详细代码+企鹅2869955900
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.sans-serif'] = 'SimHei' # 设置中文显示
plt.rcParams['axes.unicode_minus'] = False
encodings = *****
for encoding in encodings:
try:
******
except UnicodeDecodeError as e:
print(f"{encoding} 编码解析失败")请分析附件 1 中排名前 250 名电影的上映年份主要集中在哪
data['上映年份']*
import seaborn as sns
# 数据准备
years = **
count = **
# 创建条形图
*
sns.barplot(x=years,y=count)
# 设置标题和轴标签
plt.title("电影数量分布(按年份)", fontsize=20)
plt.xlabel("上映年份", fontsize=16)
plt.ylabel("电影数量", fontsize=16)
# 旋转x轴刻度标签,以便更好地显示
plt.xticks(rotation=45)
plt.savefig('电影数量分布(按年份).png',bbox_inches = 'tight')
# 显示图像
plt.show()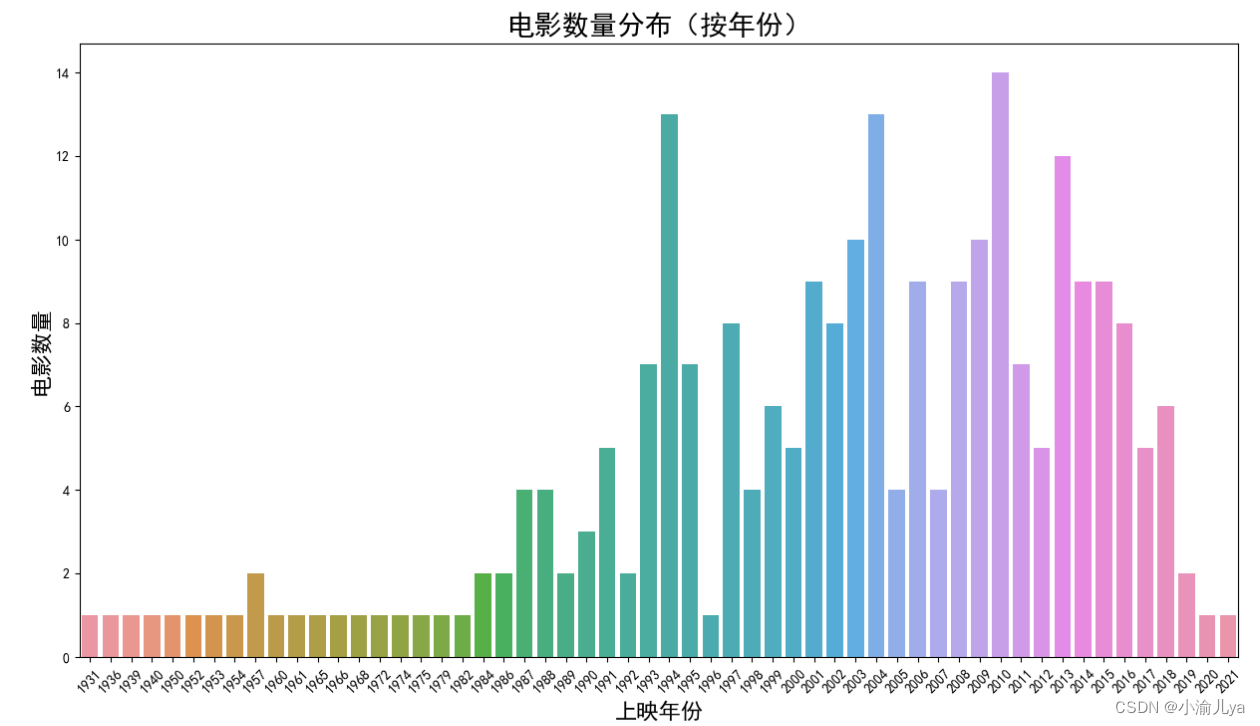
排名前 250 名电影的评分与评论人数、国家、导演和电影类型是否有关系?
data["国家_1"] = data["国家"]*
# 提取所有独立的电影类型
unique_genres = set()
*
# 对每个独立的电影类型创建一个新列,并根据原始数据填充 0 或 1(0表示该行电影不属于该类型,1表示属于)
for genre in unique_genres:
data[genre] = data['电影类型'].apply(lambda x: *)
# 指标皮尔逊相关分析初步判断指标之间是否具有线性相关
corr = *
plt.figure(figsize=(8, 8), dpi = 300)
sns.heatmap(corr, annot = True, vmax = 1, square = True, cmap = 'Blues')
plt.title('评分评论人数相关性热力图')
plt.savefig('评分评论人数相关性热力图.png',bbox_inches = 'tight')
plt.show()
# 按评分和导演进行分组统计
director_rating_counts = data.*
# 选择拍摄电影数量最多的前20位导演
top_directors = director_rating_counts.sum(axis=0).*
# 只保留这些导演的数据
filtered_director_rating_counts = *
# 创建热力图
plt.figure(figsize=(15, 8))
sns.heatmap(filtered_director_rating_counts, cmap='YlGnBu', annot=True, fmt='.0f')
# 设置标题和轴标签
plt.title("不同导演的电影评分统计(前20名)", fontsize=20)
plt.xlabel("导演", fontsize=16)
plt.ylabel("评分", fontsize=16)
plt.savefig('不同导演的电影评分统计(前20名).png',bbox_inches = 'tight')
# 显示图像
plt.show()
# 按评分和导演进行分组统计
director_rating_counts = data.groupby('评分')['国家_1'].value_counts().unstack().fillna(0)
*
filtered_director_rating_counts = director_rating_counts[top_directors]
# 创建热力图
plt.figure(figsize=(15, 8))
sns.heatmap(filtered_director_rating_counts, cmap='YlGnBu', annot=True, fmt='.0f')
# 设置标题和轴标签
plt.title("不同国家的电影评分统计(前20名)", fontsize=20)
plt.xlabel("国家", fontsize=16)
plt.ylabel("评分", fontsize=16)
plt.savefig('不同国家的电影评分统计(前20名).png',bbox_inches = 'tight')
# 显示图像
plt.show()
df = pd.DataFrame()
df = data.iloc[:,8::]
df['评分'] = data['评分']# 提取数据
df.head()
# 将评分列转换为整数(如果需要)
df['评分'] = df['评分'].astype(int)
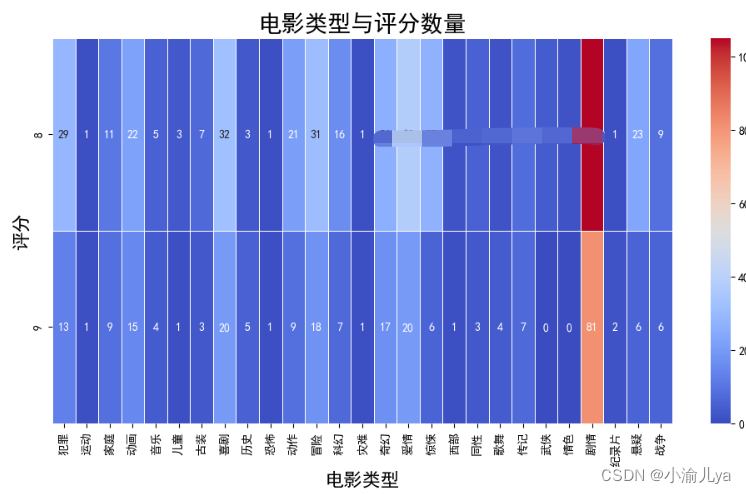
# 计算每个评分下电影类型的数量
pivot_table = df.*
# 创建热力图
plt.figure(figsize=(12, 6))
sns.heatmap(pivot_table, annot=True, cmap='coolwarm', linewidths=0.5)
plt.title("电影类型与评分数量", fontsize=20)
plt.xlabel("电影类型", fontsize=16)
plt.ylabel("评分", fontsize=16)
plt.savefig('电影类型与评分热力图.png',bbox_inches = 'tight')
# 显示图像
plt.show()