一周SOTA:LMSYS Org开源LongChat、法律大语言模型ChatLaw、中文医疗对话模型扁鹊
1. LMSYS Org发布LongChat,上下文碾压64K开源模型
最近UC伯克利主导的LMSYS Org发布了大语言模型排位赛,刷新了大家对当下比较出名的开源和「闭源」聊天机器人的认识。
传送门:UC伯克利LLM排行榜再更新!GPT-4稳居第一,Vicuna-33B登顶开源模型第一
6月29日,来自LMSYS Org的研究人员发布了两个支持16k token上下文长度的开源大模型LongChat-7B和LongChat-13B,并测试了几个支持长上下文能力的几个大模型的实际表现。
目前支持长上下文的开源大模型已经有支持65K的 MPT-7B-storyteller 和32K的ChatGLM2-6B,闭源大模型比如 Claude-100K and GPT-4-32K,但LMSYS Org的研究人员还是选择通过测试来印证它们是「李鬼」还是「李逵」。
如何迅速有效地确认一个新训练的模型是否能够真地有效处理预期的上下文长度?
为了解决这个问题,研究团队可以基于需要LLM处理长上下文的任务进行评估,例如文本生成、检索、摘要和长文本序列中的信息关联。
研究人员们设计了一个名为LongEval的长上下文测试套件,包括两个难度不同的任务,提供了一种简单快捷的方式来衡量和比较长上下文的性能。
任务一:粗粒度主题检索
研究团队使用主题检索任务来模拟长对话中讨论会在多个主题之间跳转的场景。
这个任务会要求聊天机器人检索由多个主题组成的长对话中的第一个主题,测试模型是否能够定位长下文中的一段文本并将其与正确的主题名称相关联。


任务二:细粒度检索
为了进一步测试模型在长对话中定位和关联文本的能力,研究人员引入了更精细的行检索测试(Line Retrieval test)。在这个测试中,聊天机器人需要精确地从长文档中检索一个数字,而不是从长对话中检索一个主题。

LMSYS Org的研究人员考虑了4款开源和2款闭源大模型。

图注:表1:模型规格
根据粗粒度的主题检索测试结果(如下图),可以发现:
- 开源的长上下文模型的性能似乎没有宣传的那么好。例如,Mpt-7b-storywriter声称其上下文长度为84K,但即使在其声称的上下文长度(16K)的五分之一时,也只能勉强达到50%的准确率。
- ChatGLM2-6B在长度为 6K 时无法可靠地检索到第一个话题(仅46%的准确率),当在大于 10K 的上下文长度上进行测试时,其准确率几乎为0%。
- LongChat-13B-16K模型能可靠地检索到第一个主题,其准确率与gpt-3.5-turbo相当。
- 闭源的商业长上下文模型很能打,在长距离主题检索任务上,gpt-3.5-16K 和 Anthropic Claude 的基准测试几乎都达到了完美的性能。
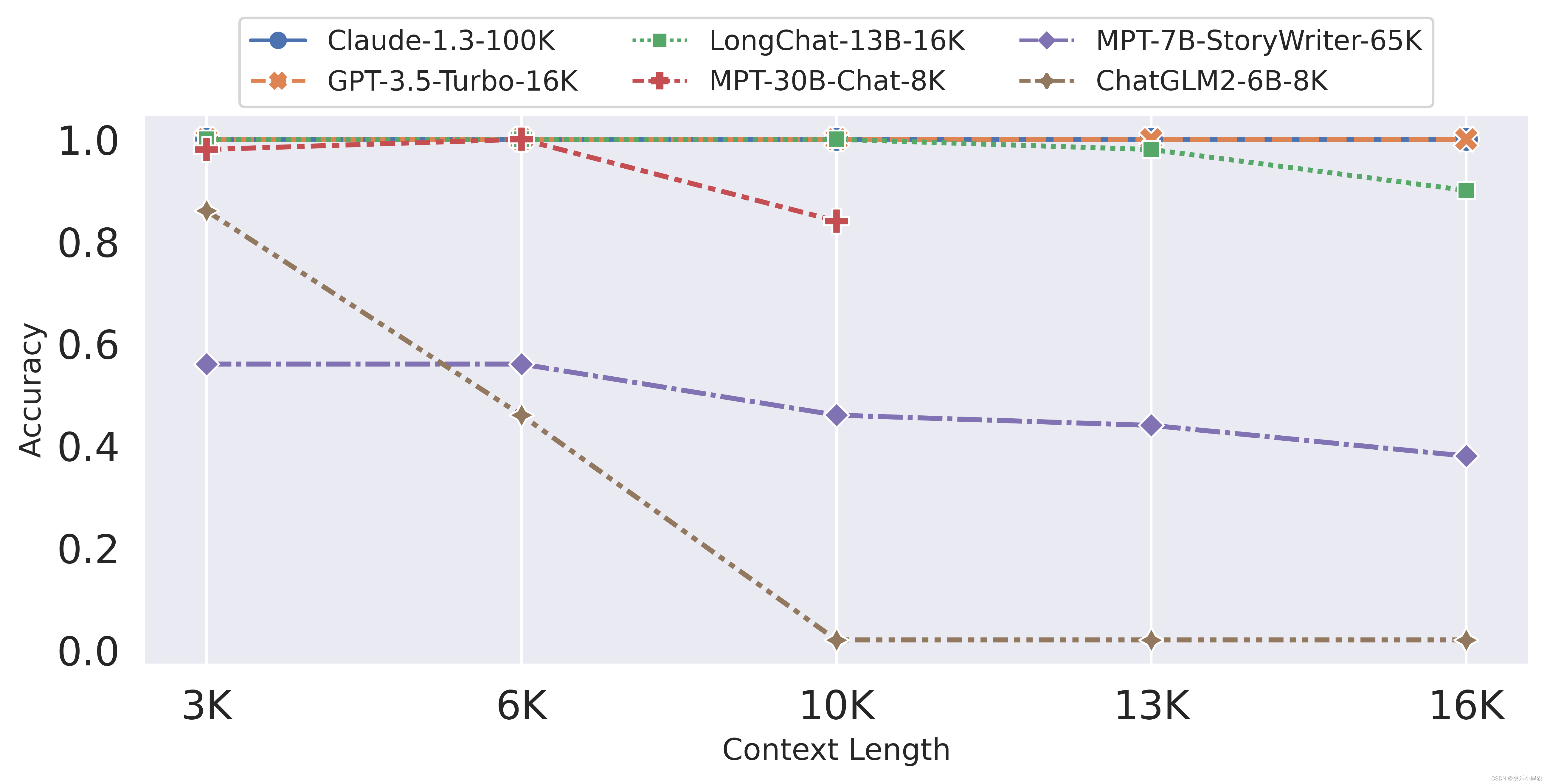
图注:(任务一:粗粒度主题检索)在长距离主题检索任务上比较LongChat与其他模型
在更细粒度的行检索测试中,可以发现:
- Mpt-7b-storywriter的表现甚至比粗粒度的情况更差,准确率从约50%下降到约30%。
- ChatGLM2-6B也出现下降,在最短长度(5K上下文长度)上表现不佳(准确率为32%)。
- 相比之下,LongChat-13B-16K表现可靠,在12K上下文长度内实现了接近gpt-3.5/Anthropic-claude的能力。
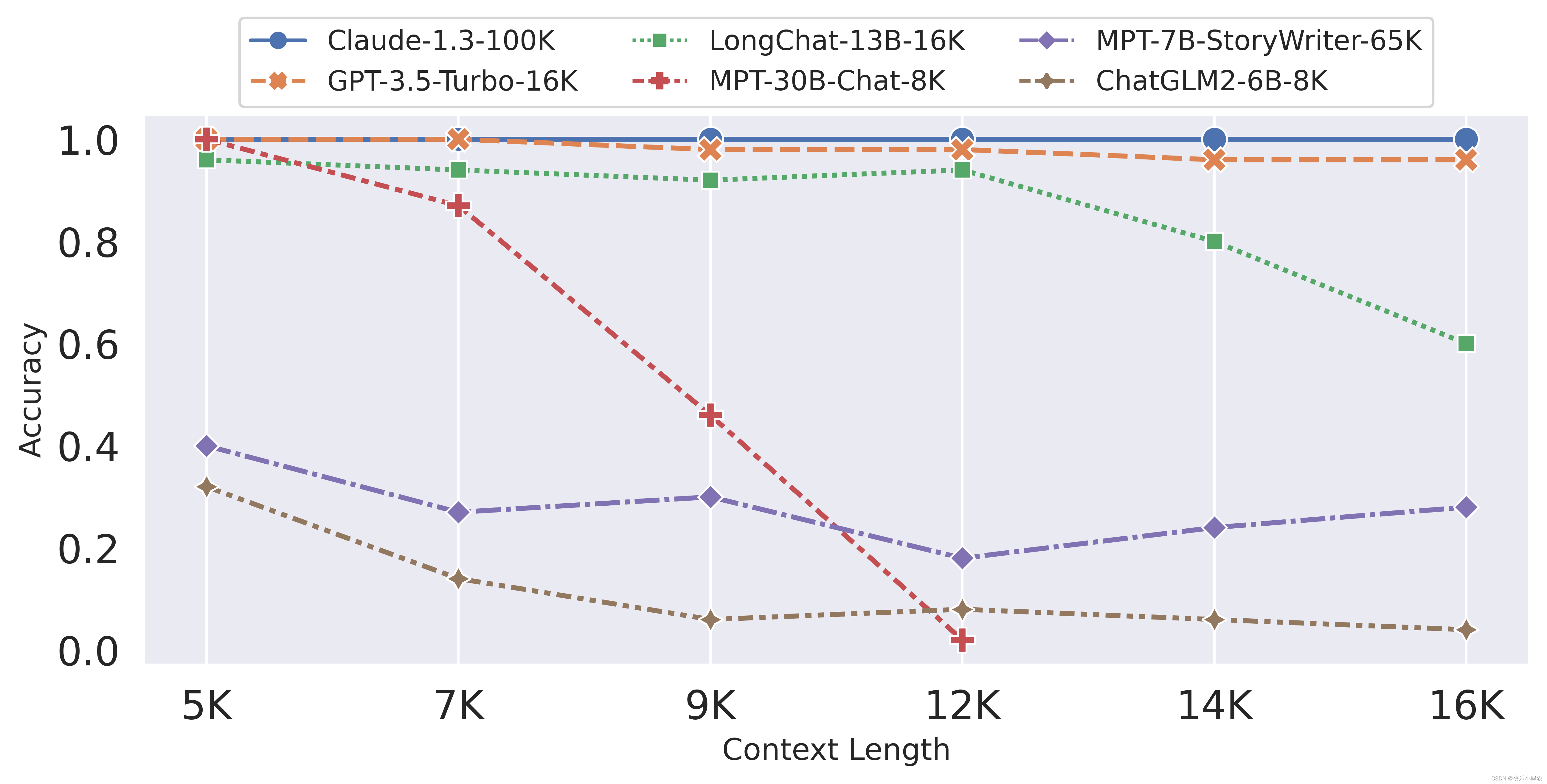
图注:(任务二:细粒度检索)长距离行检索任务的准确率
LongChat 通过压缩旋转嵌入技术,对从 ShareGPT 收集的用户共享对话分别微调 llama-7b、llama-13b 得到。评估结果表明,LongChat-13B 的远程检索准确性比其他长上下文模型高出 2 倍,包括 MPT-7B-storywriter(65K)、MPT-30B-chat(8K)和 ChatGLM2-6B(32k)。
LongChat模型在长距离检索任务上表现良好,但这是否会导致人类偏好显著下降呢?
研究人员使用了GPT-4评分的MT-bench测试LongChat是否仍然符合人类的偏好。结果发现:
- LongChat-13B-16K 与其最接近的替代模型Vicuna-13B相比,确实在MT-Bench分数上略有下降,但在可接受的范围内,这表明这种长距离能力并没有显著牺牲其短距离能力。
- LongChat-13B-16K 与其他相同规模的模型(Baize-v2-13B, Nous-Hermes-13B, Alpaca-13B)相比也具有竞争力。

图注:表2. LongChat-13B与其他类似规模的模型比较MT-bench得分
2. 北大团队发布法律大模型 ChatLaw
北大团队发布了首个中文法律大模型落地产品ChatLaw,为大众提供普惠法律服务。模型支持文件、语音输出,同时支持法律文书写作、法律建议、法律援助推荐。
ChatLaw 是一个法律大型语言模型,可以集成外部知识库,并基于姜子牙-13B 和 Anima-33B 进行训练,具有较强的逻辑推理能力。
目前开源了三个模型型号:ChatLaw-13、ChatLaw-33B、ChatLaw-Text2Vec。
- ChatLaw-13B 是学术 demo 版,中文表现良好,但在逻辑复杂的法律问答方面效果不佳,需要使用更大参数的模型。
- ChatLaw-33B 是学术 demo 版,逻辑推理能力大幅提升,但由于语料库过少,会出现英文数据。
- ChatLaw-Text2Vec 使用 93w 条判决案例做成的数据集基于 BERT 训练了一个相似度匹配模型,可以将用户提问信息和对应的法条相匹配。
论文地址:https://arxiv.org/abs/2306.16092
开源地址:https://github.com/PKU-YuanGroup/ChatLaw
官方地址:https://www.chatlaw.cloud/

ChatLaw 法律大型语言模型
3. 扁鹊:指令与多轮问询对话联合微调的医疗对话大模型
扁鹊是一个中文医疗对话模型,当前发布两个版本 扁鹊-1.0 和 扁鹊-2.0。相比常见开源医疗问答模型,扁鹊更注重多轮交互中用户描述不足的情况,定义了询问链并强化了建议和知识查询能力。
- 扁鹊-1.0 是一个经过指令与多轮问询对话联合微调的医疗对话大模型,使用超过 900 万条样本的中文医疗问答指令与多轮问询对话混合数据集训练得到。
- 扁鹊-2.0 则基于扁鹊健康大数据 BianQueCorpus,选择 ChatGLM-6B 作为初始化模型,经过全量参数的指令微调训练得到,并扩充了药品说明书指令、医学百科知识指令以及 ChatGPT 蒸馏指令等数据,强化了模型的建议与知识查询能力。

开源地址:https://github.com/scutcyr/BianQue
HuggingFace地址:https://huggingface.co/spaces/scutcyr/BianQue
该项目由华南理工大学未来技术学院-广东省数字孪生人重点实验室发起的,开源了中文领域生活空间主动健康大模型基座ProactiveHealthGPT,包括:(1) 经过千万规模中文健康对话数据指令微调的生活空间健康大模型扁鹊 (BianQue) ;(2) 经过百万规模心理咨询领域中文长文本指令与多轮共情对话数据联合指令微调的心理健康大模型灵心 (SoulChat)。

图注:中文领域生活空间主动健康大模型基座ProactiveHealthGPT
模型开源链接如下:
扁鹊 (BianQue):https://github.com/scutcyr/BianQue
灵心 (SoulChat):https://github.com/scutcyr/SoulChat

欢迎各位关注我的个人微信公众号:HsuDan,我将分享更多自己的学习心得、避坑总结、面试经验、AI最新技术资讯。

参考:
https://lmsys.org/blog/2023-06-29-longchat/
https://www.zhihu.com/question/610072848/answer/3101663890
https://www.chatlaw.cloud/
https://www.163.com/dy/article/I70BJ9U00552UJUX.html
https://github.com/scutcyr/BianQue
https://www.ppmy.cn/news/52419.html?action=onClick