开源大模型综述
-
- 排行榜
- 1.LLaMA
- 2.Chinese-LLaMA-Alpaca
- 3.Alpaca
- 4.Alpaca-LoRA
- 5.Vicuna
- 6.OpenChatKit
- 7.GPT4ALL
- 8.Raven RWKV
- 9.OPT
- 10.Flan-T5-XXL
- 11.MPT-7B
- 12.清华**ChatGLM-6B**
- 13.复旦MOSS
- 附录
-
- 训练推理最低资源汇总
- 语料
-
- 1.维基百科json版(wiki2019zh)
- 结构:
- 例子:
- 2.新闻语料json版(news2016zh)
- 250万篇新闻( 原始数据9G,压缩文件3.6G;新闻内容跨度:2014-2016年)
- 数据描述
- 可能的用途:
- 结构:
- 例子:
- 3.百科类问答json版(baike2018qa)
- 150万个问答( 原始数据1G多,压缩文件663M;数据更新时间:2018年)
- 数据描述
- 可能的用途:
- 结构:
- 例子:
- 公开评测:
- 4.社区问答json版(webtext2019zh) :大规模高质量数据集
- 数据描述
- 可能的用途:
- 结构:
- 例子:
- 在该数据集上的公开评测和任务:
- 5.翻译语料(translation2019zh)
- 数据描述
- 可能的用途:
- 结构:
- 例子:
- 可能的用途:
- 结构:
- 例子:
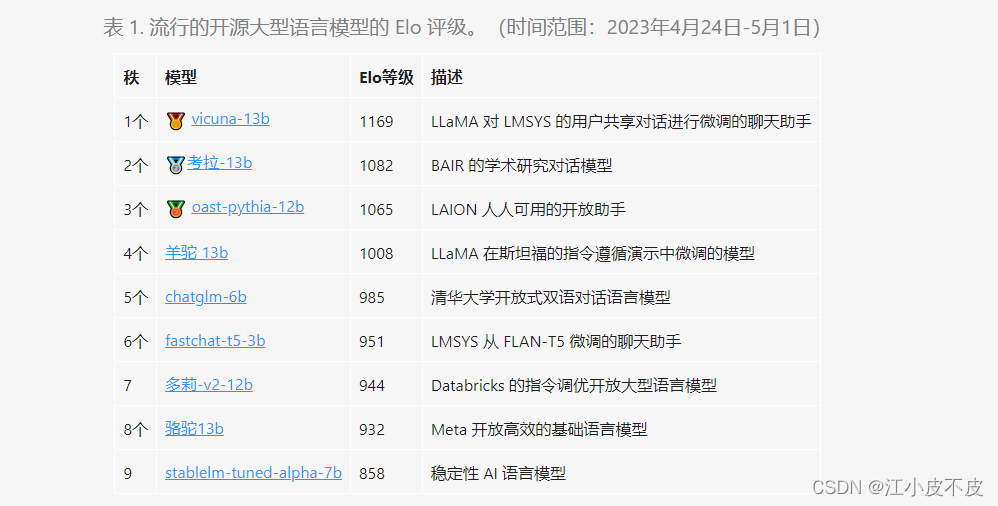
排行榜
我们展示了 Chatbot Arena,这是一个大型语言模型 (LLM) 的基准平台,以众包方式进行匿名、随机的战斗。在这篇博文中,我们将发布我们的初步结果和基于 Elo 评级系统的排行榜,该系统是国际象棋和其他竞技游戏中广泛使用的评级系统。我们邀请整个社区加入这项工作,贡献新模型并通过提问和投票选出您最喜欢的答案来评估它们。
1.LLaMA
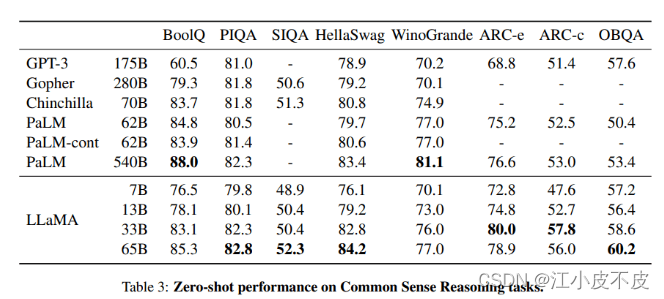
LLaMA项目包含了一组基础语言模型,其规模从70亿到650亿个参数不等。这些模型在数以百万计的token上进行训练,而且它完全在公开的数据集上进行训练。结果,LLaMA-13B超过了GPT-3(175B),而LLaMA-65B的表现与Chinchilla-70B和PaLM-540B等最佳模型相似。
资源:
- 研究论文:“LLaMA: Open and Efficient Foundation Language Models (arxiv.org)” [https://arxiv.org/abs/2302.13971]
- GitHub:facebookresearch/llama [https://github.com/facebookresearch/llama]
- 演示:Baize Lora 7B [https://huggingface.co/spaces/project-baize/Baize-7B]
2.Chinese-LLaMA-Alpaca
以ChatGPT、GPT-4等为代表的大语言模型(Large Language Model, LLM)掀起了新一轮自然语言处理领域的研究浪潮,展现出了类通用人工智能(AGI)的能力,受到业界广泛关注。然而,由于大语言模型的训练和部署都极为昂贵,为构建透明且开放的学术研究造成了一定的阻碍。
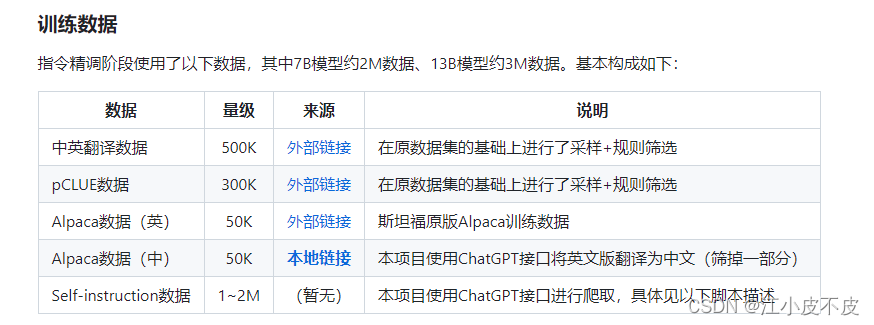
为了促进大模型在中文NLP社区的开放研究,本项目开源了中文LLaMA模型和指令精调的Alpaca大模型。这些模型在原版LLaMA的基础上扩充了中文词表并使用了中文数据进行二次预训练,进一步提升了中文基础语义理解能力。同时,中文Alpaca模型进一步使用了中文指令数据进行精调,显著提升了模型对指令的理解和执行能力。

资源:
- GitHub:https://github.com/ymcui/Chinese-LLaMA-Alpaca
3.Alpaca
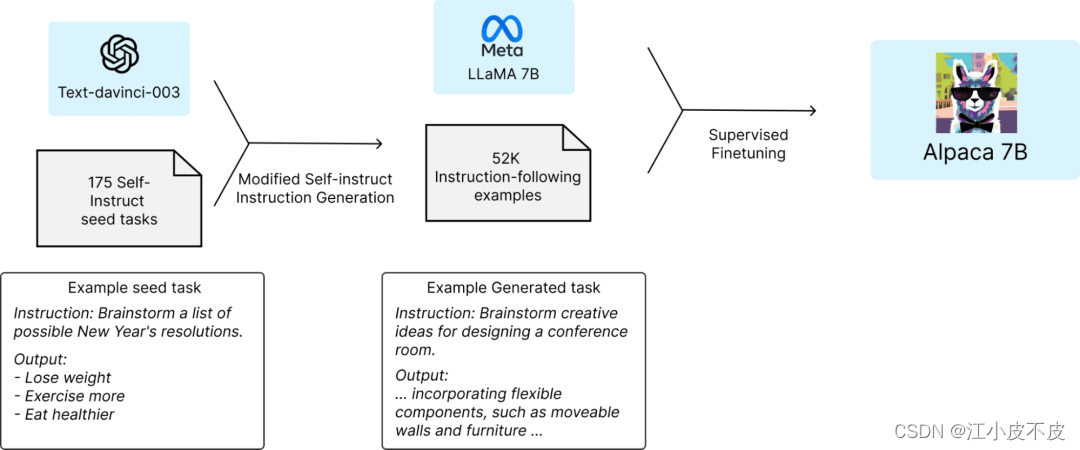
斯坦福大学的Alpaca声称它可以与ChatGPT竞争,任何人都可以在不到600美元的情况下复制它。Alpaca 7B是在52K指令遵循的示范上从LLaMA 7B模型中进行微调。
资源:
- 博客:斯坦福大学CRFM。[https://crfm.stanford.edu/2023/03/13/alpaca.html]
- GitHub:tatsu-lab/stanford_alpaca [https://github.com/tatsu-lab/stanford_alpaca]
4.Alpaca-LoRA
使用低秩适应 (LoRA)重现斯坦福羊驼结果的代码
资源:
- GitHub: https://github.com/tloen/alpaca-lora
- 演示:Alpaca-LoRA [https://huggingface.co/spaces/tloen/alpaca-lora]
5.Vicuna
Vicuna是在从ShareGPT收集到的用户共享对话上的LLaMA模型基础上进行微调。Vicuna-13B模型已经达到了OpenAI ChatGPT和Google Bard的90%以上的质量。它还在90%的情况下超过了LLaMA和斯坦福大学Alpaca模型。训练Vicuna的成本约为300美元。
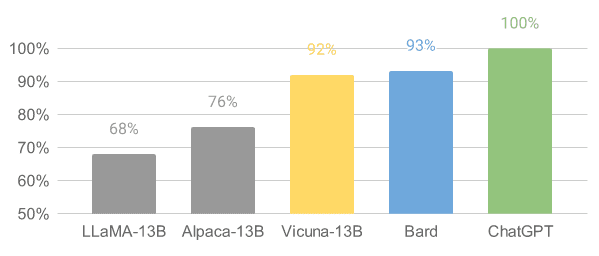
资源:
- 博客文章:“Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality” [https://vicuna.lmsys.org/]
- GitHub:lm-sys/FastChat [https://github.com/lm-sys/FastChat#fine-tuning]
- 演示:FastChat (lmsys.org) [https://chat.lmsys.org/]
6.OpenChatKit
OpenChatKit:开源的ChatGPT替代方案,是一个用于创建聊天机器人的完整工具包。它提供了用于训练用户自己的指令调整的大型语言模型、微调模型、用于更新机器人响应的可扩展检索系统以及用于过滤问题的机器人审核的指令。
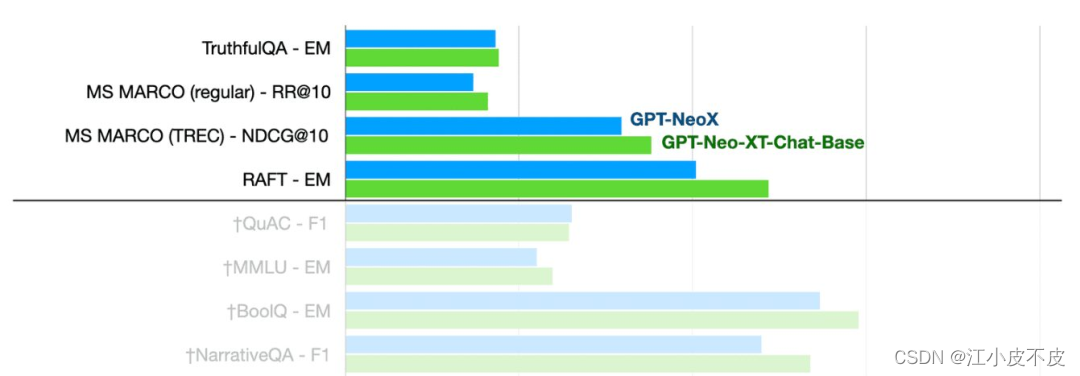
可以看到,GPT-NeoXT-Chat-Base-20B模型在问答、提取和分类任务上的表现优于基础模式GPT-NoeX。
资源:
- 博客文章:“Announcing OpenChatKit”—TOGETHER [https://www.together.xyz/blog/openchatkit]
- GitHub: togethercomputer/OpenChatKit [https://github.com/togethercomputer/OpenChatKit]
- 演示:OpenChatKit [https://huggingface.co/spaces/togethercomputer/OpenChatKit]
- 模型卡:togethercomputer/GPT-NeoXT-Chat-Base-20B [https://huggingface.co/togethercomputer/GPT-NeoXT-Chat-Base-20B]
7.GPT4ALL
GPT4ALL是一个社区驱动的项目,并在一个大规模的辅助交互语料库上进行训练,包括代码、故事、描述和多轮对话。该团队提供了数据集、模型权重、数据管理过程和训练代码以促进开源。此外,他们还发布了模型的量化4位版本,可以在笔记本电脑上运行。甚至可以使用Python客户端来运行模型推理。
- 技术报告:GPT4All [https://s3.amazonaws.com/static.nomic.ai/gpt4all/2023_GPT4All_Technical_Report.pdf]
- GitHub: nomic-ai/gpt4al [https://github.com/nomic-ai/gpt4all]
- 演示:GPT4All(非官方)。[https://huggingface.co/spaces/rishiraj/GPT4All]
- 模型卡:nomic-ai/gpt4all-lora · Hugging Face [https://huggingface.co/nomic-ai/gpt4all-lora]
8.Raven RWKV
Raven RWKV 7B是一个开源的聊天机器人,它由RWKV语言模型驱动,生成的结果与ChatGPT相似。该模型使用RNN,可以在质量和伸缩性方面与transformer相匹配,同时速度更快,节省VRAM。Raven在斯坦福大学Alpaca、code-alpaca和更多的数据集上进行了微调。
资源:
- GitHub:BlinkDL/ChatRWKV [https://github.com/BlinkDL/ChatRWKV]
- 演示:Raven RWKV 7B [https://huggingface.co/spaces/BlinkDL/Raven-RWKV-7B]
- 模型卡:BlinkDL/rwkv-4-raven [https://huggingface.co/BlinkDL/rwkv-4-raven]
9.OPT
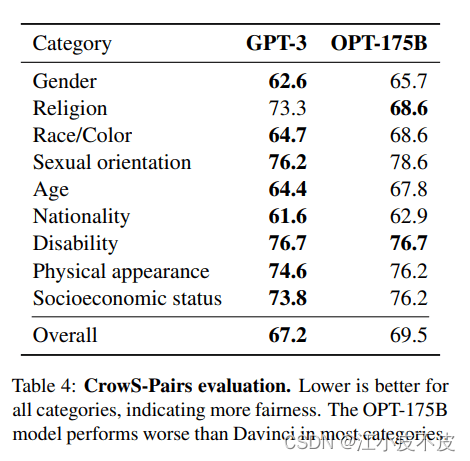
OPT:Open Pre-trained Transformer语言模型并不像ChatGPT那样强大,但它在零样本和少样本学习以及刻板偏见分析方面表现出卓越的能力。还可以将它与Alpa、Colossal-AI、CTranslate2和FasterTransformer集成以获得更好的结果。**注意:**它上榜的原因是它的受欢迎程度,因为它在文本生成类别中每月有624,710次下载。
资源:
- 研究论文:“OPT: Open Pre-trained Transformer Language Models (arxiv.org)” [https://arxiv.org/abs/2205.01068]
- GitHub: facebookresearch/metaseq [https://github.com/facebookresearch/metaseq]
- 演示:A Watermark for LLMs [https://huggingface.co/spaces/tomg-group-umd/lm-watermarking]
- 模型卡:facebook/opt-1.3b [https://huggingface.co/facebook/opt-1.3b]
10.Flan-T5-XXL
Flan-T5-XXL在以指令形式表述的数据集上微调了T5模型。指令的微调极大地提高了各种模型类别的性能,如PaLM、T5和U-PaLM。Flan-T5-XXL模型在1000多个额外的任务上进行了微调,涵盖了更多语言。
资源:
- 研究论文:“Scaling Instruction-Fine Tuned Language Models” [https://arxiv.org/pdf/2210.11416.pdf]
- GitHub: google-research/t5x [https://github.com/google-research/t5x]
- 演示:Chat Llm Streaming [https://huggingface.co/spaces/olivierdehaene/chat-llm-streaming]
- 模型卡:google/flan-t5-xxl [https://huggingface.co/google/flan-t5-xxl?text=Q%3A+%28+False+or+not+False+or+False+%29+is%3F+A%3A+Let%27s+think+step+by+step]
11.MPT-7B
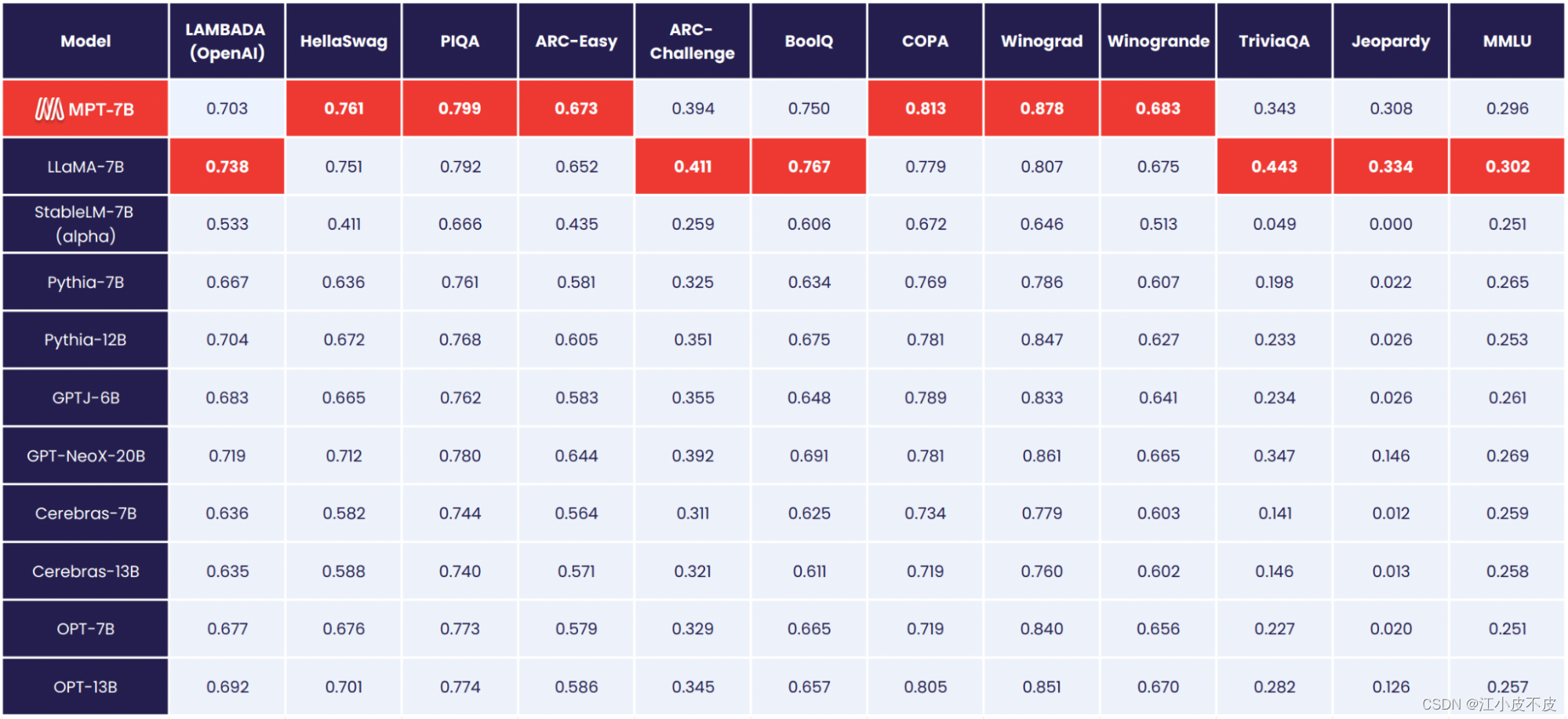
MPT全称是MosaicML Pretrained Transformer,是MosaicML发布的一系列大模型。尽管业界已经发布了很多大模型,但是这些模型通常都比较难以训练和部署。而MosaicML发布这样的大模型的目的就是为了解决上述限制,提供一个完全开源且可商用的一个大模型。MPT系列主要的特点是:
-
有商用许可
-
基于大量的数据训练
-
目标是解决长输入(最高支持65K的输入,84K的处理)
-
训练与推理速度的优化
-
高效的开源训练代码
资源:
-
模型GitHub链接 https://github.com/mosaicml/llm-foundry
-
模型HuggingFace链接 https://huggingface.co/mosaicml/mpt-7b
-
论文 https://www.mosaicml.com/blog/mpt-7b
12.清华ChatGLM-6B
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。为了方便下游开发者针对自己的应用场景定制模型,同时实现了基于 P-Tuning v2 的高效参数微调方法 (使用指南) ,INT4 量化级别下最低只需 7GB 显存即可启动微调。

资源:
- GitHub链接 https://github.com/THUDM/ChatGLM-6B
13.复旦MOSS
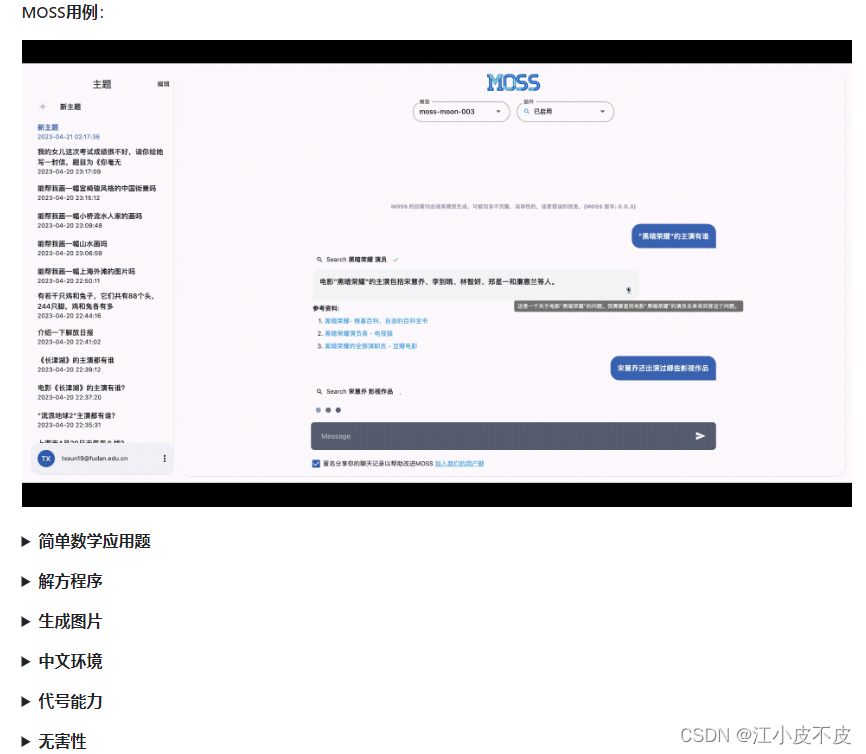
据介绍,MOSS 是一个支持中英双语和多种插件的开源对话语言模型,moss-moon 系列模型具有 160 亿参数,在 FP16 精度下可在单张 A100 / A800 或两张 3090 显卡运行,在 INT4/8 精度下可在单张 3090 显卡运行。MOSS 基座语言模型在约七千亿中英文以及代码单词上预训练得到,后续经过对话指令微调、插件增强学习和人类偏好训练具备多轮对话能力及使用多种插件的能力。
资源:
- GitHub链接 https://github.com/OpenLMLab/MOSS
附录
训练推理最低资源汇总
| 模型 | 推理 | 训练(微调) |
|---|---|---|
| LLaMA | 17G | 不可 |
| Chinese-LLaMA-Alpaca | 3.9G | |
| Alpaca | 未说明 | 112G |
| Alpaca-LoRA | 未说明 | 23G |
| Vicuna | 14G | 160G |
| OpenChatkit | 40G | 未说明 |
| GPT4All | 16G | 未说明 |
| Raven RWKV | 15G | 未说明 |
| OPT | 未说明 | 350GB |
| Flan-T5-XXL | 未说明 | 未说明 |
| MPT-7B | 未说明 | 未说明 |
| 清华ChatGLM-6B | 7G | 96G |
| 复旦MOOS | 7.8G | 未说明 |
语料
1.维基百科json版(wiki2019zh)
104万个词条(1,043,224条; 原始文件大小1.6G,压缩文件519M;数据更新时间:2019.2.7)
结构:
{"id":<id>,"url":<url>,"title":<title>,"text":<text>} 其中,title是词条的标题,text是正文;通过"\n\n"换行。
例子:
{"id": "53", "url": "https://zh.wikipedia.org/wiki?curid=53", "title": "经济学", "text": "经济学\n\n经济学是一门对产品和服务的生产、分配以及消费进行研究的社会科学。西方语言中的“经济学”一词源于古希腊的。\n\n经济学注重的是研究经济行为者在一个经济体系下的行为,以及他们彼此之间的互动。在现代,经济学的教材通常将这门领域的研究分为总体经济学和个体经济学。微观经济学检视一个社会里基本层次的行为,包括个体的行为者(例如个人、公司、买家或卖家)以及与市场的互动。而宏观经济学则分析整个经济体和其议题,包括失业、通货膨胀、经济成长、财政和货币政策等。..."}

2.新闻语料json版(news2016zh)
250万篇新闻( 原始数据9G,压缩文件3.6G;新闻内容跨度:2014-2016年)
Google Drive下载或 百度云盘下载,密码:k265
数据描述
包含了250万篇新闻。新闻来源涵盖了6.3万个媒体,含标题、关键词、描述、正文。
数据集划分:数据去重并分成三个部分。训练集:243万;验证集:7.7万;测试集,数万,不提供下载。
可能的用途:
可以做为【通用中文语料】,训练【词向量】或做为【预训练】的语料;
也可以用于训练【标题生成】模型,或训练【关键词生成】模型(选关键词内容不同于标题的数据);
亦可以通过新闻渠道区分出新闻的类型。
结构:
{'news_id': <news_id>,'title':<title>,'content':<content>,'source': <source>,'time':<time>,'keywords': <keywords>,'desc': <desc>, 'desc': <desc>}
其中,title是新闻标题,content是正文,keywords是关键词,desc是描述,source是新闻的来源,time是发布时间
例子:
{"news_id": "610130831", "keywords": "导游,门票","title": "故宫淡季门票40元 “黑导游”卖外地客140元", "desc": "近

3.百科类问答json版(baike2018qa)
150万个问答( 原始数据1G多,压缩文件663M;数据更新时间:2018年)
Google Drive下载 或 百度云盘下载,密码:fu45
数据描述
含有150万个预先过滤过的、高质量问题和答案,每个问题属于一个类别。总共有492个类别,其中频率达到或超过10次的类别有434个。
数据集划分:数据去重并分成三个部分。训练集:142.5万;验证集:4.5万;测试集,数万,不提供下载。
可能的用途:
可以做为通用中文语料,训练词向量或做为预训练的语料;也可以用于构建百科类问答;其中类别信息比较有用,可以用于做监督训练,从而构建
更好句子表示的模型、句子相似性任务等。
结构:
{"qid":<qid>,"category":<category>,"title":<title>,"desc":<desc>,"answer":<answer>}
其中,category是问题的类型,title是问题的标题,desc是问题的描述,可以为空或与标题内容一致。
例子:
{"qid": "qid_2540946131115409959", "category": "生活知识", "title": "冬天进补好一些呢,还是夏天进步好啊? ", "desc": "", "answer": "你好!\r\r当然是冬天进补好的了,夏天人体的胃处于收缩状态,不适宜大量的进补,所以我们有时候说:“夏天就要吃些清淡的,就是这个道理的。”\r\r不过,秋季进补要注意“四忌” 一忌多多益善。任何补药服用过量都有害。认为“多吃补药,有病治病,无病强身”是不的。过量进补会加重脾胃、肝脏负担。在夏季里,人们由于喝冷饮,常食冻品,多有脾胃功能减弱的现象,这时候如果突然大量进补,会骤然加重脾胃及肝脏的负担,使长期处于疲弱的消化器官难于承受,导致消化器官功能紊乱。 \r\r二忌以药代食。重药物轻食物的做法是不科学的,许多食物也是好的滋补品。如多吃荠菜可治疗高血压;多吃萝卜可健胃消食,顺气宽胸;多吃山药能补脾胃。日常食用的胡桃、芝麻、花生、红枣、扁豆等也是进补的佳品。\r\r三忌越贵越好。每个人的身体状况不同,因此与之相适应的补品也是不同的。价格昂贵的补品如燕窝、人参之类并非对每个人都适合。每种进补品都有一定的对象和适应症,应以实用有效为滋补原则,缺啥补啥。 \r\r四忌只补肉类。秋季适当食用牛羊肉进补效果好。但经过夏季后,由于脾胃尚未完全恢复到正常功能,因此过于油腻的食品不易消化吸收。另外,体内过多的脂类、糖类等物质堆积可能诱发心脑血管病。"}
公开评测:
欢迎报告模型在验证集上的准确率。任务1: 类别预测。
报告包括:#1)验证集上准确率;#2)采用的模型、方法描述、运行方式,1页PDF;#3)可运行的源代码(可选)
基于#2和#3,我们会在测试集上做测试,并报告测试集上的准确率;只提供了#1和#2的队伍,验证集上的成绩依然可以被显示出来,但会被标记为未验证。

4.社区问答json版(webtext2019zh) :大规模高质量数据集
410万个问答( 过滤后数据3.7G,压缩文件1.7G;数据跨度:2015-2016年)
数据描述
含有410万个预先过滤过的、高质量问题和回复。每个问题属于一个【话题】,总共有2.8万个各式话题,话题包罗万象。
从1400万个原始问答中,筛选出至少获得3个点赞以上的的答案,代表了回复的内容比较不错或有趣,从而获得高质量的数据集。
除了对每个问题对应一个话题、问题的描述、一个或多个回复外,每个回复还带有点赞数、回复ID、回复者的标签。
数据集划分:数据去重并分成三个部分。训练集:412万;验证集:6.8万;测试集a:6.8万;测试集b,不提供下载。
可能的用途:
1)构建百科类问答:输入一个问题,构建检索系统得到一个回复或生产一个回复;或根据相关关键词从,社区问答库中筛选出你相关的领域数据
2)训练话题预测模型:输入一个问题(和或描述),预测属于话题。
3)训练社区问答(cQA)系统:针对一问多答的场景,输入一个问题,找到最相关的问题,在这个基础上基于不同答案回复的质量、
问题与答案的相关性,找到最好的答案。
4)做为通用中文语料,做大模型预训练的语料或训练词向量。其中类别信息也比较有用,可以用于做监督训练,从而构建更好句子表示的模型、句子相似性任务等。
5)结合点赞数量这一额外信息,预测回复的受欢迎程度或训练答案评分系统。
结构:
{"qid":<qid>,"title":<title>,"desc":<desc>,"topic":<topic>,"star":<star>,"content":<content>,
"answer_id":<answer_id>,"answerer_tags":<answerer_tags>}
其中,qid是问题的id,title是问题的标题,desc是问题的描述,可以为空;topic是问题所属的话题,star是该回复的点赞个数,
content是回复的内容,answer_id是回复的ID,answerer_tags是回复者所携带的标签
例子:
{"qid": 65618973, "title": "AlphaGo只会下围棋吗?阿法狗能写小说吗?", "desc": "那么现在会不会有智能机器人能从事文学创作?<br>如果有,能写出什么水平的作品?", "topic": "机器人", "star": 3, "content": "AlphaGo只会下围棋,因为它的设计目的,架构,技术方案以及训练数据,都是围绕下围棋这个核心进行的。它在围棋领域的突破,证明了深度学习深度强化学习MCTS技术在围棋领域的有效性,并且取得了重大的PR效果。AlphaGo不会写小说,它是专用的,不会做跨出它领域的其它事情,比如语音识别,人脸识别,自动驾驶,写小说或者理解小说。如果要写小说,需要用到自然语言处理(NLP))中的自然语言生成技术,那是人工智能领域一个", "answer_id": 545576062, "answerer_tags": "人工智能@游戏业"}

在该数据集上的公开评测和任务:
任务1: 话题预测。
报告包括:#1)验证集上准确率;#2)采用的模型、方法描述、运行方式,1页PDF;#3)可运行的源代码(可选)
基于#2和#3,我们会在测试集上做测试,并报告测试集上的准确率;只提供了#1和#2的队伍,验证集上的成绩依然可以被显示出来,但会被标记为未验证。
任务2:训练社区问答(cQA)系统。
要求:评价指标采用MAP,构建一个适合排序问题的测试集,并报告在该测试集上的效果。
任务3:使用该数据集(webtext2019zh),参考OpenAI的GPT-2,训练中文的文本写作模型、测试在其他数据集上的zero-shot的效果,或测评语言模型的效果。
5.翻译语料(translation2019zh)
520万个中英文平行语料( 原始数据1.1G,压缩文件596M)
数据描述
中英文平行语料520万对。每一个对,包含一个英文和对应的中文。中文或英文,多数情况是一句带标点符号的完整的话。
对于一个平行的中英文对,中文平均有36个字,英文平均有19个单词(单词如“she”)
数据集划分:数据去重并分成三个部分。训练集:516万;验证集:3.9万;测试集,数万,不提供下载。
可能的用途:
可以用于训练中英文翻译系统,从中文翻译到英文,或从英文翻译到中文;
由于有上百万的中文句子,可以只抽取中文的句子,做为通用中文语料,训练词向量或做为预训练的语料。英文任务也可以类似操作;
结构:
{"english": <english>, "chinese": <chinese>}
其中,english是英文句子,chinese是中文句子,中英文一一对应。
例子:
{"english": "In Italy, there is no real public pressure for a new, fairer tax system.", "chinese": "在意大利,公众不会真的向政府施压,要求实行新的、更公平的税收制度。"}
,数万,不提供下载。
可能的用途:
可以用于训练中英文翻译系统,从中文翻译到英文,或从英文翻译到中文;
由于有上百万的中文句子,可以只抽取中文的句子,做为通用中文语料,训练词向量或做为预训练的语料。英文任务也可以类似操作;
结构:
{"english": <english>, "chinese": <chinese>}
其中,english是英文句子,chinese是中文句子,中英文一一对应。
例子:
{"english": "In Italy, there is no real public pressure for a new, fairer tax system.", "chinese": "在意大利,公众不会真的向政府施压,要求实行新的、更公平的税收制度。"}
