无关的条文,而 ChatGLM 则混淆了无效婚姻与可撤销婚姻的概念,都导致的回答错误。

Lawyer LLaMA 的构建
为了成功构建一个法律领域的大模型,遵循前文介绍的三步,作者为了解决使用的开源大模型 LLaMA 的中文理解问题,作者团队首先先使用中文通用语料库对 LLaMA 进行训练,这些中文语言抽样自 WuDaoCorpora、CLUECorpus2020 以及维基百科的简体中文版。在完成中文能力增强之后,作者开始着手构建中文法律语料库,这样一个法律语料库主要来源于中国各级法院网站的文章、判决文书、法律条文、司法解释、法庭新闻以及各种法律科普文章等等。
同时,作者使用了“天下第一考”法考的考试题来让大模型进行刷题训练,作者采用了 JEC-QA(A Legal-Domain Question Answering Dataset) 数据集的 26365 个单选与多选问答对来对模型进行训练,并且为了增强模型对“解题过程”的理解,作者又使用了 ChatGPT 为模型生成问题解释,生成的解释示例如下所示:

而对于法律咨询问题,作者主要使用一个开源的法律咨询数据集对问题进行抽样,同样,使用 ChatGPT 生成问题回答,区别于上文直接的采用 ChatGPT 生成问题解释,在面对法律咨询这种更加复杂的问题时,作者综合使用单轮与多轮对话、赋予 ChatGPT 律师角色、设计 Prompt 等等以提升回复的准确性,并且为了保证“有法可依”,作者团队还设计了一个法律条款的检索器,要求 ChatGPT 正确引用法律条款以生成回复。

在收集了大约 16000 个单轮回答与 5000 个具有 2-3 轮对话回复之后,模型整体训练流程可以被表示为以下这张图片:
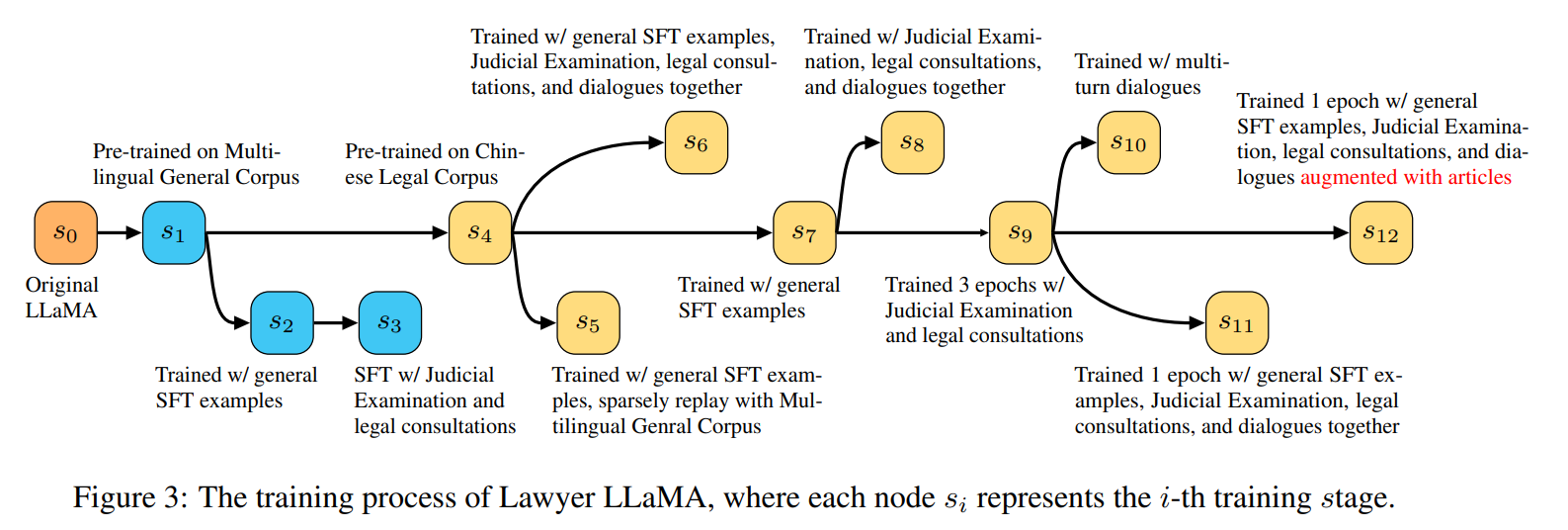
如上图所示,整体训练流程经过了增强汉语能力(s1),法律知识注入(s4),下游任务训练(s7)以及法律条文检索(s12)四大步,逐步增强模型解决法律问题的能力,值得注意的是其中最后一步法律条文检索,在作者的实验中发现,现有大模型即使学习到了相关的法律条文条款,但是仍然学不会在生成回复时正确的引用它们,经常会出现参考不相关的条文,错误替换含义不同的法律概念等等问题,因此作者引入了法律条款检索模型,针对法律咨询的用户问题,要求专业律师标注最多 3 个必要的法律条文,再使用 RoBERTa 训练了一个在相关检索测试集上正确率 85% 的法律条文检索模型。但是当检索到的法律条文与用户输入相连时,作者发现模型也会倾向于引用所提供的所有法律条文,而不去区分它们是否真正与当前问题场景相关,因此,论文又加入了许多不相关的文章到模型的上下文中,以迫使模型忽略那些“不重要的信息”,并且添加了“参考文献中可能有不相关的内容,请避免在回复时引用那些不相关的文章”的 Prompt。
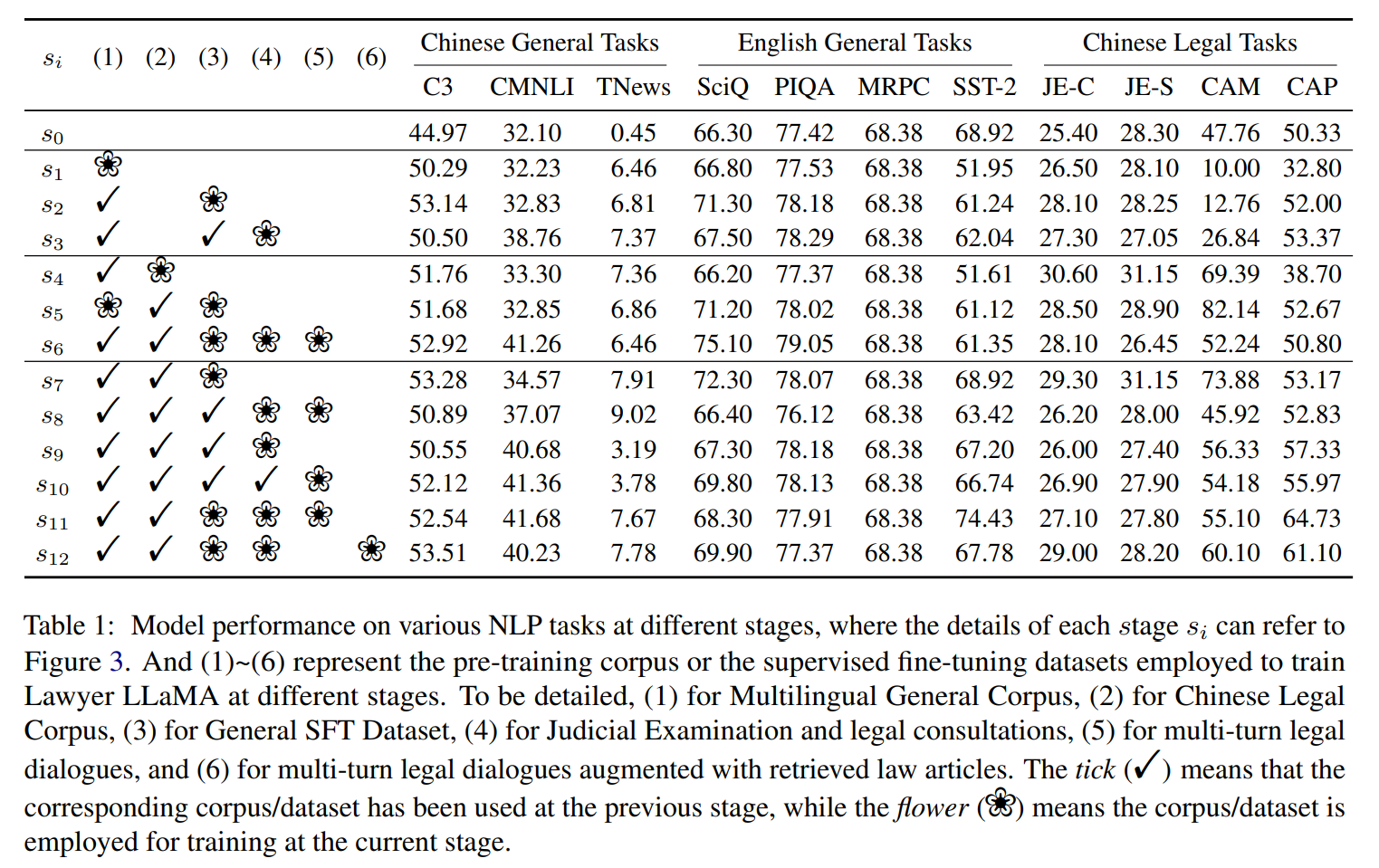
最终实验基于 LLaMA-7B 训练完成 Lawyer LLaMA 的构建,基于模型训练的s1-s12个阶段,以及(1)-(6)种训练语料,作者评估了模型在训练各个阶段在中文通用任务、英文通用任务以及中文法律任务中的模型得分,可以发现模型在中文语料训练后在中文问答数据集 C3 中获得了 5.3% 的正确率提升,并且其英文能力没有出现下降。同时,比较好玩的一点是,在学习完法考之后,模型的中文 NLI 能力(CMNLI)也得到了提升,提升了 9.3%,尽管法考的试题数据中没有 NLI 的问题,因此模型似乎是通过对法考题目以及推理判断过程的学习增强了中文的理解与推理能力(不愧是法考)。
而在法律领域,**通过区分法考数据(JE)中的概念辨析(JE-C)与情景规划(JE-S)问题以及婚姻判决问题(CAM)与财产判决问题(CAP)构建评估数据集,可以发现,s12 的模型在大多数任务中都优于 s0,准确率在 CAM 与 CAP 中提升幅度都超过 10%**,但是比较 s0、s4、s7 下的 JE-C 与 JE-S 的结果,可以发现从 s0 到 s7,JE-C 提升 3.9%,JE-S 提升 2.85%,但是当引入问题咨询的数据后,JE-C 与 JE-S 的准确率都出现了下降,作者认为主要原因可能来自考试问题与咨询问题之间的不相似性。
总结与讨论
这篇文章提出了法律这样一种垂直专业领域下的大模型训练方法论,其实不仅仅是法律,许多专业细分领域的大模型训练都可以从这篇论文中找到借鉴,总结来说,就是“有监督微调”让模型学习必要的专业知识,“检索模块”提供必要的外部证据以解决模型的可信性问题。这篇论文的代码也开源在了 Github 中,并且计划进行 Lawyer LLaMA 13B 的内测体验,感兴趣的小伙伴可以关注下方论文与代码链接~
论文题目:
Lawyer LLaMA Technical Report
论文链接:
https://arxiv.org/pdf/2305.15062.pdf
代码链接:
https://github.com/AndrewZhe/lawyer-llama