2017年6月我在MSRA实习的时候,在微软内部的Talk上听过MSRA主管研究员秦涛博士讲过一篇他们团队在2016年顶会NIPS上发表的最新成果《LightRNN: Memory and Computation-Efficient Recurrent Neural Networks》。期间也有幸面对面向秦老师请教了一些论文里的问题,感觉确确实实学到了不少的东西,故写博客记录一下。
之所以叫做LightRNN,是因为这种语言模型相对于传统的语言模型来说,拥有更小的模型容量和更高的计算速度。传统的语言模型在进行词向量表征的时候使用的都是相互没有关联的独立的词向量,但是在这篇paper中一个词语将对应一个行向量和一个列向量,其中一些词语会共享行向量和列向量,具体的方式如下图所示:
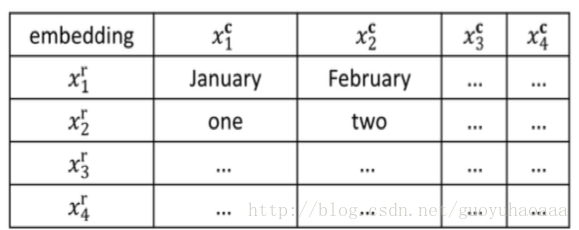
行向量和列向量分布对应矩阵的行和列,其中矩阵中的元素就是目标词语。这样如果词典中词语的个数为|v|,传统的方法就要生成v个与之对应的词向量,但是在LightRNN中则只需要
下面就来详细介绍一下这种基于RNN架构的轻量级语言模型,其整体的架构如下所示:
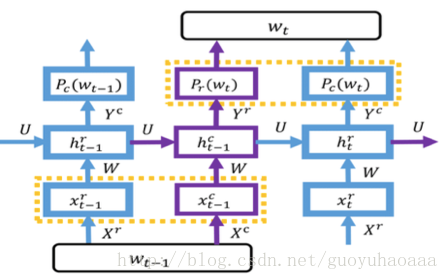
从图中可以看出模型一共包含了2种RNN网络(紫色和蓝色),分别用来处理列向量信息和行向量信息,同时通过隐藏层变量
step 1:
step 2:
(PS:公式中的r和c上标分布代表了row和column)
从步骤可以看出,在计算
之所以采用看上去这么奇怪的方式交杂在一起,是因为一个词语完整的语义必须由其行向量和列向量共同去表征,因此想办法联合计算在一起,不能单独对行向量和列向量进行处理。
在进行预测的时候,
需要注意的是,在上述公式中,预测
其实到了这里,LightRNN模型已经介绍完了。但是其中还是有一个比较重要的地方需要注意。就是那些共享了行向量和列向量的词语,从理论上讲应该是具有一定的相关性。但是在基础的模型中,矩阵中的词语是随机分配的,这样显然是不合理的,模型对这种情况采用了一种非常巧妙的迭代式的方式,称之为Bootstrap算法。
其整体思想是:
1 刚开始将词语随机分配在矩阵中,然后根据LightRNN语言模型进行调优;
2 固定矩阵中的行列向量,调整词语的位置,进一步优化损失函数;
3 重复1 2,直到算法达到停止条件(一般会有一个预先设定的迭代次数)。
可以看出在上述过程中,最关键的是步骤2,即如何重新调整矩阵中词语位置:
首先整个模型的损失函数如下所示:
如果按照从词语的维度再来看这个损失函数,就变成了如下所示:
也就是说,如果固定矩阵的行向量和列向量,只是改变矩阵内部词语的位置,我们可以根据上面的式子算出每一个词语重新被分配到就在任意一个位置上在全体corpus里的损失值,这样问题就被转化成了一个新的问题,就是最小流最大费用问题(MCMF),针对该问题业界已经有了非常成熟的解决方案,我们可以排列所有词语在矩阵中的相对位置,如下图所示:
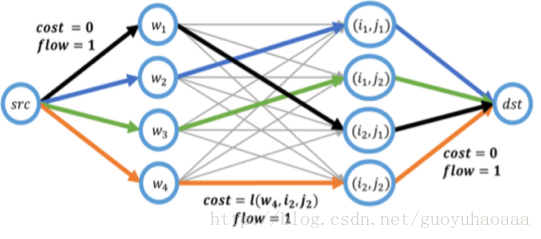
其中(i,j)标识了矩阵中的位置下标。
这样我们就完成了第一次的迭代任务。接下来,重新按照分配好的行列向量,重新按照LightRNN的损失函数调整向量,然后再继续重新调整位置信息,一直重复知道停止。
作者是用PPL(perplexity)来衡量语言模型的复杂度,
同时作者意外的发现,经过Bootstrap迭代式优化过程之后,一些词性上相似的词语会被自动的调整到相同的行和列中去,如下所示:
