论文题目:《VarGFaceNet: An Efficient Variable Group Convolutional Neural Network for Lightweight Face Recognition》
论文地址:https://arxiv.org/pdf/1910.04985v4.pdf
1.前言
许多工作提出了用于常见计算机视觉任务的轻型网络,例如SqueezeNet,MobileNet ,MobileNetV2,ShuffleNet,SqueezeNet。它们大量的使用1×1卷积,与AlexNet 相比,可减少50倍的参数,同时在ImageNet上保持AlexNet级别的准确性。MobileNet 利用深度可分离卷积来实现计算时间和准确性之间的权衡。基于这项工作,MobileNetV2 提出了一种倒置的bottleneck结构,以增强网络的判别能力。ShuffleNet 和ShuffleNetV2 使用逐点组卷积和通道随机操作进一步降低了计算成本。即使它们在推理过程中花费很少的计算并在各种应用程序上有良好的性能,但嵌入式系统上的优化问题仍然存在于嵌入式硬件和相应的编译器上。为了解决这个冲突,VarGNet 提出了一个可变组卷积,可以有效地解决块内部计算强度的不平衡。同时,作者探索了在相同卷积核大小的情况下,可变组卷积比深度卷积具有更大的学习能力,这有助于网络提取更多的信息。但是,VarGNet是针对常用任务设计的,例如图像分类和目标检测。它将头部的空域减小到一半,以节省内存和计算成本,而这种方式并不适合人脸识别任务,因为它需要更详细的面部信息。而且,在最后的conv和全连接层之间,只有一个平均池化层,可能无法提取足够的区分性信息。
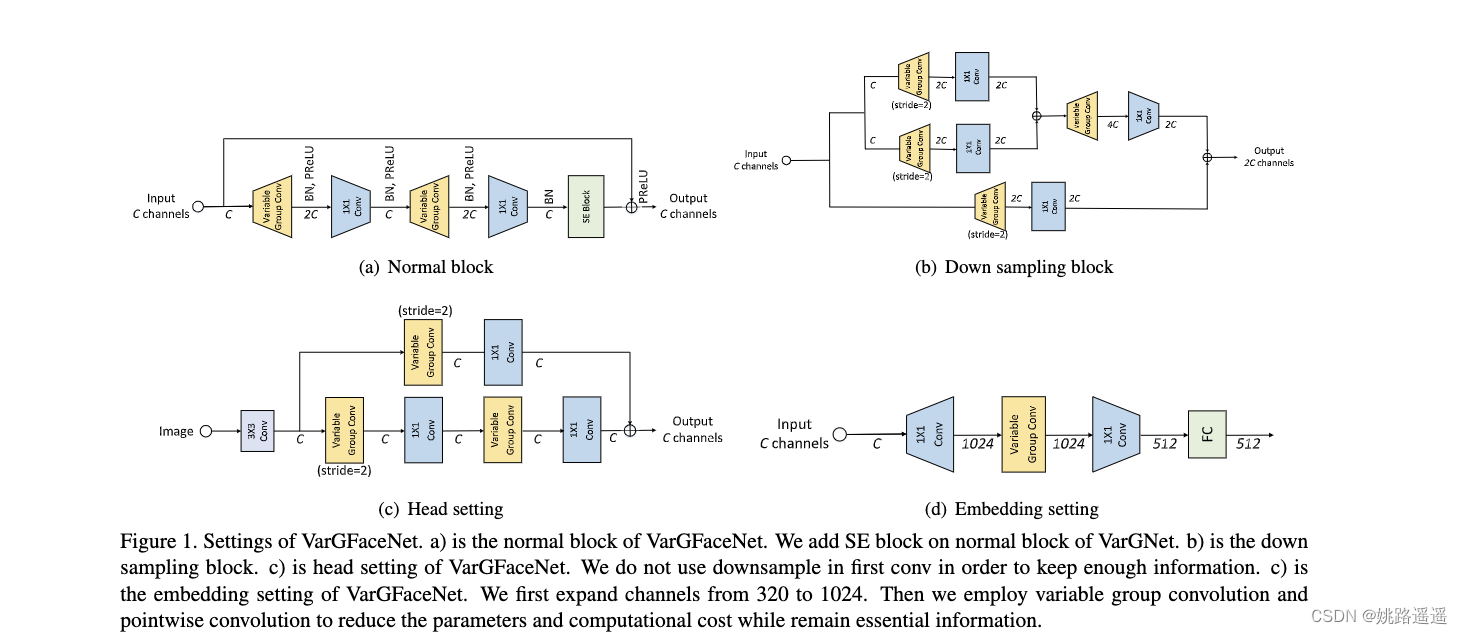
基于VarGNet,作者提出了一种有效的用于轻量级人脸识别的可变组卷积网络,简称VarGFaceNet。为了增强VarGNet对大规模人脸识别任务的判别能力,作者首先在VarGNet的块上添加SE块和PReLU。然后,在网络开始时删除了下采样过程,以保留更多信息。为了减少网络参数,作者用可变组卷积将特征张量缩小到fc层之前的1×1×512。
VarGFaceNet的性能表明,这种设置方法可以保留判别能力,同时减少网络参数。为了增强轻量级网络的解释能力,我们在训练过程中采用了知识蒸馏方法。目前有几种方法可以使深层网络更小,更高效,例如模型修剪,模型量化和知识蒸馏。最近,ShrinkTeaNet 引入了一个角度蒸馏损失来关注教师模型的角度信息。受角度蒸馏损失的启发,作者采用等效损失和更好的实现来指导VarGFaceNet。此外,为了减轻教师模型和学生模型之间优化的复杂性,作者引入了递归知识提炼,它将递归的学生模型视为下一代的预训练模型。
本文贡献如下:
- 为了提高VarGNet在大规模人脸识别中的判别能力,作者采用了不同的头部并提出了一个新的嵌入块。在嵌入块中,作者先通过1×1卷积层将通道扩展到1024,以保留基本信息,然后使用可变组conv和逐点conv将空域缩小到1×1,节省计算成本。如下文所示,这样的操作能提高人脸识别任务的性能。
- 为了提高轻量级模型的泛化能力,作者提出了递归知识蒸馏,以减少教师模型和学生模型之间的泛化差距。
- 作者分析了可变组卷积的性能,并在训练过程中采用了等效的角度蒸馏损失。实验证明了本文方法的有效性。
2.方法
2.1. Variable Group Convolution(可变组卷积)
AlexNet[16]首次引入了组卷积,以减少GPU上的计算成本。然后,在ResNext[23]中,组卷积的基数表现出比深度和宽度维度更好的性能。为移动设备设计的MobileNet[12]和MobileNetV2[21]提出了受组卷积启发的深度可分离卷积,以节省计算成本,同时保持卷积的辨别能力。然而,深度可分离卷积在卷积1×1中花费了95%的计算时间,这导致两个连续层(卷积1×2和卷积DW 3×3)之间存在较大的MAdds间隙[12]。这种差距对加载网络所有权重以执行卷积的嵌入式系统是不友好的[24]:嵌入式系统需要额外的缓冲区用于卷积1×1。为了保持块内计算强度的平衡,VarGNet[26]将组中的通道数设置为常数S。组中的恒定通道数导致卷积中的可变组数n,称为可变组卷积。可变组卷积的计算成本为:

该层的输入为hi x wi x ci,输出为hi x wi x ci+1,k是卷积核大小,当在MobileNet[12]中使用可变组卷积代替深度卷积时,pointwise的计算成本为:
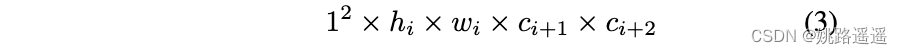
这样可变分组卷积和pointwise卷积的计算开销比例为 k2S / ci+2 ,而depthwise卷积和pointwise卷积的比例为k2 / ci+2。实际上,ci+2 >> k2, S > 1,所以 k2S / ci+2 > k2 / ci+2。因此,在pointwise卷积的基础上使用可变分组卷积而不是depthwise卷积,在块内的计算会更加均衡。S > 1表示与depthwise卷积(核大小相同时)相比,可变分组卷积具有更高的MAdds和更大的网络容量,能够提取更多的信息。
2.2.整体结构
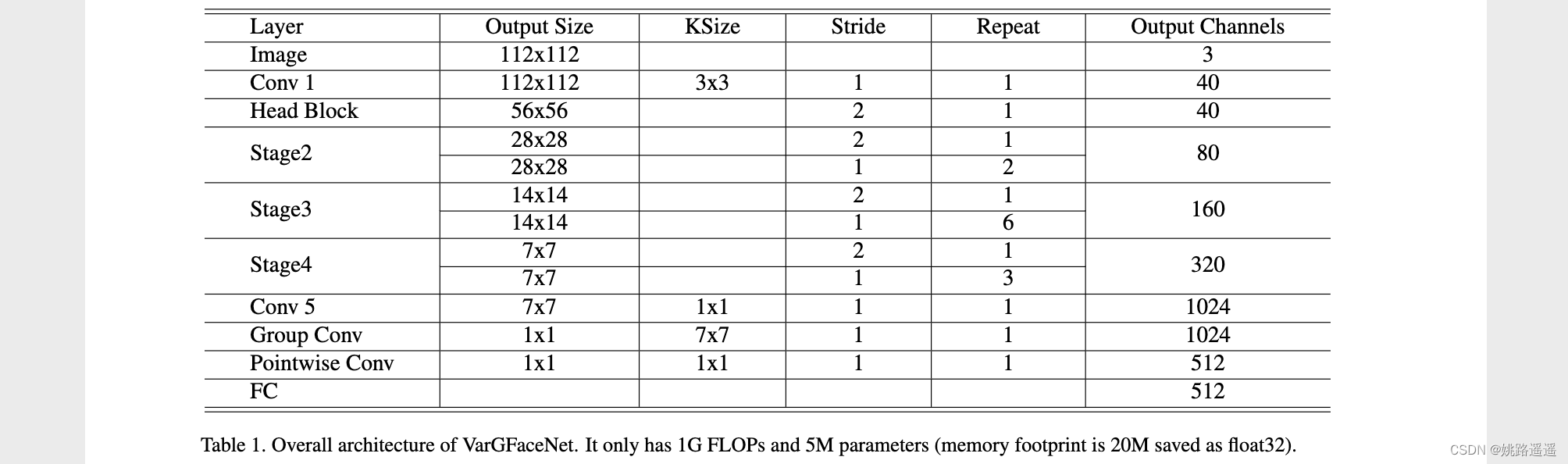
我们的轻量级网络(VarGFaceNet)的总体架构如表1所示。VarGFaceNet的内存占用量为20M,FLOP为1G。我们根据经验在一组中设置S=8。得益于可变组卷积、头部设置和特定的嵌入设置,VarGFaceNet可以以有限的计算成本和参数在人脸识别任务上实现良好的性能。在第3节中,我们将展示我们的网络在一百万个干扰者人脸识别任务中的有效性。
3. 实验


代码
####################################### VarGFaceNet #############################################
from torch.nn import Linear, Conv2d, BatchNorm1d, BatchNorm2d, PReLU, ReLU, Sigmoid, Dropout2d, Dropout, AvgPool2d, \
MaxPool2d, AdaptiveAvgPool2d, Sequential, Module, Parameter
# batchnorm params
bn_mom = 0.9
bn_eps = 2e-5
# use_global_stats = False
# net_setting params
use_se = True
se_ratio = 4
group_base = 8
class Se_block(Module):
def __init__(self, num_filter, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)):
super(Se_block, self).__init__()
self.pool1 = AdaptiveAvgPool2d(1)
# self.pool1 = AvgPool2d(?)
self.conv1 = Conv2d(in_channels=num_filter, out_channels=num_filter // se_ratio, kernel_size=kernel_size,
stride=stride, padding=padding)
self.act1 = PReLU(num_filter // se_ratio)
self.conv2 = Conv2d(in_channels=num_filter // se_ratio, out_channels=num_filter, kernel_size=kernel_size,
stride=stride, padding=padding)
self.act2 = Sigmoid()
def forward(self, x):
temp = x
x = self.pool1(x)
x = self.conv1(x)
x = self.act1(x)
x = self.conv2(x)
x = self.act2(x)
return temp * x
class Separable_Conv2d(Module):
def __init__(self, in_channels, out_channels, kernel_size, padding, stride=(1, 1), factor=1, bias=False,
bn_dw_out=True, act_dw_out=True, bn_pw_out=True, act_pw_out=True, dilation=1):
super(Separable_Conv2d, self).__init__()
assert in_channels % group_base == 0
self.bn_dw_out = bn_dw_out
self.act_dw_out = act_dw_out
self.bn_pw_out = bn_pw_out
self.act_pw_out = act_pw_out
# depthwise
self.dw1 = Conv2d(in_channels=in_channels, out_channels=int(in_channels * factor), kernel_size=kernel_size,
stride=stride, padding=padding, dilation=dilation, groups=int(in_channels / group_base),
bias=bias)
if self.bn_dw_out:
self.dw2 = BatchNorm2d(num_features=int(in_channels * factor), eps=bn_eps, momentum=bn_mom,
track_running_stats=True)
if act_dw_out:
self.dw3 = PReLU(int(in_channels * factor))
# pointwise
self.pw1 = Conv2d(in_channels=int(in_channels * factor), out_channels=out_channels, kernel_size=(1, 1),
stride=(1, 1), padding=(0, 0), groups=1, bias=bias)
if self.bn_pw_out:
self.pw2 = BatchNorm2d(num_features=out_channels, eps=bn_eps, momentum=bn_mom, track_running_stats=True)
if self.act_pw_out:
self.pw3 = PReLU(out_channels)
def forward(self, x):
x = self.dw1(x)
if self.bn_dw_out:
x = self.dw2(x)
if self.act_dw_out:
x = self.dw3(x)
x = self.pw1(x)
if self.bn_pw_out:
x = self.pw2(x)
if self.act_pw_out:
x = self.pw3(x)
return x
class VarGNet_Block(Module):
def __init__(self, n_out_ch1, n_out_ch2, n_out_ch3, factor=2, dim_match=True, multiplier=1, kernel_size=(3, 3),
stride=(1, 1), dilation=1, with_dilate=False):
super(VarGNet_Block, self).__init__()
out_channels_1 = int(n_out_ch1 * multiplier)
out_channels_2 = int(n_out_ch2 * multiplier)
out_channels_3 = int(n_out_ch3 * multiplier)
padding = (((kernel_size[0] - 1) * dilation + 1) // 2, ((kernel_size[1] - 1) * dilation + 1) // 2)
if with_dilate:
stride = (1, 1)
self.dim_match = dim_match
self.shortcut = Separable_Conv2d(in_channels=out_channels_1, out_channels=out_channels_3,
kernel_size=kernel_size, padding=padding, stride=stride, factor=factor,
bias=False, act_pw_out=False, dilation=dilation)
self.sep1 = Separable_Conv2d(in_channels=out_channels_1, out_channels=out_channels_2, kernel_size=kernel_size,
padding=padding, stride=stride, factor=factor, bias=False, dilation=dilation)
self.sep2 = Separable_Conv2d(in_channels=out_channels_2, out_channels=out_channels_3, kernel_size=kernel_size,
padding=padding, stride=(1, 1), factor=factor, bias=False, act_pw_out=False,
dilation=dilation)
self.sep3 = Se_block(num_filter=out_channels_3)
self.sep4 = PReLU(out_channels_3)
def forward(self, x):
if self.dim_match:
short_cut = x
else:
short_cut = self.shortcut(x)
x = self.sep1(x)
x = self.sep2(x)
if use_se:
x = self.sep3(x)
out = x + short_cut
out = self.sep4(out)
return out
class VarGNet_Branch_Merge_Block(Module):
def __init__(self, n_out_ch1, n_out_ch2, n_out_ch3, factor=2, dim_match=False, multiplier=1, kernel_size=(3, 3),
stride=(2, 2), dilation=1, with_dilate=False):
super(VarGNet_Branch_Merge_Block, self).__init__()
out_channels_1 = int(n_out_ch1 * multiplier)
out_channels_2 = int(n_out_ch2 * multiplier)
out_channels_3 = int(n_out_ch3 * multiplier)
padding = (((kernel_size[0] - 1) * dilation + 1) // 2, ((kernel_size[1] - 1) * dilation + 1) // 2)
if with_dilate:
stride = (1, 1)
self.dim_match = dim_match
self.shortcut = Separable_Conv2d(in_channels=out_channels_1, out_channels=out_channels_3,
kernel_size=kernel_size, padding=padding, stride=stride, factor=factor,
bias=False, act_pw_out=False, dilation=dilation)
self.branch1 = Separable_Conv2d(in_channels=out_channels_1, out_channels=out_channels_2,
kernel_size=kernel_size, padding=padding, stride=stride, factor=factor,
bias=False, act_pw_out=False, dilation=dilation)
self.branch2 = Separable_Conv2d(in_channels=out_channels_1, out_channels=out_channels_2,
kernel_size=kernel_size, padding=padding, stride=stride, factor=factor,
bias=False, act_pw_out=False, dilation=dilation)
self.sep1 = PReLU(out_channels_2)
self.sep2 = Separable_Conv2d(in_channels=out_channels_2, out_channels=out_channels_3, kernel_size=kernel_size,
padding=padding, stride=(1, 1), factor=factor, bias=False, act_pw_out=False,
dilation=dilation)
self.sep3 = PReLU(out_channels_3)
def forward(self, x):
if self.dim_match:
short_cut = x
else:
short_cut = self.shortcut(x)
temp1 = self.branch1(x)
temp2 = self.branch2(x)
temp = temp1 + temp2
temp = self.sep1(temp)
temp = self.sep2(temp)
out = temp + short_cut
out = self.sep3(out)
return out
class VarGNet_Conv_Block(Module):
def __init__(self, stage, units, in_channels, out_channels, kernel_size=(3, 3), stride=(2, 2), multiplier=1,
factor=2, dilation=1, with_dilate=False):
super(VarGNet_Conv_Block, self).__init__()
assert stage >= 2, 'Stage is {}, stage must be set >=2'.format(stage)
self.branch_merge = VarGNet_Branch_Merge_Block(n_out_ch1=in_channels, n_out_ch2=out_channels,
n_out_ch3=out_channels, factor=factor, dim_match=False,
multiplier=multiplier, kernel_size=kernel_size, stride=stride,
dilation=dilation, with_dilate=with_dilate)
features = []
for i in range(units - 1):
features.append(
VarGNet_Block(n_out_ch1=out_channels, n_out_ch2=out_channels, n_out_ch3=out_channels, factor=factor,
dim_match=True, multiplier=multiplier, kernel_size=kernel_size, stride=(1, 1),
dilation=dilation, with_dilate=with_dilate))
self.features = Sequential(*features)
def forward(self, x):
x = self.branch_merge(x)
x = self.features(x)
return x
class Head_Block(Module):
def __init__(self, num_filter, multiplier, head_pooling=False, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)):
super(Head_Block, self).__init__()
channels = int(num_filter * multiplier)
self.head_pooling = head_pooling
self.conv1 = Conv2d(in_channels=3, out_channels=channels, kernel_size=kernel_size, stride=stride,
padding=padding, groups=1, bias=False)
# RGB图像包含3个通道(in_channels)
self.bn1 = BatchNorm2d(num_features=channels, eps=bn_eps, momentum=bn_mom, track_running_stats=True)
self.pool = PReLU(channels)
self.head1 = MaxPool2d(kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
self.head2 = VarGNet_Block(n_out_ch1=num_filter, n_out_ch2=num_filter, n_out_ch3=num_filter, factor=1,
dim_match=False, multiplier=multiplier, kernel_size=kernel_size, stride=(2, 2),
dilation=1, with_dilate=False)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.pool(x)
if self.head_pooling:
x = self.head1(x)
else:
x = self.head2(x)
return x
class Embedding_Block(Module):
def __init__(self, input_channels, last_channels, emb_size, bias=False):
super(Embedding_Block, self).__init__()
self.input_channels = input_channels
self.last_channels = last_channels
# last channels(0, optional)
self.conv0 = Conv2d(in_channels=input_channels, out_channels=last_channels, kernel_size=(1, 1), stride=(1, 1),
padding=(0, 0), bias=bias)
self.bn0 = BatchNorm2d(num_features=last_channels, eps=bn_eps, momentum=bn_mom, track_running_stats=True)
self.pool0 = PReLU(last_channels)
# depthwise(1),输入为224*224时,可将kernel_size改为(14, 14)
self.conv1 = Conv2d(in_channels=last_channels, out_channels=last_channels, kernel_size=(7, 7), stride=(1, 1),
padding=(0, 0), groups=int(last_channels / group_base), bias=bias)
self.bn1 = BatchNorm2d(num_features=last_channels, eps=bn_eps, momentum=bn_mom, track_running_stats=True)
# pointwise(2)
self.conv2 = Conv2d(in_channels=last_channels, out_channels=last_channels // 2, kernel_size=(1, 1),
stride=(1, 1), padding=(0, 0), bias=bias)
self.bn2 = BatchNorm2d(num_features=last_channels // 2, eps=bn_eps, momentum=bn_mom, track_running_stats=True)
self.pool2 = PReLU(last_channels // 2)
# FC
self.fc = Linear(in_features=last_channels // 2, out_features=emb_size, bias=False)
self.bn = BatchNorm1d(num_features=emb_size, eps=bn_eps, momentum=bn_mom, track_running_stats=True)
def forward(self, x):
if self.input_channels != self.last_channels:
x = self.conv0(x)
x = self.bn0(x)
x = self.pool0(x)
x = self.conv1(x)
x = self.bn1(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.pool2(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
x = self.bn(x)
return x
class VarGFaceNet(Module):
def __init__(self, emb_size):
super(VarGFaceNet, self).__init__()
self.emb_size = emb_size
multiplier = 1.25
factor = 2
head_pooling = False
num_stage = 3
stage_list = [2, 3, 4]
units = [3, 7, 4]
filter_list = [32, 64, 128, 256]
last_channels = 1024
dilation_list = [1, 1, 1]
with_dilate_list = [False, False, False]
self.head = Head_Block(num_filter=filter_list[0], multiplier=multiplier, head_pooling=head_pooling,
kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
body = []
for i in range(num_stage):
body.append(VarGNet_Conv_Block(stage=stage_list[i], units=units[i], in_channels=filter_list[i],
out_channels=filter_list[i + 1], kernel_size=(3, 3), stride=(2, 2),
multiplier=multiplier, factor=factor, dilation=dilation_list[i],
with_dilate=with_dilate_list[i]))
self.body = Sequential(*body)
self.emb = Embedding_Block(input_channels=int(filter_list[3] * multiplier), last_channels=last_channels,
emb_size=self.emb_size, bias=False) # 源代码的input_channels缺少*multiplier,无法运行
'''
# initialization
for m in self.modules(): # 借用MobileNetV3的初始化方法
if isinstance(m, Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, (BatchNorm1d, BatchNorm2d)):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.zeros_(m.bias)
'''
def forward(self, x):
x = self.head(x)
x = self.body(x)
x = self.emb(x)
return x