1.1图的定义
在线性表中,数据元素之间是被串起来的,仅有线性关系,每个数据元素只有一个直接前驱和一个直接后继。在前几个博客里的树结构中,数据元素之间有着明显的层次关系,并且每一层上的数据元素可能和下一层中多个数据元素有关,但只能和上一层中的一个元素相关,这就类似于一对父母可以有多个孩子,但多个孩子只能有一对父母是一样的。可先现实生活之中,朋友关系很复杂,可能我的两个朋友也互相认识,研究人际关系时我们就要考虑多对多的情况了,这就是我们这篇博客所要讲述的主题——图,图是一种较线性表和树更加复杂的数据结构。在图的结构中,结点之间的关系可以是任意的,图中任意两个数据元素之间都可能相关。
图:图是由顶点的有穷非空集合和顶点之间边的集合组成的,通常表示为G(V,E),其中,G表示一个图,V是图G中顶点的集合,E是图G中边的集合。
图的结构显示如下图所示(可以一个结点对应多个结点)
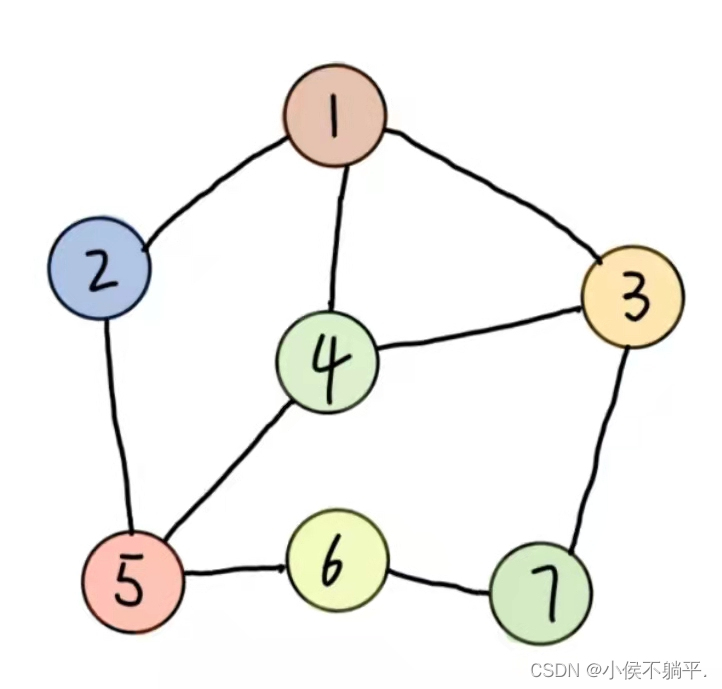
对于图的定义,我们需要明确的地方:
(1)线性表中我们把数据称为元素,树中将数据元素称为结点,在图中数据元素,我们称之为顶点(vertex)。
(2)线性表中可以没有数据元素,称为空表。树的结构之中也可以没有结点,称为空树。那么对于图而言,不允许没有顶点,在定义之中,顶点集合是非空且有穷。
(3)图中,任意两个顶点之间都可能有关系,顶点之间的逻辑关系用边来表示。
1.2 各种图的定义
无向边:若顶点vi到vj之间的边没有方向,则称这条边为无向边,用无序偶对(vi,vj)来表示。即(A,D)可以也写成(D,A)。
有向边:若从顶点vi到vj的边有方向,则称这条边为有向边,也称为弧(arc)。用序偶对<vi,vj>表示,vi表示弧尾,vj表示弧头。注意<A,D>表示弧,不能将其写成<D,A>。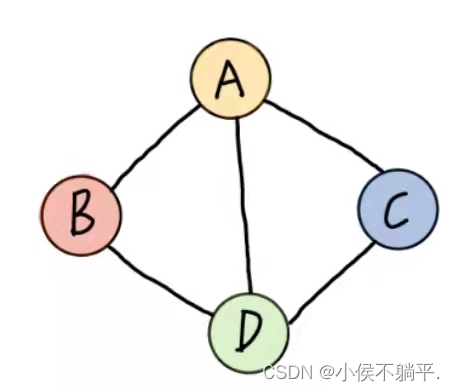
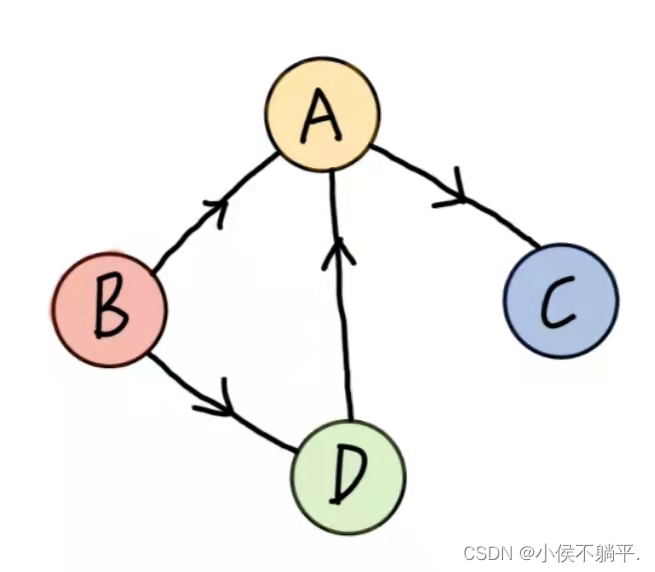
无向图 有向图
无向边用小括号()表示,而有向边则用尖括号<>表示。
在图中,若不存在顶点到其自身的边,且同一条边不重复出现,则称这样的图为简单图。
本篇博客讨论的都是简单图,显然下面的两个图不是简单图不属于我们讨论的范围之内。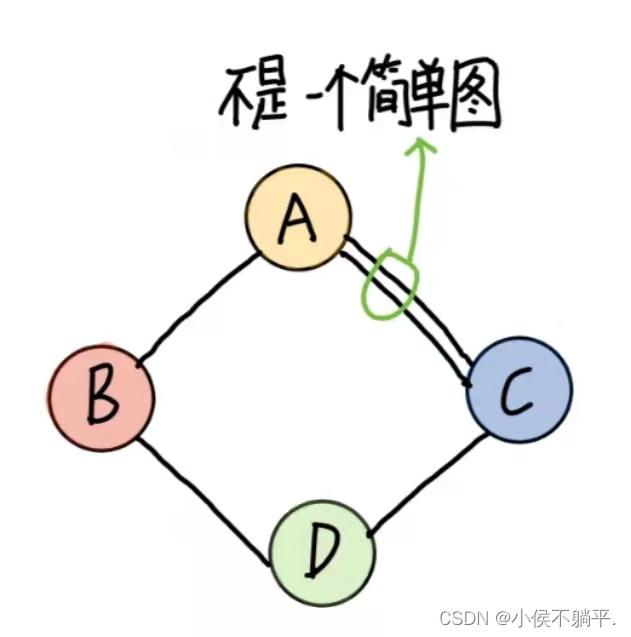
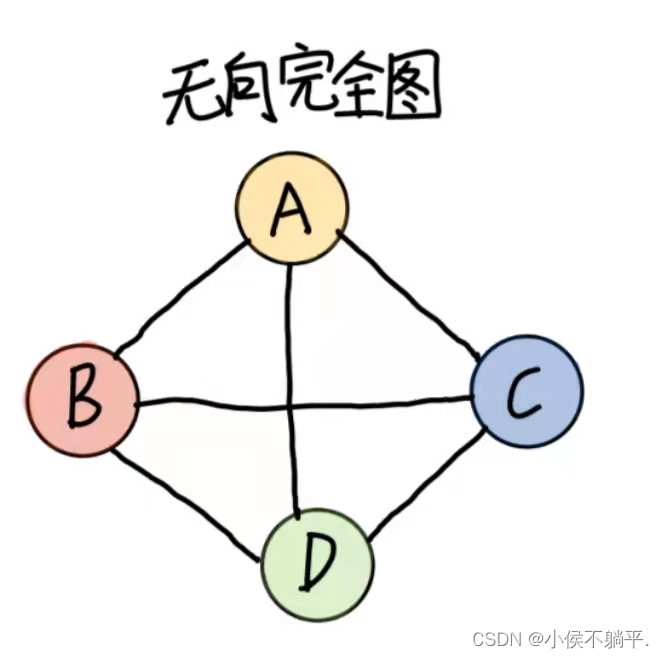
在无向图中,如果任意两个顶点之间都存在边,则称该图为无向完全图。含有n个顶点的无向完全图有n*(n-1)/2条边。如下图所示就是一个无向完全图,其中有四个顶点,(4*3)/2=6条边。
在有向图中,如果任意两个顶点之间都存在方向相反的两条弧,则称这样的图为有向完全图。含有n个顶点的有向完全图有n*(n-1)条边。
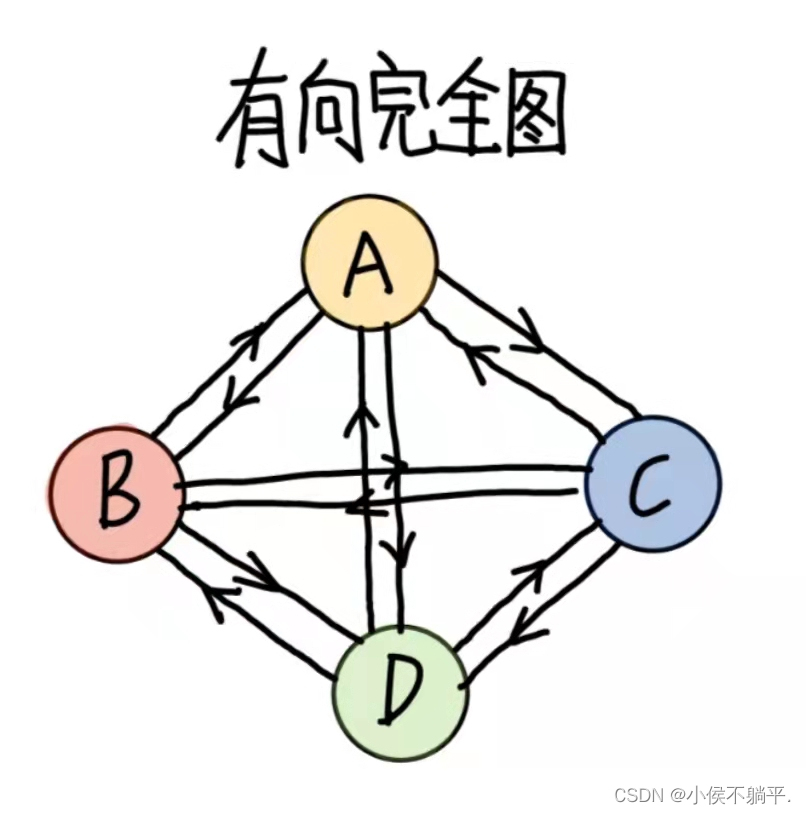
从这里可以得到的结论,对于具有n个顶点和e条边数的图,无向图0<=e<=n(n-1)/2,有向图0<=e<=n(n-1).
有很少条边和弧的图称为稀疏图,反之称为稠密图。这里的稀疏和稠密是模糊的概念,都是相对而言的。比如我去故宫时的参观人数差不多60万人,我个人感觉人数很多,可以用稠密来形容。可后来听说故宫最多一天的参观人数可达到130万人,对于130万人来说,60万有多么疏密啊!所以说这里的稠密和稀疏是相对而言的。
有些图的边或弧具有与它相关的数字,这种与图的边或弧相关的数叫权。这些权可以表示一个顶点到另一个顶点的距离或是耗费。这种带权的图通常称为网。
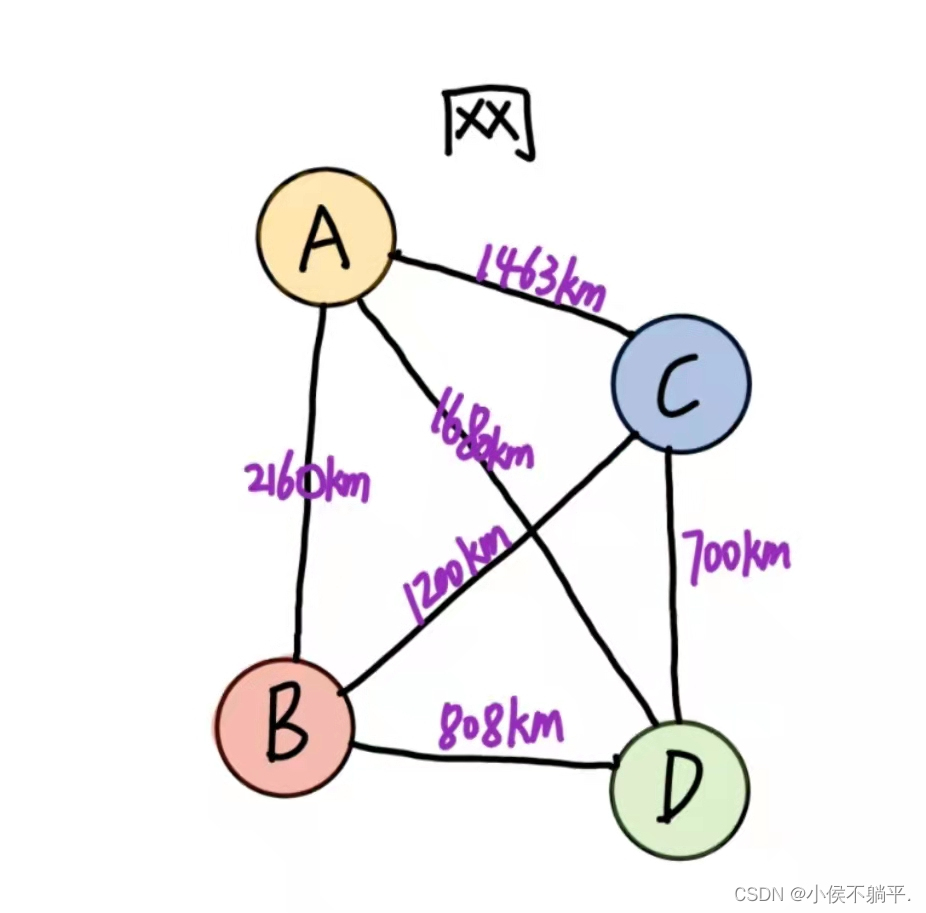
上图就是一个带权的图,上图中的权代表着两个顶点之间的距离。
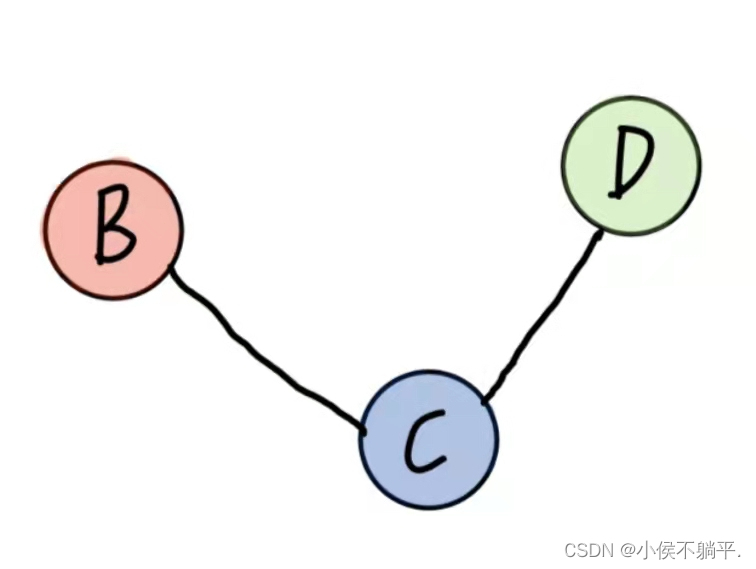
假设有两个图G=(V,{E})和G"=(V",{E"}),如果V"包含于V且E"包含于E,则称G"为G的子图。例如下图就是无向图的子图:
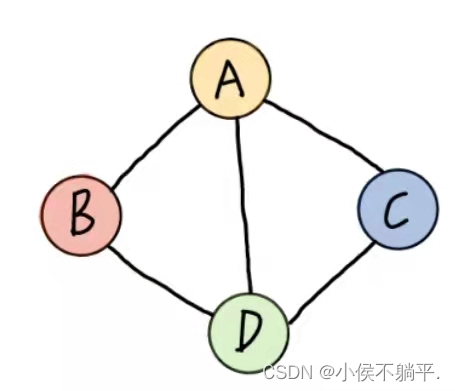
上图的子图如下所示:
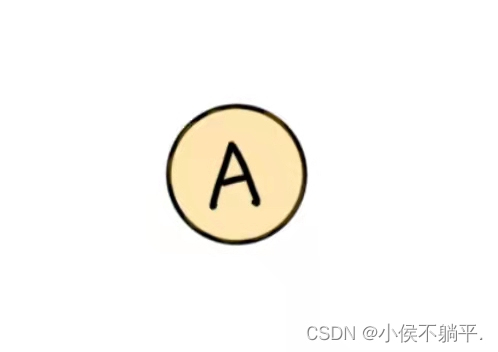
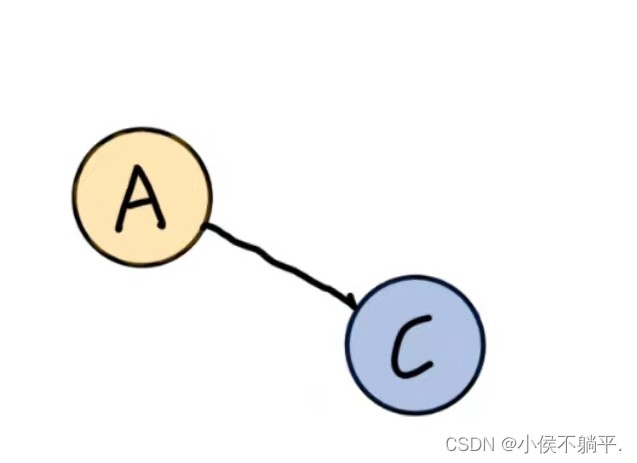
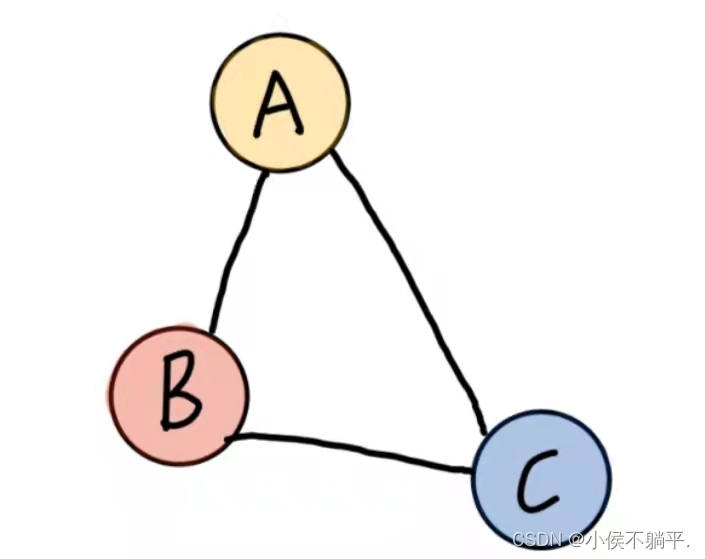
1.3 图的顶点和边之间的关系
对于无向图G=(V,{E'}),如果边(v,v')属于E,则称顶点v和v'互为邻接点,即v和v'相邻接。边(v,v')依附于顶点v和v',或者说(v,v')与顶点v和v'相关联。顶点v的度是和v相关联的边的数目,记TD(v).例如上图A顶点的度就为3。
对于有向图G=(V,{E'}),如果弧<v,v'>属于E,则称顶点v邻接到顶点v',顶点v'邻接自顶点v。弧<v,v'>和顶点v,v'相关联。以顶点v为头的弧的数目称为v的入度,记为ID(v);以v为尾的弧的数目称为v的出度,记为OD(v);顶点v的度为TD(v)=ID(v)+OD(v)。

无向图G=(V,{E})中从顶点v到顶点v'的路径是一个顶点序列。
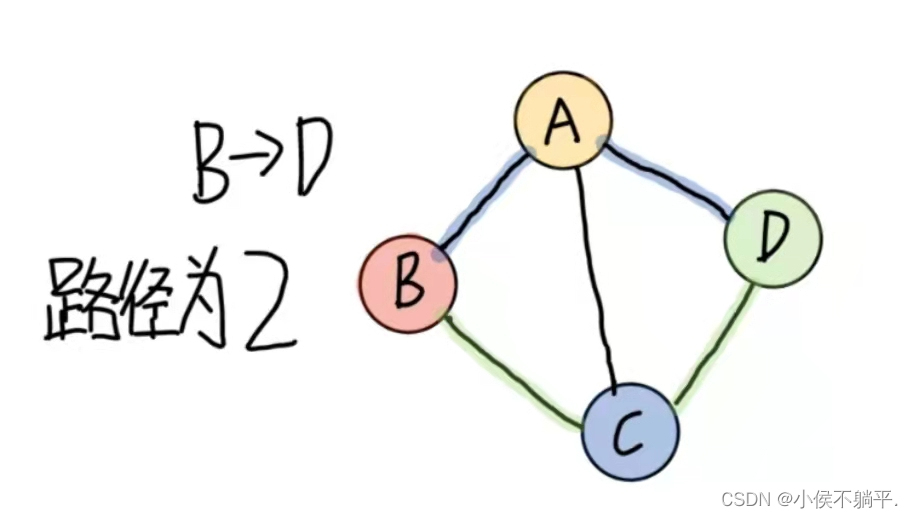
路径的长度就是路径上的边数或者弧的数目。
上图中b到d的路径一直都是2
第一个顶点和最后一个顶点相同的路径称为回路或环。序列中顶点不重复出现的路径称为简单路径。除了第一个顶点和最后一个顶点之外,其余顶点不重复出现的回路,称为简单回路或简单环。
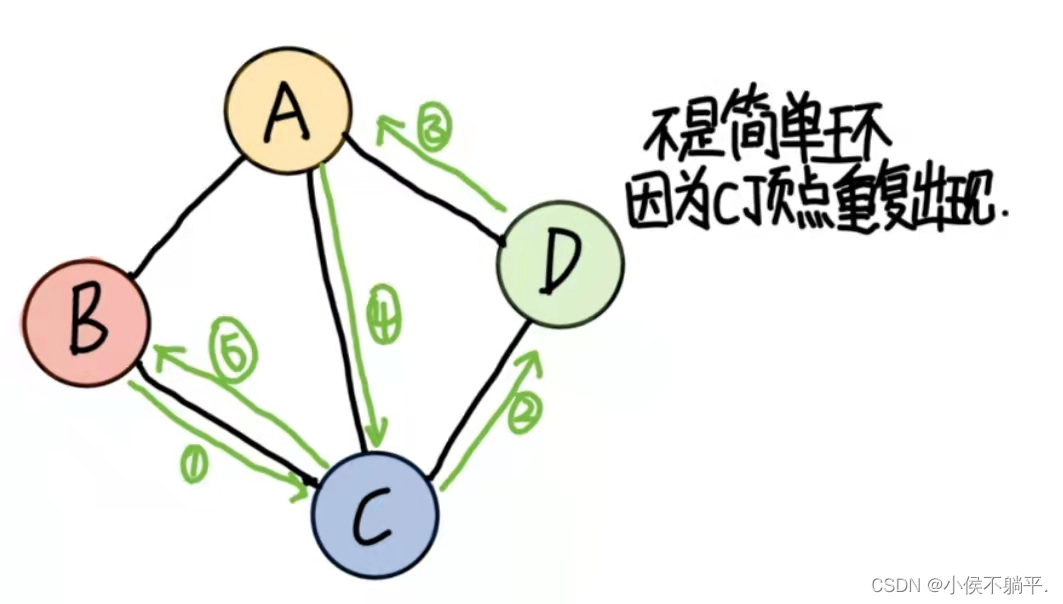
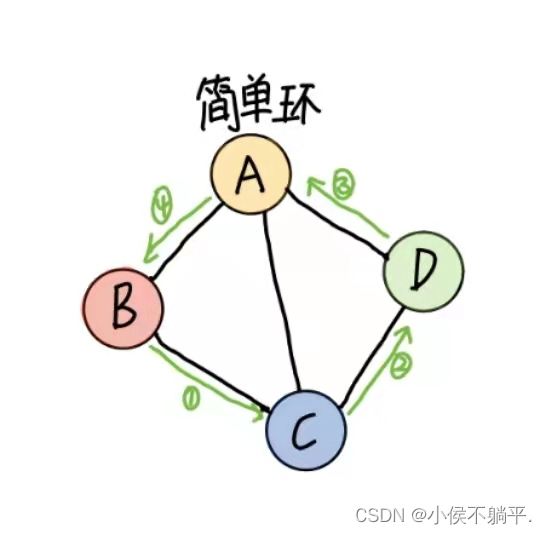
1.4 连通图的相关术语
在无向图G中,如果从顶点v到顶点v'有路径,则称v和v'是连通的。如果对于图中任意两个顶点vi,vj属于V,vi和vj都是连通的,则称G是连通图。
例图如下所示:
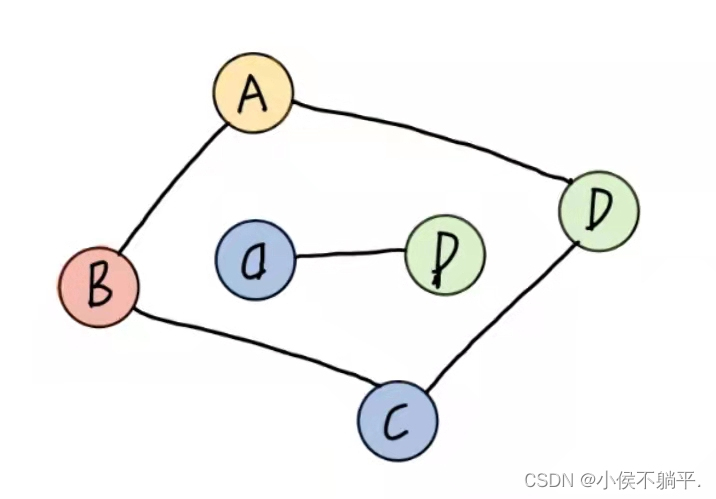
上图不是一个连通图因为o和p两个顶点除了和彼此相连接之时没有和其他的顶点相连
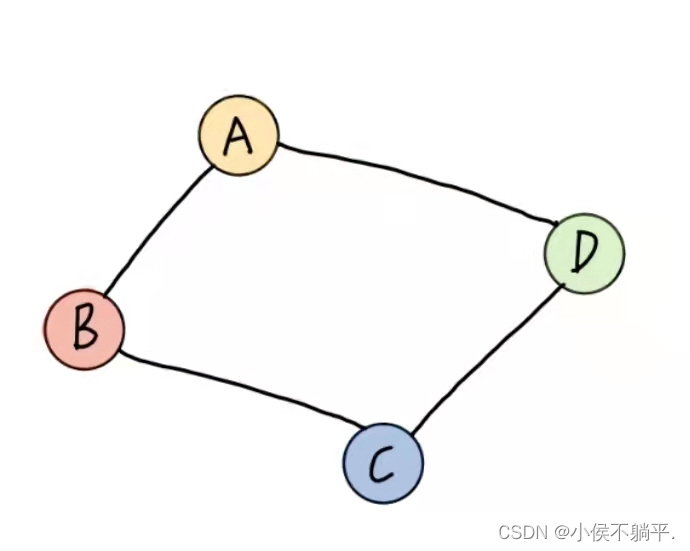
无向图中的极大连通子图称为连通分量。注意连通分量的概念,它强调:
(1)要是子图
(2)子图要是连通的
(3)连通子图含有极大顶点数
(4)具有极大顶点数的连通子图包含依附于这些顶点的所有边
在有向图G中,如果对于每一对vi,vj属于V、vi不等于vj,从vi到vj和vj到vi都存在路径,则称G是强连通图。有向图中的极大强连通子图称做有向图的强连通分量。
现在我们来看看连通图的生成树的定义。
所谓一个连通图的生成树是一个极小的连通子图,它含有图中全部的n个顶点,但只有足以构成一棵树的n-1条边。有n个顶点和n-1条边不一定全都是连通图的生成树。
例图如下所示:
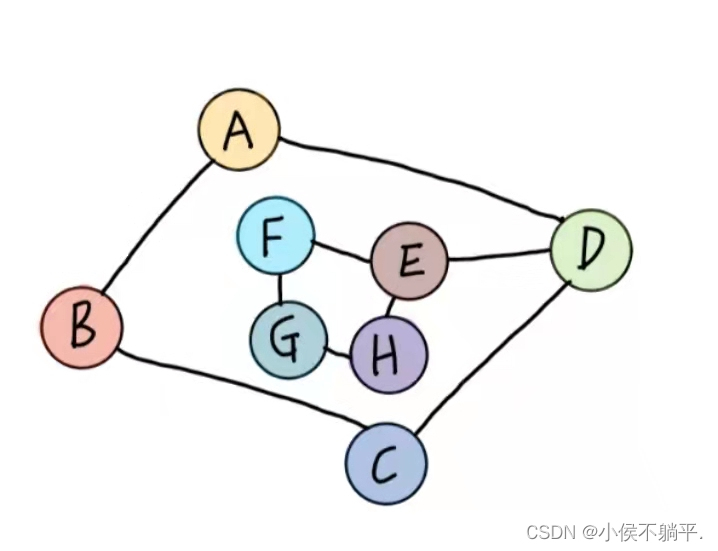
①连通图
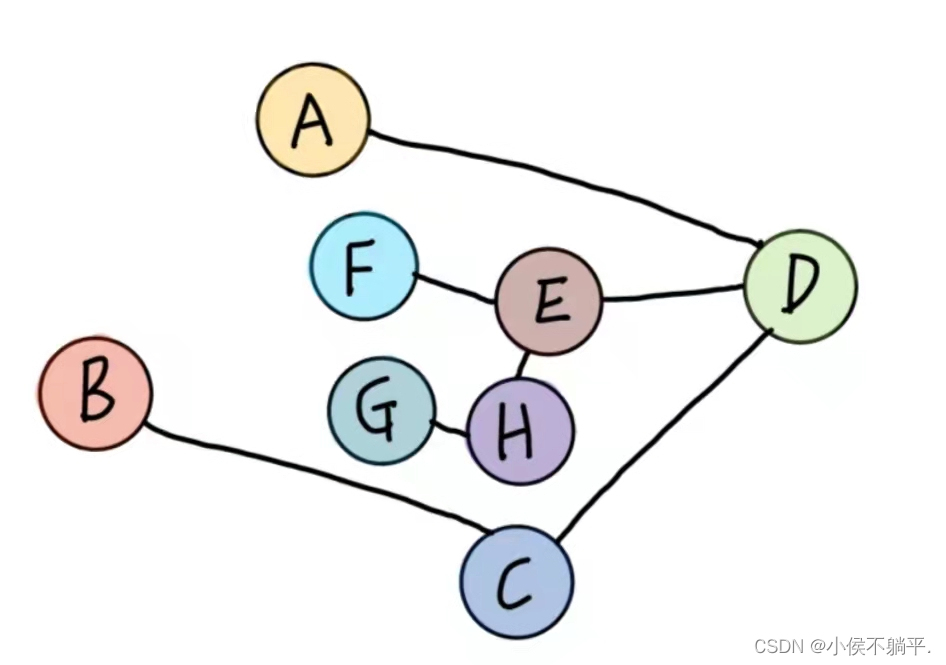
② 连通图的生成树
③条件满足但不是生成树
如果一个有向图恰有一个顶点入度为0,其余顶点入度均为1,则是一个有向树。对于有向树理解比较容易,所谓入度为0其实就是想当于树中的根结点,其余顶点入度为1就是说树的非根结点的双亲只有一个,一个有向图的生成森林由若干颗有向树组成含有图中的全部顶点,但只有足以构成若干颗不相交的有向树的弧。
1.5 图的定义与术语的总结
术语讲述的已经差不多了,我们来整体性的整理一下。
图按照有无方向分为有向图和无向图。有向图由顶点和弧构成,无向图由顶点和边构成。弧有弧尾和弧头之分。
图按照边或弧的多少分为稀疏图和稠密图。如果任意两个顶点之间都存在边叫完全图,有向的叫有向完全图。若无重复的边或顶点到自身的边则叫简单图。
图中顶点之间有邻接点和依附的概念。无向图顶点的边数叫度,有向图顶点分为入度和出度。
图上的边或弧上带权叫做网
图中顶点间存在路径,两顶点存在路径则说明是连通的,如果路径最终回到起始点则称为环,当中不重复叫简单路径。若任意两顶点都是连通的,则图就是连通图,有向则称为强连通图。图中有子图若子图极大连通图则就是连通分量,有向的则称为强连通分量。
无向图中连通且n个顶点n-1条边叫做生成树,有向图中一顶点入度为0其余顶点入度均为1的叫做有向树一个有向图有若干个有向树构成生成森林。
图的存储结构
1.1 邻接矩阵
图的邻接矩阵存储方式时用两个数组来表示图。一个一维数组存储图中的顶点信息,一个二维数组(称为邻接矩阵)存储图中的边和弧的信息。
存储的方式大概如下:
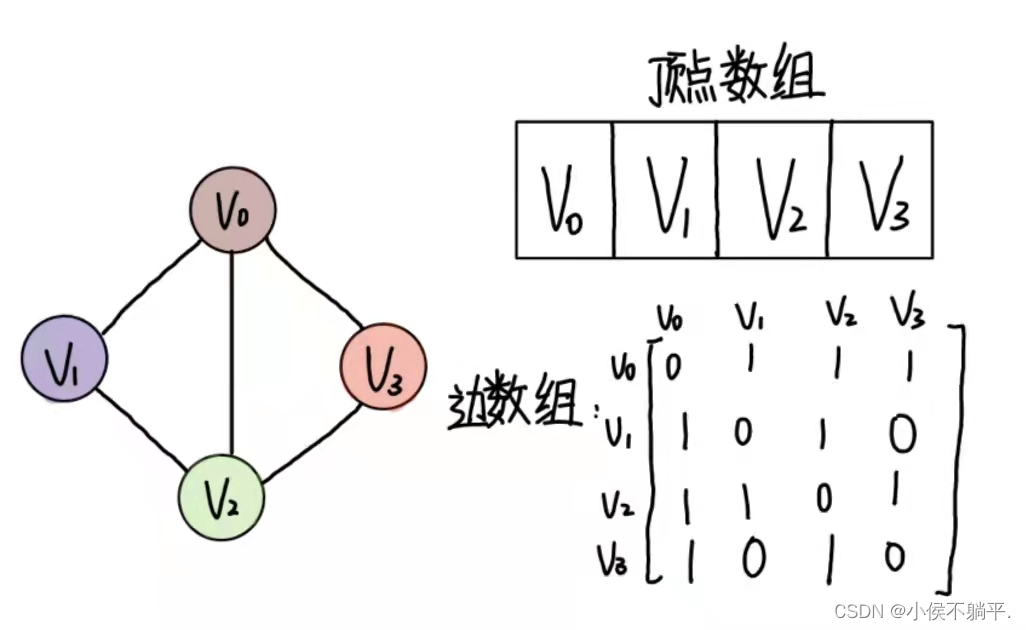
其中0表示顶点与顶点之间不存在边的关系,而1则反应的是两个顶点之间存在边的关系。在无向图之中边数组就是一个对称矩阵。如果想要加入权值是则将本来的0存为一个特别大的数字,对角线仍为0因为自己到自己本身的距离一直都是0,然后将存在边的顶点将1改为两定点之间的距离所以先在无向图仍然还是一个对称矩阵。
创建该结构的 结构体代码如下:
struct photo
{
char vex[10];
int arc[10][10]={0};
int numnodes, numdges;
};创建邻接表的代码和遍历邻接表存储好的结构代码如下所示:
#include<iostream>
#include<stdlib.h>
#include<iomanip>
using namespace std;
struct photo
{
char vex[10]; //存储顶点的数组
int arc[10][10]={0}; //存储数据的数组
int numnodes, numdges; //顶点数和边数
};
void creategraph(struct photo*G)
{
cout << "请输入顶点数和边数:" << endl;
cin >> G->numnodes >> G->numdges;
for (int i = 0; i < G->numnodes; i++)
cin >> G->vex[i];
for (int i = 0; i < G->numnodes; i++)
for (int j = 0; j < G->numnodes; j++)
G->arc[i][j] = 0;
for (int k = 0; k < G->numdges; k++)
{
int i, j;
cout << "请输入有边点数:(i,j)" << endl;
cin >> i>>j;
G->arc[i][j] = 1;
G->arc[j][i] = G->arc[i][j];
}
}
void print(struct photo* G)
{
for (int i = 0; i < G->numnodes; i++)
{
for (int j = 0; j < G->numnodes; j++)
{
cout <<setw(2)<< G->arc[i][j] << " ";
}
cout << endl;
}
}
int main()
{
struct photo* y;
y = (struct photo*)malloc(sizeof(struct photo));
creategraph(y);
print(y);
return 0;
}运行的结果如下图所示:

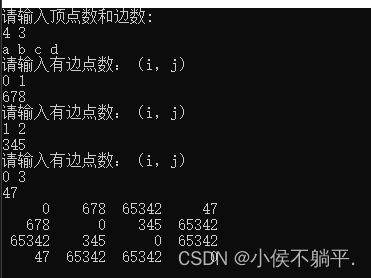
而邻接矩阵的加权的设置代码与上述代码差不多一致,如下所示:
struct photo
{
char vex[10]; //存储顶点信息
int arc[10][10] = { 65342 }; //先将其设置为无穷大
int numnodes, numdges; //存储顶点数和边数
};
void creategraph(struct photo* G)
{
cout << "请输入顶点数和边数:" << endl;
cin >> G->numnodes >> G->numdges;
for (int i = 0; i < G->numnodes; i++)
cin >> G->vex[i];
for (int i = 0; i < G->numnodes; i++)
for (int j = 0; j < G->numnodes; j++)
G->arc[i][j] = 65342;
for (int i = 0; i < G->numnodes; i++)
G->arc[i][i] = 0;
for (int k = 0; k < G->numdges; k++)
{
int i, j,w;
cout << "请输入有边点数:(i,j)" << endl;
cin >> i >> j >> w;
G->arc[i][j] = w; //将之前的1改为自己输入的数字
G->arc[j][i] = G->arc[i][j];
}
}
void print(struct photo* G)
{
for (int i = 0; i < G->numnodes; i++)
{
for (int j = 0; j < G->numnodes; j++)
{
cout <<setw(6)<<G->arc[i][j] << " ";
}
cout << endl;
}
}
int main()
{
struct photo* y;
y = (struct photo*)malloc(sizeof(struct photo));
creategraph(y);
print(y);
return 0;
}运行之后的代码如下图所示:
1.2 邻接表
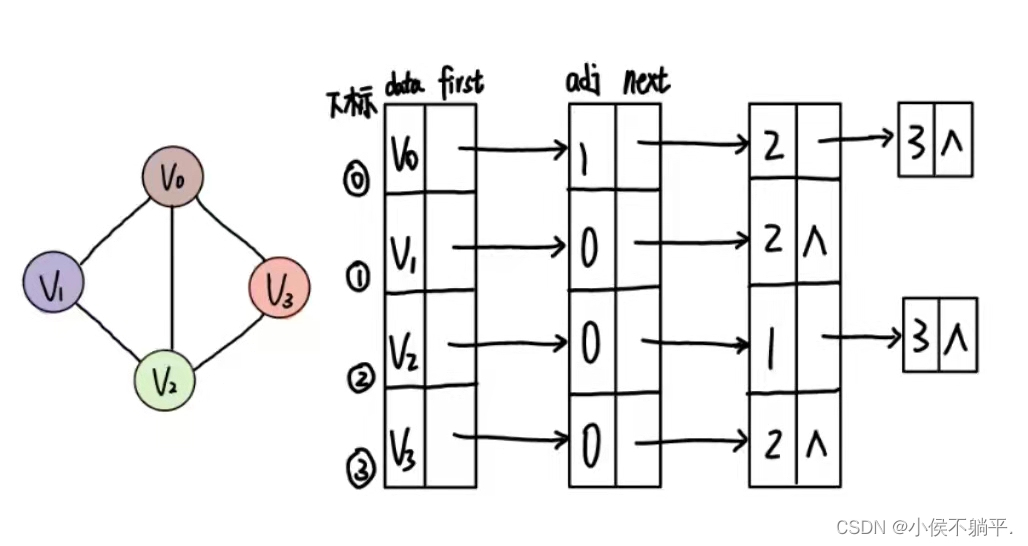
邻接矩阵是不错的一种图存储结构,但是我们发现,对于边数相对于顶点较少的图,这种结构是存在对存储空间的极大浪费的。于是我们考虑减少这种浪费,就想出了链式存储的结构。我们把这种数组和链表相结合的存储方式称为邻接表。
图中的顶点信息仍用一维数组存储还需要一个指针指向邻接表,但是所有的邻接点用一个链表表示,其中一个数据类型存储下标另一个数据元素指针指向下一个顶点存储的位置。
结构图如下所示:
结构体如下代码所示:
struct dege
{
int adv; //存储指向的坐标
struct dege* next; //指向下一个邻顶点
};
typedef struct vex
{
char data; //存储顶点数据
struct dege* first; //边表头指针
}adjlist[100];
struct nodes
{
adjlist adj;
int numnodes, numedges; //图中的顶点数和边数
};具体存储的实现的代码如下所示(没有进行遍历):
struct dege
{
int adv;
struct dege* next;
};
typedef struct vex
{
char data;
struct dege* first;
}adjlist[100];
struct nodes
{
adjlist adj;
int numnodes, numedges;
};
void create(struct nodes* G)
{
struct dege* e;
cout << "请输入顶点数目和边的数目:" << endl;
cin >> G->numnodes >> G->numedges;
for (int i = 0; i < G->numnodes; i++)
{
cin >> G->adj[i].data;
G->adj[i].first = NULL;
}
for (int k = 0; k < G->numedges; k++)
{
cout << "请输入有边的结点i,j:" << endl;
int i, j;
cin >> i >> j;
e = (struct dege*)malloc(sizeof(struct dege));
e->adv = j;
e->next = G->adj[i].first;
G->adj[i].first = e;
e = (struct dege*)malloc(sizeof(struct dege));
e->adv = i;
e->next = G->adj[j].first;
G->adj[j].first = e;
}
}
int main()
{
struct nodes* S;
S = (struct nodes*)malloc(sizeof(struct nodes));
create(S);
return 0;
}最终存储的数据如下(即运行之后的结果):

本篇博客匆匆的就到这里结束了,具体对图的深入讲解和遍历方式放在下一篇博客《数据结构之图的存储(下)》之中,看完这篇博客相信大家都对图有了一定的了解,大家可以思考一下图的存储方式是否还有更多,具体有哪些, 下一篇博客会给大家讲述其他的存储的方式和图的深度遍历和广度遍历的用法。
在追求自己美好的生活而努力,看起来和平凡人一样的努力。