Paper name
Fine-Tuning Language Models from Human Preferences
Paper Reading Note
Paper URL: https://arxiv.org/pdf/1909.08593.pdf
Blog URL: https://openai.com/research/fine-tuning-gpt-2
Code URL: https://github.com/openai/lm-human-preferences
TL;DR
- OpenAI 19 年出的文章,将自然语言处理的模型预训练与人类偏好学习相结合,该文章的思路是当前火热的 RLHF 的雏形方案
Introduction
背景
- 奖励学习使强化学习(RL)能够应用于由人类判断定义奖励的任务,通过向人类提问建立奖励模型
- 大多数关于奖励学习的工作都使用了模拟环境,但关于价值观的复杂信息通常用自然语言表达,本文认为语言的奖励学习是使 RL 在现实世界任务中实用和安全的关键
- 当 agent 必须与人类进行通信以帮助提供更准确的监督信号时,自然语言尤为重要
- 之前也有很多的方法将强化学习应用于自然语言任务
- 当前已有的奖励函数定义形式:
- 用于翻译的 BLEU
- 用于摘要的 ROUGE
- 用于故事生成的事件检测器等
- 对于翻译任务,使用 off-policy 来基于人工评测作为奖励
- 本文使用一个根据人类对文本补全任务的偏好训练的奖励模型来作为奖励函数
- 当前已有的奖励函数定义形式:
本文方案
- 本文在语言模型生成预训练的基础上,将奖励学习应用于四个自然语言任务(主要是文本续写和文本摘要):
- 使用积极情感进行文本续写
- 使用自然描述语言进行文本续写
- TL;DR 数据集上的摘要任务
- CNN/Daily Mail 数据集上的摘要任务
- 将自然语言处理的模型预训练与人类偏好学习相结合
- 使用根据人类对文本补全的偏好训练的奖励模型,通过强化学习而不是监督学习来微调预训练的语言模型
- 使用 KL 约束来防止微调后的模型偏离预训练的模型太远
- 本文工作的出发点
- 对于 NLP 任务,有监督数据集很难获取或者数据量很少
- 基于程序设计的奖励函数一般效果较差,难以实现准确的目标
- 本文方案结果
- 对于文本续写任务上的 5000 个对比样本,基于人工评测取得了不错的结果
- 人类评估方式:4 个续写结果中选择最好的结果
- 与 zero-shot 模型相比,RL 微调模型在 86% 情况下更被人类偏好
- 与有监督微调模型相比,RL 微调模型在 77% 情况下更被人类偏好
- 对于文本摘要任务,在 60000 个样本对数据上训练的模型可以实现从输入文本中复制几个句子,并跳过不相干的前言,这种方式在 ROUGE 评分和让标注员进行人工评测结果上来看都不错,但是这里的人工评测不一定靠谱,因为标注员也更倾向于简单的评估方式,认为出现在原文中的摘要句子是好摘要(标注过程并没有让标注员对整段句子的复制进行惩罚,只让标注员惩罚不准确的摘要)
- 对于文本续写任务上的 5000 个对比样本,基于人工评测取得了不错的结果
Dataset/Algorithm/Model/Experiment Detail
实现方式
-
对于语言模型 ρ \rho ρ ,定义了 token 序列上的概率分布
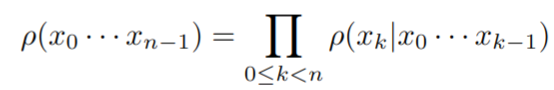
以摘要任务为例,模型的输入一般是最多 1000 字的文章,输出 y 可以是一个 100 个词的摘要。ρ 通过 ρ(y|x)=ρ(xy)/ρ(x)定义了该任务的概率策略:将样本的开头固定为 x,并使用 ρ 生成后续 token。 -
本文初始化策略 π=ρ,然后使用 RL 微调 π 以很好地执行任务。如果任务是由奖励函数r: X×Y定义的→ R,那么就可以使用 RL 来直接优化预期的奖励
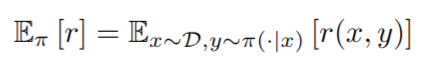
但是在这里本文期望让模型更符合人类的评价,这需要通过询问人类来获得奖励。本文首先基于人类标注来训练一个奖励模型,然后对奖励模型进行优化。 -
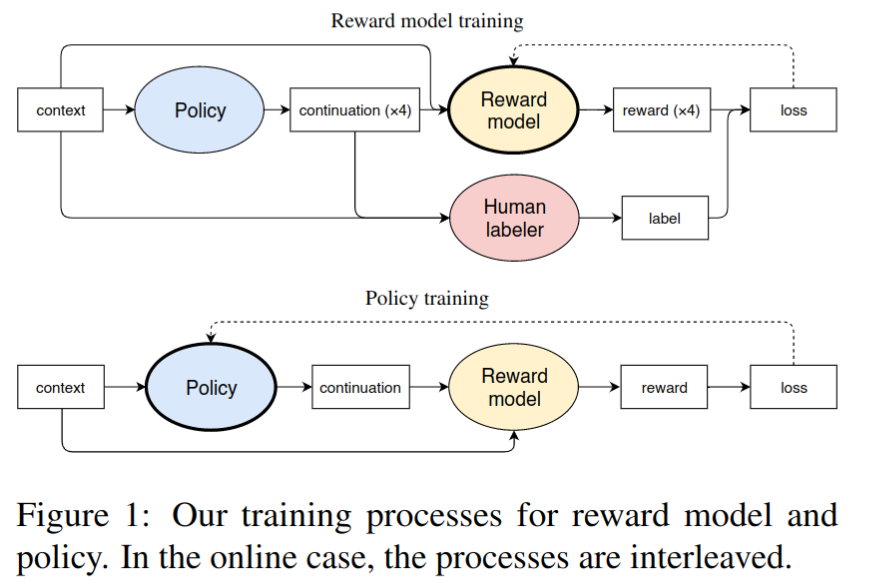
训练奖励模型
- 对于指定任务的输入 x,让人类标注员挑选最好的输出 yi
- 从四个输出 (y0, y1, y2, y3) 中挑选(可以考虑更多的选项来让人分摊阅读和理解提示 x 的成本,OpenAI 之后出的 InstructGPT 就采用了更多的选项设计)
- 基于标注的数据训练奖励模型,奖励模型就是在 ρ \rho ρ 模型输出 embedding 后增加一个线性层得到奖励值,正则化处理到均值为 0 ,方差为 1
- loss 设计如下,设计的思路是让模型对于人类喜好的回答输出更高的奖励
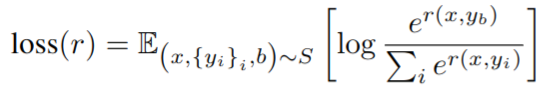
- 对于指定任务的输入 x,让人类标注员挑选最好的输出 yi
-
强化学习训练
- 为了避免强化学习微调的模型 π 和原始模型 ρ 差距太大,增加了一个基于 KL 散度计算的惩罚项
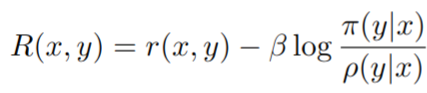
该项有熵加成的作用,防止 policy 偏移 r 有效范围太远;在风格文本续写任务下,这也是任务定义的重要组成部分:要求人类评估风格,但依靠 KL 散度来鼓励连贯性和话题性
- 为了避免强化学习微调的模型 π 和原始模型 ρ 差距太大,增加了一个基于 KL 散度计算的惩罚项
-
整体训练流程
- 收集人类标注数据,即让标注员在模型输出的 4 个回答中挑选最好的回答
- 基于预训练模型 ρ \rho ρ 对奖励模型 r r r 进行初始化,并基于人类标注数据对奖励模型进行训练
- 使用 Proximal Policy Optimization (PPO) 进行强化学习训练
- 对于在线数据收集的情况,继续收集额外的训练样本,并定期重新训练奖励模型 r r r
预训练模型细节
- 774 M GPT2 模型,在 WebText 数据集上进行训练,36 层,20 个 heads,embedding size 1280
- 对于风格续写任务,在 BookCorpus 数据集上进行有监督微调后再进行强化学习训练
- 为了提高样本质量,temperature 对于所有实验都使用小于 1 的值
- 修改方式为将语言模型输出 logits 除以 T
微调细节
- 奖励模型训练
- 训练 1 个 epoch 避免过拟合
- 风格续写 batchsize 为 8,摘要任务 batchsize 为 32
- 强化学习训练
- 使用 PPO2 的版本
- 2M 个数据对用于训练,共 4 个 epoch
- 风格续写 batchsize 为 1024,摘要任务 batchsize 为 512
- 用不同的种子和相同的 KL 惩罚 β 训练的模型有时会得到截然不同的 KL(π,ρ),这使得这些模型之间很难进行比较。为了解决这个问题,对于一些实验,本文使用对数空间比例控制器动态地改变 β,以达到 KL(π,ρ)的特定值
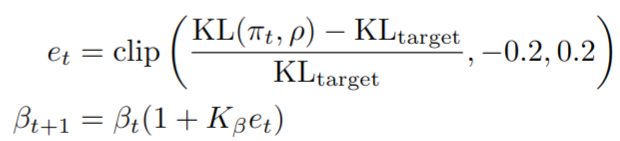
其中 K β = 0.1 K_{\beta}=0.1 Kβ=0.1,该部分在 huggingface trl 库中的实现代码示例:
class AdaptiveKLController:
"""
Adaptive KL controller described in the paper:
https://arxiv.org/pdf/1909.08593.pdf
"""
def __init__(self, init_kl_coef, target, horizon):
self.value = init_kl_coef
self.target = target
self.horizon = horizon
def update(self, current, n_steps):
target = self.target
proportional_error = np.clip(current / target - 1, -0.2, 0.2)
mult = 1 + proportional_error * n_steps / self.horizon
self.value *= mult
在线数据采集
- 如果训练后的策略 π 与零样本策略 ρ 有很大不同,则奖励模型将经历从 ρ 的样本训练到 π 的样本评估的巨大分布转变。为了防止这种情况,可以在整个 RL 微调过程中收集人类数据,通过从 π 采样和重新训练奖励模型来不断收集新数据
- 对于文本摘要任务在线数据采集很重要,简单的风格续写任务提升不大
- 计算开启第 n 个 step PPO 训练的需要 label 数目
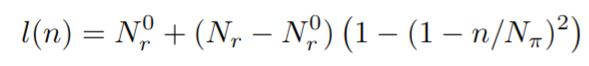
其中 Nπ=2x10^6 是 PPO 整体迭代数目, N r 0 = l ( 0 ) N_{r}^{0}=l(0) Nr0=l(0) 是人类标签的起始数目, N r N_{r} Nr 是人类标注的总数。如果第 n step 训练时的标注数据量小于 l(n) 就会暂停训练。如果到目前为止的请求总数小于 l(n)+1000,会向标注员发送另一批请求,以确保他们在任何时候都有至少 1000 个未完成的标注样本。在第一次 PPO 开启前训练奖励模型,然后以均匀间隔的 l(n) 值再训练 19 次。每次重新训练时,都会将奖励模型 r 重新初始化为预训练模型 ρ 顶部并在顶部添加随机线性层,并通过迄今为止收集的标签进行一个 epoch 训练
实验结果
风格续写任务
-
采样 32 到 64 个 token 的原始文本,续写 24 个额外的 token
-
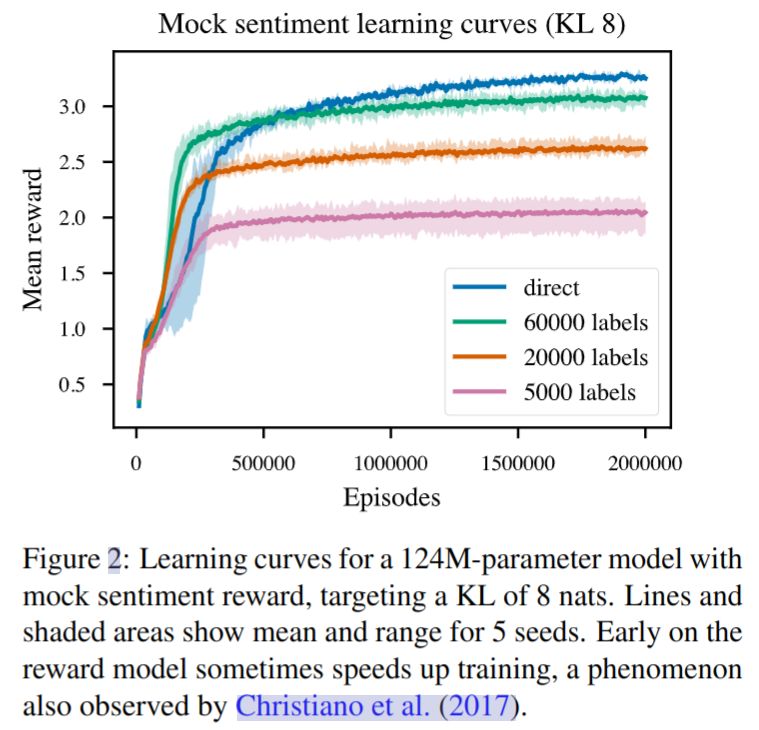
在一个模拟风格续写任务上的实验
- 使用一个已有的成熟模型用于对续写的文本进行分类(消极或积极),基于该模型作为奖励模型进行强化学习训练
- 实验结果如下,direct 为直接进行 RL 训练,其他的表示使用部分数据来对奖励模型进行微调,可以看到微调后能加速前期的收敛
-
因为知道奖励函数,所以也可以分析计算最优策略,并将其与学习的策略进行比较。约束学习策略 π 和语言模型 ρ 之间的 KL(π,ρ),最优策略具有以下形式
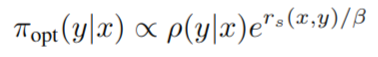
对于给定的 x 和 β,通过从 ρ(y|x) 中采样大量连续项并用 e r s ( x , y ) / β e^{r_{s}(x,y)/\beta} ers(x,y)/β 重新加权来近似该策略的回报。下图展示了本文方法和最优回报的差距
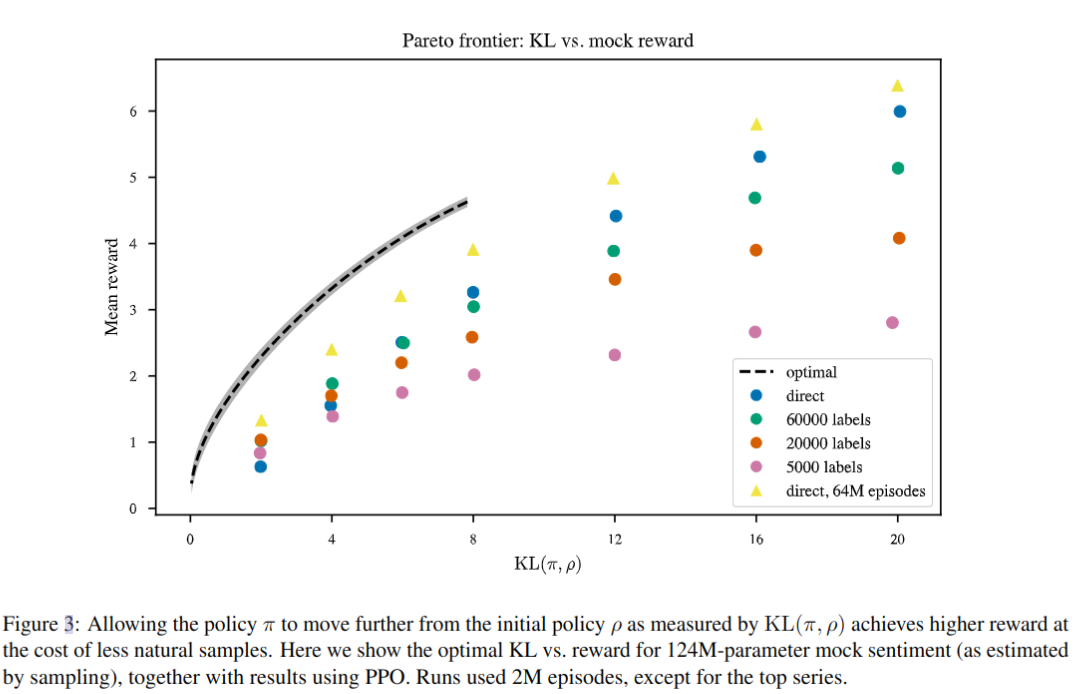
-
在风格续写任务上的人工评测结果,评测方式是三个人同时评测,投票数多的答案算更优,可以看到微调后的模型相比于 zero-shot 有一定提升
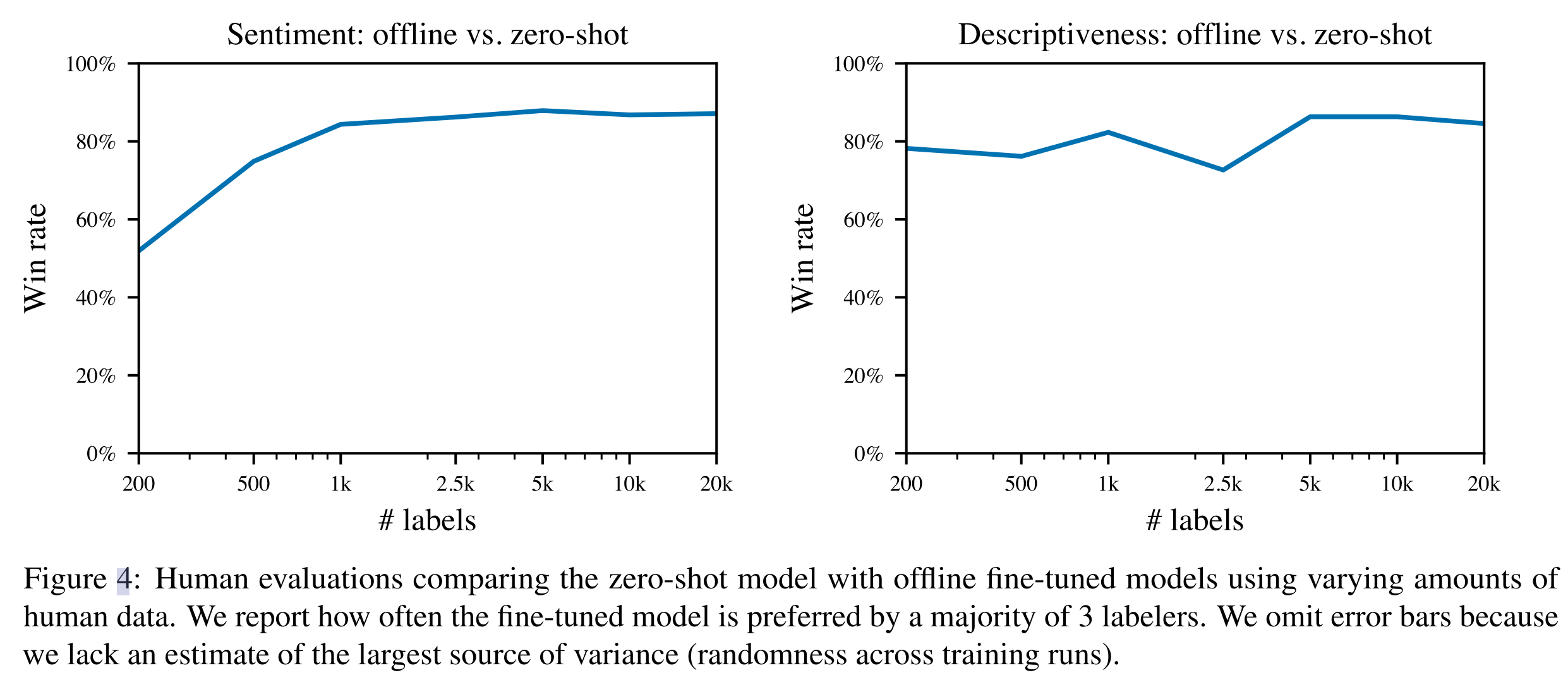
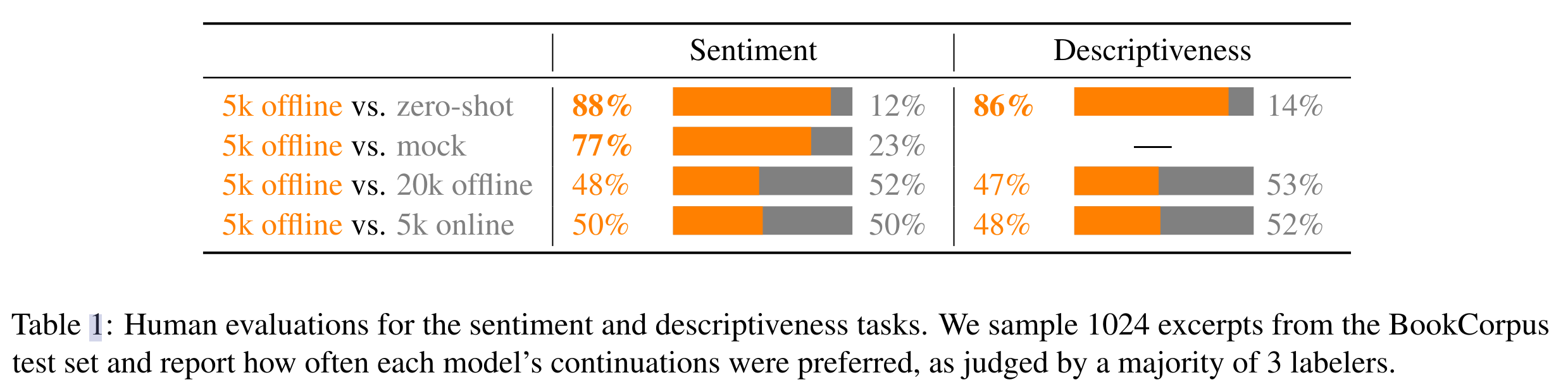
-
一些续写结果展示
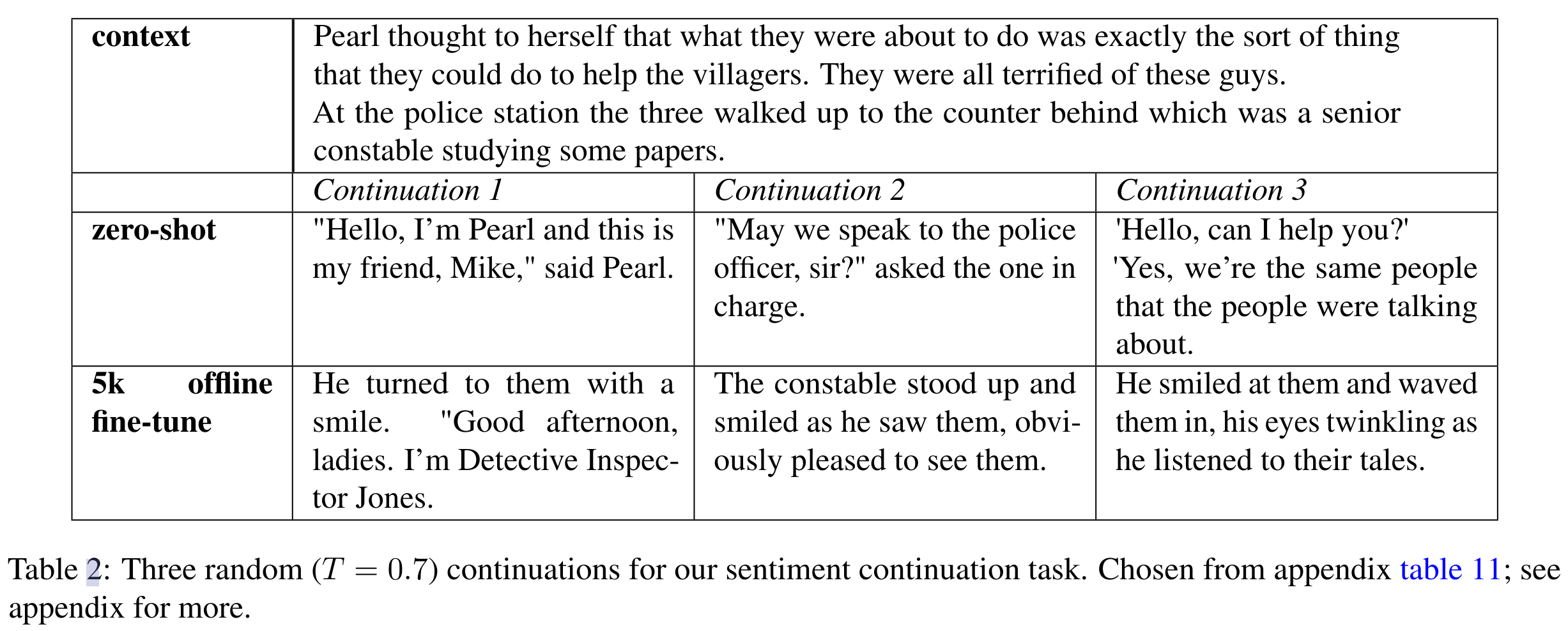
摘要任务
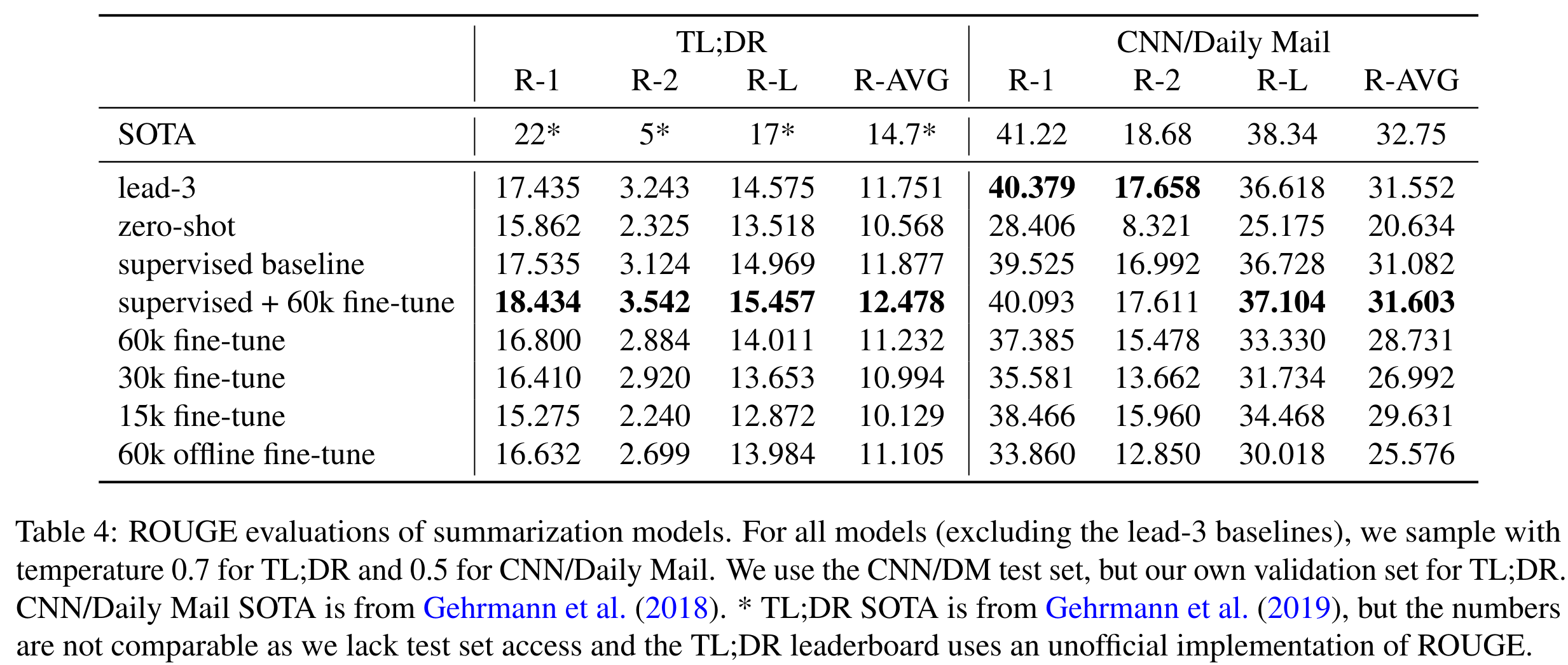
-
ROUGE 评分对比。可以看到有监督微调+强化学习训练结果最佳。online 数据在摘要任务中是有用的
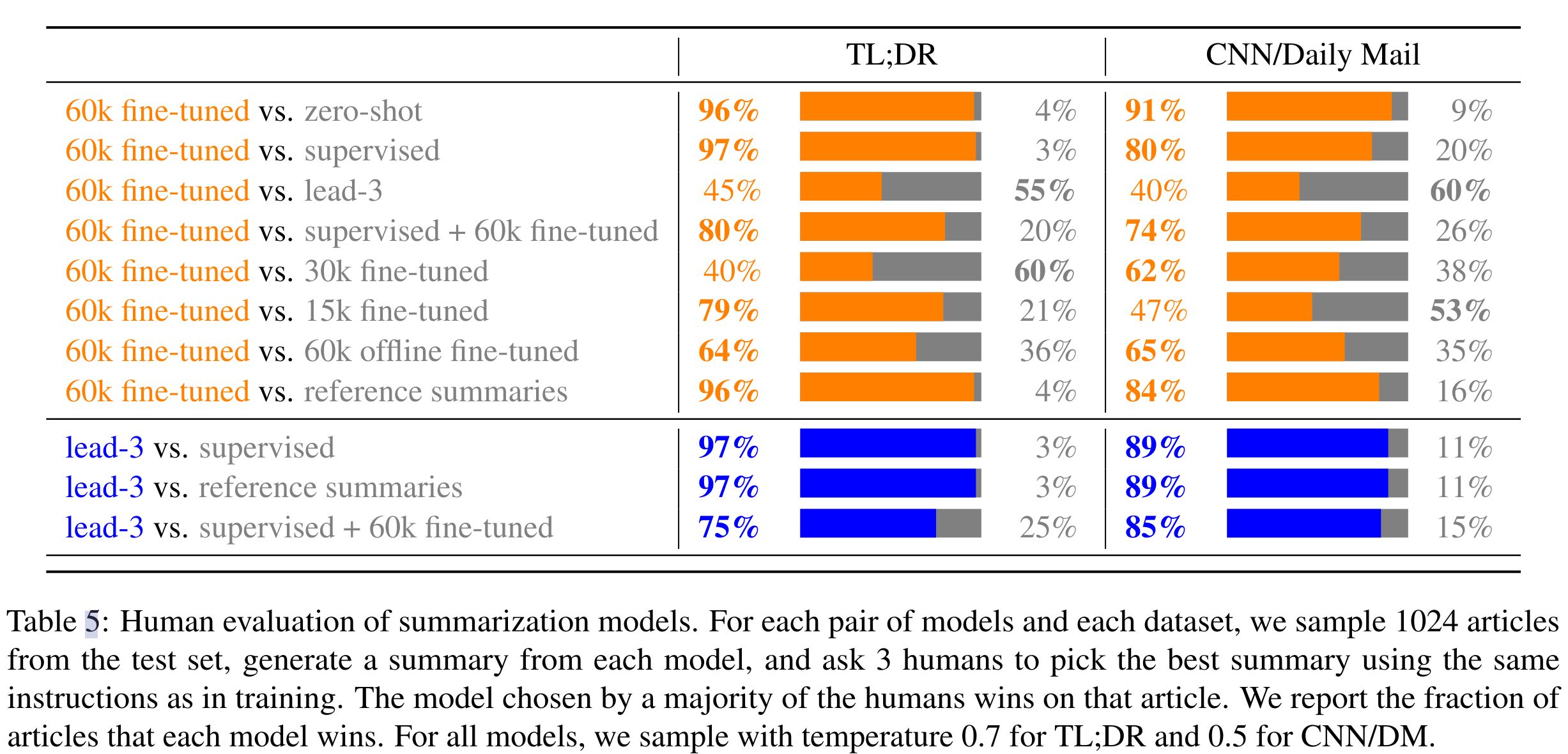
-
人工评测。lead-3 是个取前三行句子作为摘要的 baseline,分数高可能是因为标注员一般认为这样复制句子就比较准确
Thoughts
- OpenAI 早期工作,思路流程和最新的 RLHF 流程已经很接近了,论文中并没有现在看起来惊艳的精度,不过提供了一个基于人类反馈进行微调的方案雏形
- 本文总结的未来挑战
- 在线收集数据困难:
- 工程实现复杂度高,需要支持数据收集,奖励模型训练,强化学习训练的分布式进行;整个流程中一个环节出现了 bug 也会导致系统的崩溃
- 机器学习复杂度:在线系统 debug 困难。通常只能通过短暂地切换到脱机状态来调试在线作业
- 数据质量控制
- 奖励模型和强化学些 policy 模型共享参数会过拟合,无法作为多任务进行训练。多任务训练有很多优势,比如它可以帮助奖励模式保持足够强大,使 policy 模型无法投机取巧。共享还可以提高计算效率,允许模型共享激活,而不是需要两个单独的向前传递
- 标注难度大:很多语言回答难以区分优劣,使得数据中噪声很多
- 在线收集数据困难: